一、研究背景
维基百科对人体姿态估计的定义如下:
Articulated body pose estimation in computer vision is the study of algorithms and systems that recover the pose of an articulated body, which consists of joints and rigid parts using image-based observations.
Human Keypoint Detecting requires localization of person keypoints in challenging, uncontrolled conditions. The keypoint challenge involves simultaneously detecting people and localizing their keypoints (person locations are not given at test time).
简言之,任务就是基于图像重建人的关节和肢干。难点主要在于降低模型分析算法的复杂程度,并能够适应各种多变的情况。
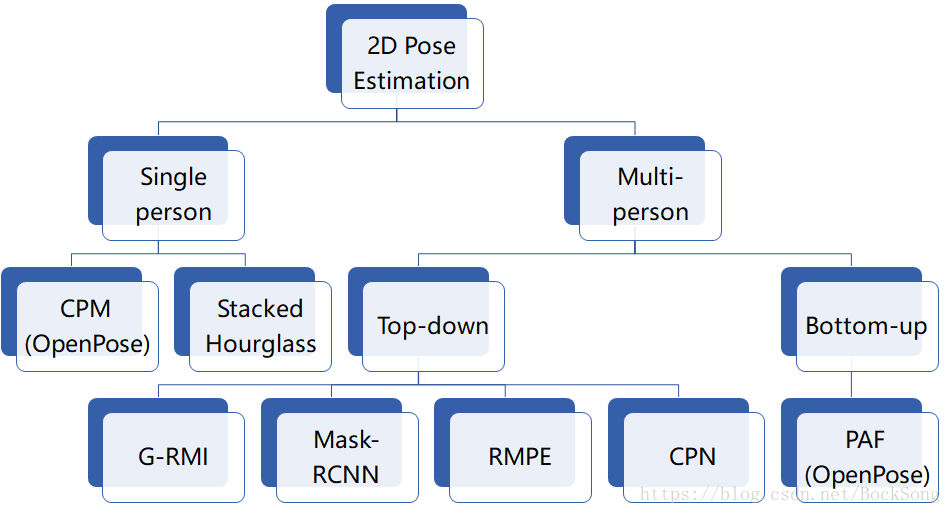
二、2D姿态估计方法分类概览
两种思路
自底向上:Bottomup,先catch所有关节,再关联人
自顶向下:Topdown,先检测人的bounding box,再用single的方法检测每个人
下文从传统方法开始,讲解相关研究。
三、Classical Approach
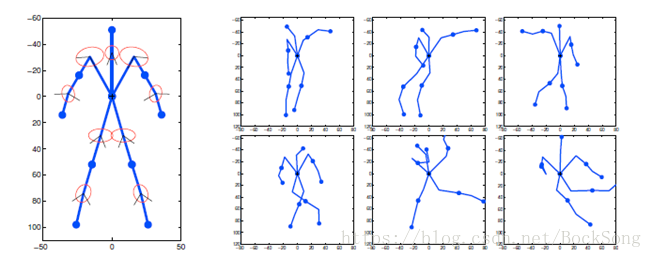
这种方法将关节结构用带有动力学先验的树状图模型来表达。将身体关节划分为多个部分,躯干、头、左臂上、下,右臂上、下 (如果考虑全身则还有左腿上、下,右腿上、下)。将躯干指定为root,向各个部位扩展。各部位间服从高斯分布。问题在于不能解决遮挡问题。
