参考论文:OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
原文地址:https://arxiv.org/abs/1611.08050
源码地址:https://github.com/CMU-Perceptual-Computing-Lab/openpose
主要方法:
使用非参数表示的方法,我们称之为部分亲和域【PAFs】,用它来学习怎么将身体部分和图像中的个体联系起来。
自下而上
算法流程:

整个检测过程如上图所示,输入一幅图像,然后经过7个stage,得到PCM和PAF。然后根据PAF生成一系列的偶匹配,由于PAF自身的矢量性,使得生成的偶匹配很正确,最终合并为一个人的整体骨架。
网络结构:

a.经过VGG-19的前10层网络得到一个特征度F
b.网络分成两个循环分支,一个分支用于预测置信图S:关键点(人体关节),一个分支用于预测L:像素点在骨架中的走向(肢体),第一个循环分支以特征图F作为输入,得到一组S1,L1(S1=ρ1(F),L1=φ1(F))
c.之后的分支分别以上一个分支的输出St-1,Lt-1和特征图F作为输入,最终输出S,L

PAFs是用来描述像素点在骨架中的走向,用L(p)表示;关键点的响应用S(p)表示。先看主体网络结构,图像首先被一个卷积神经网络处理后生成特征图集F(通过VGG-19的前10层进行初始化并微调)网络采用VGG pre-train network作为骨架,有两个分支分别回归L(p)和S(p)。每一个stage算一次loss,之后把L和S以及原始输入concatenate,继续下一个stage的训练。随着迭代次数的增加,S能够一定程度上区分结构的左右。loss用的L2范数,S和L的ground-truth需要从标注的关键点生成,如果某个关键点在标注中有缺失则不计算该点。记为F,经过如图所示的网络,该网络分上下两个分支,每个分支都有t个阶段(表示越来越精细),每个阶段都会将feature maps进行融合。其中ρ φ 表示网络。
d.损失函数计算S,L的预测值与groundtruth(S*,L*)之间的L2范数
S和L的groundtruth根据标注的2D点计算,如果某个关键点标注缺失则不计算该点

损失函数为每一层循环网络的损失函数之和:
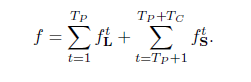
置信图生成Confidence Maps for Part Detection:
理想情况下,如果图像中有一个人,那么在对应的 部分可见的情况下,在每个置信图中都应该存在一个 单峰;如果图中有多个人,那么对于每个人 k 的每个可见部分 j 都应该有一个峰。首先给出每一个人k的单个confidence maps, xj,k∈R2xj,k∈R2表示图像中人k对应的位置j对应的groundtruth position:
,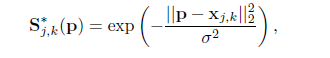
其中σ用来控制峰值在confidence map中的传播范围。
对应多个人的confidence map:
![]()
部分亲和字段Part Affinity Fields for Part Association:
我们需要为每一对人体部分探测的相关性进行置信测量,即他们是否属于同一个人。因此提出了一个 新的特征表示【即部分亲和域字段,它保存了 肢体的支持区域中的位置和方向信息。部分亲和是每一个肢体的二维向量域:对于属于 每个肢体(指手臂,或腿,或躯干)的区域中的每个像素,二维向量编码了从肢体上的一个 部分指向另一个 部分的方向。每一种肢体都有对应的亲和域来联系起它们身体部分。
考虑下图中给出的一个躯干(手臂),令Xj1,kXj1,k和xj2,kxj2,k表示图中的某个人k的两个关键点j1j1和j2j2对应的真实像素点,如果一个像素点p位于这个躯干上,值L∗c,k(p)Lc,k∗(p)表示一个从关键点j1j1到关键点j2j2的单位向量,对于不在躯干上的像素点对应的向量则是零向量。下面这个公式给出了the groundtruth part affinity vector,对于图像中的一个点p其值L∗c,k(p)Lc,k∗(p)的值如下:
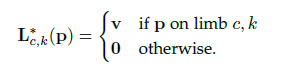
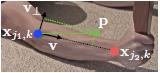
其中像素P是否落在肢体上需要满足两个条件:
![]()
每张图像中第c中肢体的Lc*,为k个人在位置p的向量平均值:
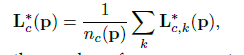
测试阶段,我们用候选关键点对之间的PAF来衡量这个关键点对是不是属于同一个人。具体地,对于两个候选关键点对应的像素点dj1dj1和dj2dj2,我们去计算这个PAF,:

其中,p(u)表示两个像素点dj1dj1和dj2dj2之间的像素点:
![]()
PAFs 多人分析Multi-Person Parsing using PAFs:
作者提出了一种贪婪的简化方法,能够始终产生高质量的匹配。推测原因是成对关联分数隐含地编码了全局上下文,这是由于 PAFPAFPAF 网络的感受野很大
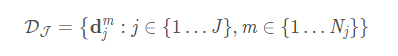
二部图中的匹配是以没有两条边共享一个结点的方式选择的边的子集。优化的目标是为选定的边找到最大权重的匹配:

通过 HungarianHungarianHungarian 算法获取最优匹配。
当涉及到寻找多人的全身姿态时,确定 Z是一个 K 维匹配问题。这个问题是 NP难并且有许多松弛存在。作者为优化添加两个松弛。选择最小数量的边来获得人体姿态的生成树骨架,而不是使用完整的图。进一步将匹配问题分解成一组二部匹配子问题,并独立地确定相邻树节点中的匹配。优化可以被简化为:
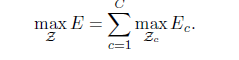
Results:
测试了本文提出的方法在几种数据集上的性能。