参见
- 论文翻译 || openpose _magic_ll的博客-CSDN博客
- OpenPose论文解读—- 知乎
- Openpose论文阅读 _jmucvm的博客-CSDN博客
- openpose论文总结:_htt789的博客-CSDN博客
- OpenPifPaf: encoder过程_MatthewHsw的博客-CSDN博客_openpifpaf
- 第3课 人体骨骼点检测:自底向上_哔哩哔哩_bilibili
https://blog.csdn.net/Murdock_C/article/details/94013116
openpose
实时多人人体姿态识别:Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields_哔哩哔哩_bilibili
我们提出了一种有效检测多人图像中的2D姿势的方法。 该方法使用非参数表示,我们称之为部分亲和场(PAF),用于学习将图像中的身体部位与个体联系起来。 该体系结构编码全局上下文,允许贪婪的自下而上解析步骤,无论图像中的人数多少,同时实现高精度和实时性能。 架构旨在将学习关节点和关节点之间的连接融合起来,通过相同顺序的两个分支进行关联预测。
一些简单的名词解释
GT groundtruth 真实值
limb 肢体,也就是胳膊、腿、脖子、身体等
PAF 部分亲和域(场) 文章提出的一种方法
一、 Introduction
人体2D姿势估计 - 本地化的问题解剖学关键点或“部分” - 主要集中于找到个体的身体部位[8,4,3,21,33,13,25,31,6,24].特别是在图像中推断出多个人的姿势,呈现出一套独特的风格挑战。 首先,每个图像可能包含可以在任何位置或规模发生未知 数量的人。其次,人与人之间的互动导致复杂的空间干扰,由于接触,闭塞和肢体关节,使部件关联变得困难。 第三,运行时随着人口数量的增加,复杂性趋于增长,使实时性能成为一项挑战。

Figure 1.顶部:多人姿势估计。 同一个人的身体部位之间用线相连。 左下:部分亲和力字段(PAFs)对应于连接右肘和右侧的肢体腕。 颜色编码方向。 右下:放大预测的PAF的视图。 在场中的每个像素处,2D矢量编码四肢的位置和方向。
采用一种常见的方法[23,9,27,12,19]人检测器并执行单人姿势估计对于每次检测。 这些自上而下的方法直接利用现有技术进行单人姿势估计[17,11,18,28,29,7,30,5,6,20],但受苦从早期承诺:如果人员检测器失败 - 因为它当人们近在咫尺时很容易检测不出来,这种情况无法检测。 而且,这些自上而下方法的运行时间与人数成正比:对于每次检测,人数越多,单人姿势估计器计算量成本越大。相比之下,自下而上的方法很有吸引力,因为它们为早期承诺提供了稳健性并且拥有将运行时复杂性与图像中的人数之间关系分离。然而,自下而上的方法却没有直接使用来自其他身体部位和其他人的全局上下文线索。在实践中,以前的自下而上的方法[22,11]不会保留效率的提升,以至于最终的解析需要昂贵的全局推理。例如,Pishchulin等人的开创性工作。 [22]提出了自下而上的建议:联合标记部分检测候选者的方法将它们与个人联系起来。但是,在一个完全连接的图上解决整数线性规划问题一个NP问题和平均处理时间大约是几个小时。 Insafutdinov等。 [11]建成[22]基于ResNet的更强部分探测器[10]和图像相关的成对分数,并大大改善运行时,但该方法在限制部分提案的数量的情况下处理一张图片仍然需要几分钟。[11]中使用的成对表示很难回归,因此,需要一个单独的逻辑回归。