四、CNN-based Method
1、DeepPose
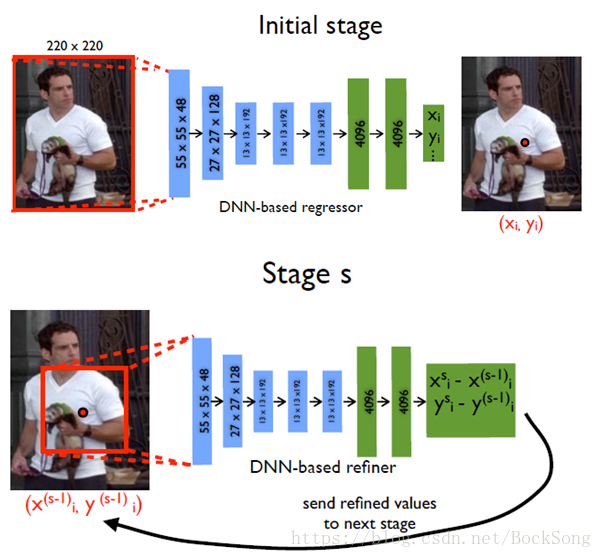
最早应用CNN的方法,直接回归关节坐标,multi-stage refine回归出的坐标。蓝色是卷积层,绿色是全连接层。
2、Flowing ConvNets
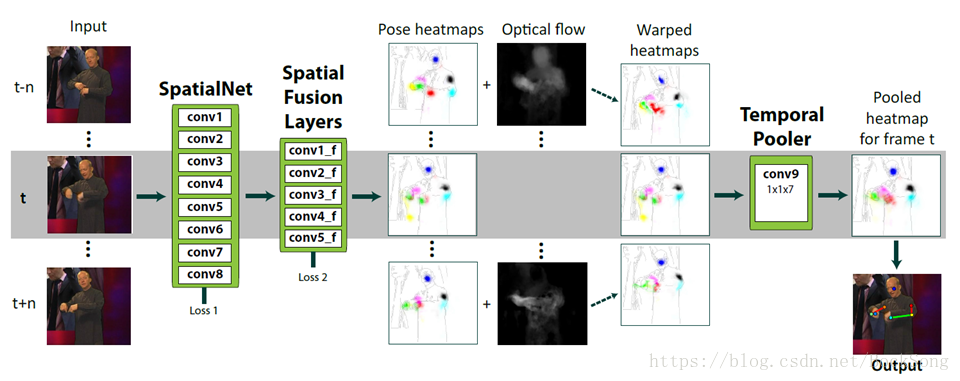
对于当前帧t及相邻的前后n帧使用全卷积网络为每帧输出一个预测的heatmap(去掉FC层),再用光流信息将这些heatmap扭曲到当前帧t。之后将warped的heatmap合并到另一个卷积层中,权衡来自附近框架的扭曲的heatmap。最后使用集合热图的最大值作为关节点。
对于视频流来说,info通常包括:appearance,当前帧+前一帧的关联信息,Structure。关键是利用图像序列和逐帧的信息
3、CPM(convolution pose machine)
能够解决一些遮挡和不可见问题;结合了multi-stage和refine heatmap的思想。网络结构如下:
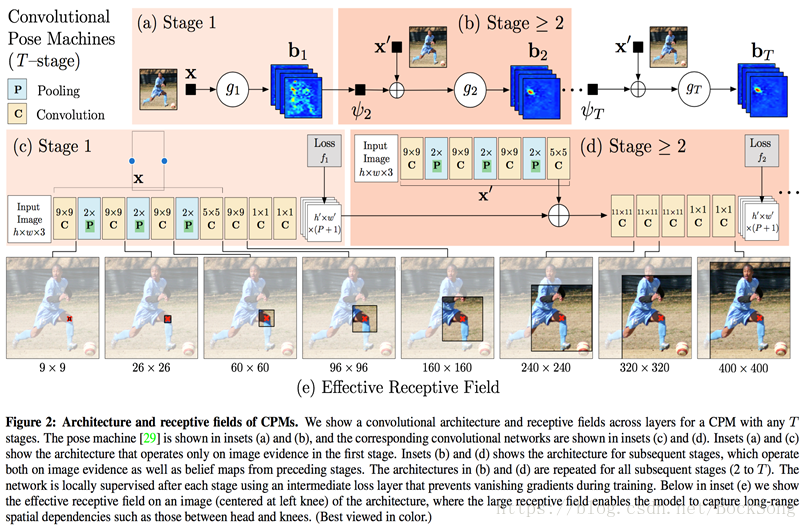
Stage1只利用了local evidence(因为感受野和输出范围大小相近)
Stage>=2使用前一阶段的置信计算结果作为输入。
每个stage由全卷积网络预测每个part的;结果不断refine并累加到之前部件的响应图上。最后取每个部件图中置信度最大的点作为部件位置。
4、stacked hourglass
hourglass卷积网络结构有多个平行的预测分支, 网络结构中包含卷积层、解卷积层. 这样复杂的模型具有高度的灵活性, 在描述复杂结构方面表现出色. 而由于卷积层和解卷积层引起的空间连续性, 其对大光滑表面更友好. 而网络反复进行的编解码操作, 使该方法具有更强的表示能力, 可以更好的混合全局和局部信息.
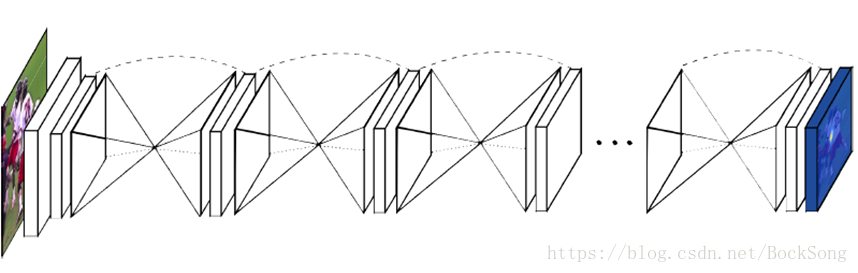
重复进行top-down到bottom-up的过程来推断关节位置,构成每个stacked hourglass模块。
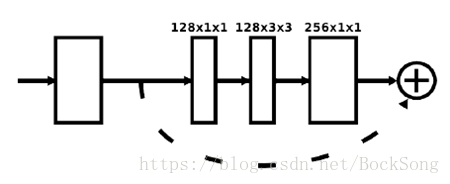
Residual子模块:只增加深度(通道数),不增加宽度(尺寸)

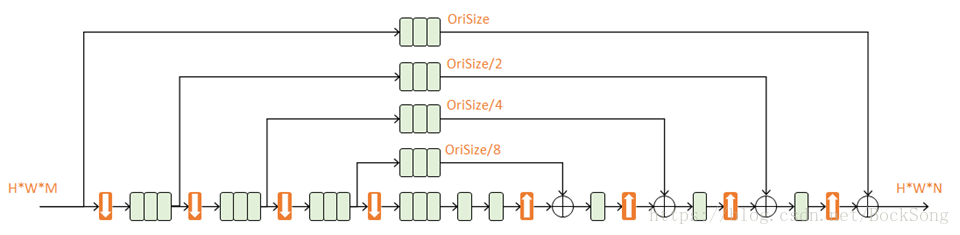
每次降采样之前,分出上半路保留原尺度信息; 每次升采样之后,和上一个尺度的数据相加; 两次降采样之间,使用三个Residual模块提取特征; 两次相加之间,使用一个Residual模块提取特征。n阶Hourglass子网络提取了从原始尺度到1/2n尺度的特征。不改变尺寸只改变深度。由于不需要像CPM一样独立地在图像金字塔上多次运行,速度更快。
(从本方法开始是多人检测)5、PAF(Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields)
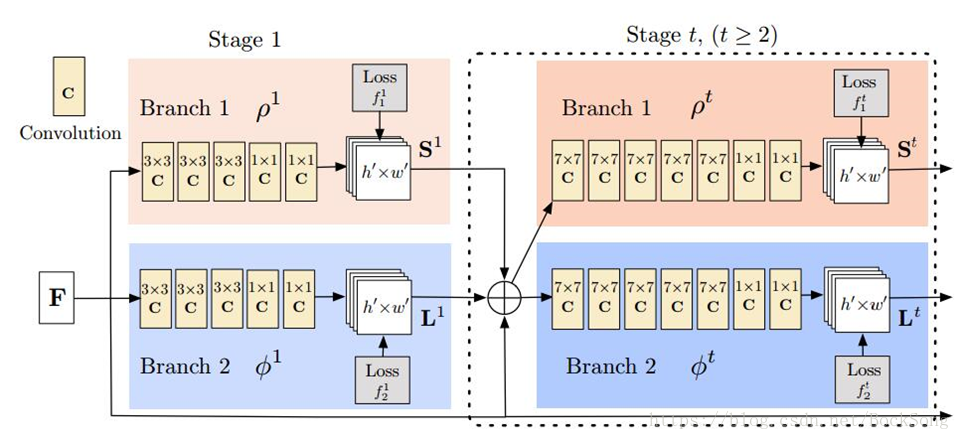
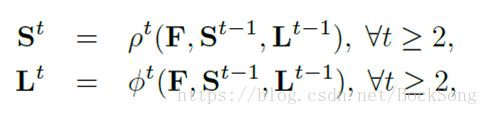
Branch1:计算置信图(CPM)
Branch2:计算亲和度PAF
一开始由VGG19生成feature map。每个stage结束后对该阶段的置信值,PAF图和一开始得到的Feature maps作concat分别作为下一阶段两个branches的输入。公式中,S为置信图,L为PAF,F是feature map. 原文自己说低分辨率和有遮挡时效果不够理想。
对关键点分组阶段,往往转换成图中的节点聚类问题,采用数学方法解决。如NMS,匈牙利算法
6、Mask R-CNN
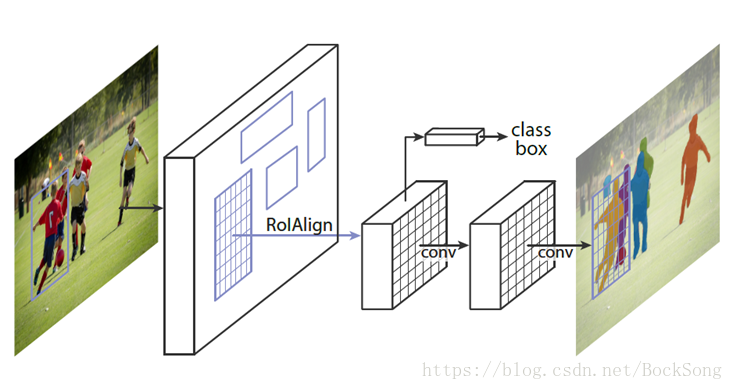
Faster R-CNN的基础上又加入了全连接的分割子网络,完成三个任务(检测+分类+分割)。mask R-CNN有两条并行的分支,第一个分支是使用faster R-CNN的基础结构,对候选bounding box进行分类和bounding box坐标回归。第二个分支是对每一个RoI区域预测分割mask,结构上是一个小的FCN。
7、G-RMI
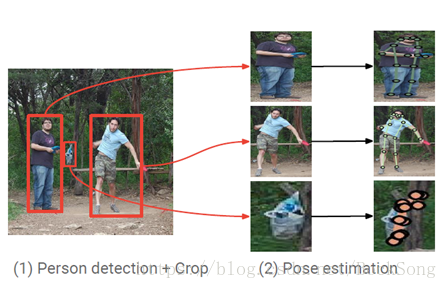
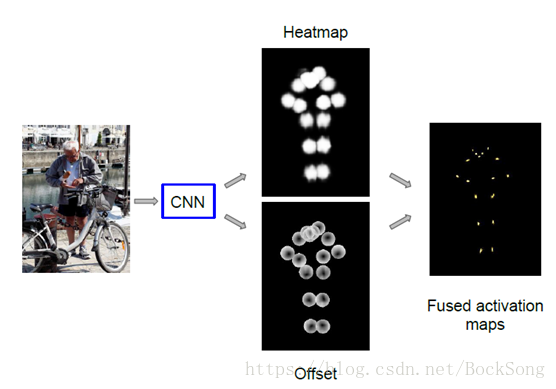
第一阶段使用faster rcnn做detection,检测出图片中的多个人,并对bounding box进行image crop; 第二阶段采用fully convolutional resnet对每一个bonding box中的人物预测dense heatmap和offset; 最后通过heatmap和offset的融合得到关键点的精确定位 (如下)。
8、RMPE(现已更新到新版本AlphaPose,效果拔群)

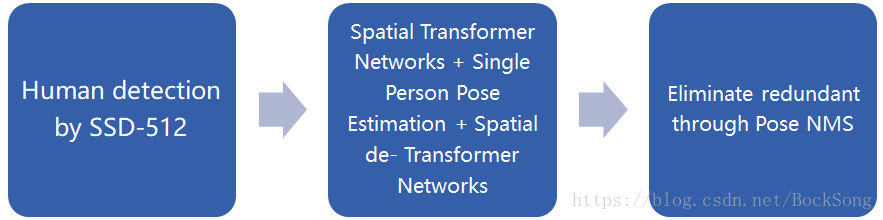
识别姿态使用Stacked Hourglass. 致力于解决对于imperfect proposal,使得crop的person能够被单人姿态估计方法很好的识别,从而克服检测带来的定位误差。第一步获得human proposal第二步是将proposal输入到两个并行的分支里面,上面的分支是STN+SPPE+SDTN的结构,STN接收的是human proposal,SDTN产生的是pose proposal。下面并行的分支充当额外的正则化矫正器。第三步是对pose proposal做Pose NMS(非最大值抑制),用来消除冗余的pose proposal。
9、Associative Embedding
论文特色:A single-stage,end-to-end way for joint detection and grouping.
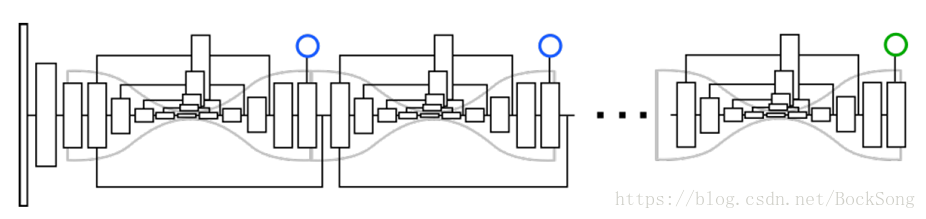
关节点检测使用stacked hourglass,在原来的基础上每一次下采样时增加输出通道的个数,同时individual layers的残差模型改为3*3的卷积结构,其他结构不变。
关节点分组:使用stacked hourglass网络的输出是对每一个pixel预测detection score,从单人到多人的姿态估计就是将heatmap由单个点的激活,到多个点的激活,从而检测出多个关节点。输出是heatmap,用于对每一个pixel打上标签,标签相近的关节点认为是属于同一个人的,这样完成对关节点的分类。如果有m个关节点,就会有2m个通道,其中m个用于检测,m个用于分组标签。
10、CPN(18cvpr,state-of-the-art)
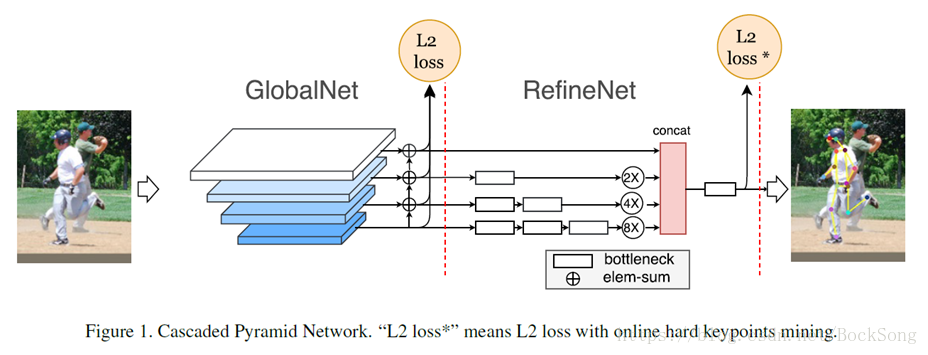
仍然是topdown思路,第一个stage检测可见的easy keypoint,第二个stage专门解决hard keypoint。代码:https://github.com/chenyilun95/tf-cpn
更多CVPR2018中的新方法见:https://blog.csdn.net/bocksong/article/details/80899689
五、实验效果
待补充。