Figure 2.整体过程。 我们将整个图像作为双分支CNN的输入来联合预测置信图,(b)中所示的身体部位检测,以及(c)中所示的部位关联的部分亲和力字段。 解析步骤执行一组二分匹配身体部位候选人的匹配(d)。 我们最终将它们组装成图像中所有人的全身姿势(e)。
在本文中,我们首次提出一种自下而上描述关联分数的方法:Part Affinity Fields(PAF),PAF是一组对位置和图像上肢体的方向进行编码的2D矢量场。 我们证明同时推断这些自下而上的检测和关联表示足以很好地编码全局上下文,以一小部分计算成本获得高质量的结果。我们公开发布了完全可重复性的代码,呈现 第一个用于多人2D姿势检测的实时系统。
1.1动机
作者其实就是想结合他们之前做的CPM来做一个bottom-up的姿态估计算法,这样就可能又快又好。
1.2思想
(1)以bottom-up的方式把多人姿态估计问题表示为 检测所有关键点+关键点连接(2)使用全卷积的方式来提取特征,整个网络包含两个平行分支: 分支1 与CPM的第一阶段一样预测所有人的所有关键点的heatmaps w×h×(J×1),J表示关键点个数,也就是说,有 J 个身体部位; 分支2检测关键点之间的连线,在文中定义为亲和场(affinity fields)(所谓的PAFs其实也是个类似heatmap的东西,表示关键点之间连接部分中每个像素点所处肢体的单位方向向量(2维的),整个PAFs的形状为w×h×(C×2),其中C是肢体的个数,一共有 C 个连接。(3)和CPM类似,整个网络仍然是多阶段地不断细化预测结果,并在每个阶段使用中间监督。
得到所有关键点和所有的连接后,便将其concat起来,最后输出就成为了一个完整的人体骨架
二、Method
Figure 2说明了我们方法的整个流水线。 该系统采用尺寸为w×h的彩色图像作为输入(Fig.2a),并且为图像中的每个人产生解剖关键点的2D位置作为输出(Fig.2e)。
1、首先,前向网络同时预测一组身体部位位置的2D置信度图(confidence map)S(Fig.2b)和编码一组身体部分之间关联程度(亲和度)的2D矢量场L(图2c)。
2、集合具有J个置信图(J个关键点),每个部分一个置信图,其中
。
3、集合具有C个矢量场(C个关键点之间的连接(关键点对)),其中
,Lc中的每个图像位置编码2D矢量(如Fig.1所示)。 Lc代表肢体或者脸部的一个部分(如胳膊等),Lc的值具体计算参见后面。
4、最后,通过贪心推理(Fig.2d)解析置信度图和亲和场,以输出图像中所有人的2D关键点。
2.1 Simultaneous Detection and Association
我们的架构 Fig.3所示,同时预测检测编码的置信度图和亲和场(关键点之间的连接)。 网络分为两部分分支:以米色显示的顶部分支预测置信度图和以蓝色显示的底部分支预测亲和场。每个分支都是一个迭代预测架构。在Wei等人的基础上改进了连续阶段的预测,Wei等人采取的是,每个阶段要用中间监督。

Figure 3.双分支多级CNN的体系结构。 每第一个分支中的阶段预测置信度图 ,每一个
第二个分支中的阶段预测PAFs。 每个阶段之后,来自两个分支的预测,以及图像特征,进行连接进入下一阶段。
首先通过卷积网络VGG-19前10层 处理后,生成一组特征映射(feature maps)F 作为每个分支的第一阶段的输入。
在第一阶段
,
其中和
是第1阶段推断的CNN。
在随后的每一个阶段中,来自前两个分支阶段的预测结果,以及原始图像特征F,是连接并用于产生更精确的预测。
和
是第t阶段的CNN。
图4显示了各阶段置信图和亲和场的优化。
为了引导神经网络以迭代方式在分支一预测身体部位的置信度图和在第二个分支预测PAF,我们在每个阶段结束时应用了两个损失函数,每个分支一个。我们在估计的预测值和真实的关节图,关节连接之间使用L2损失。 在这里,我们在空间上对损失函数进行加权,以解决一些实际问题,即某些数据集并未完全标记所有人。
为了清晰起见,我们将部件(part)对称为肢体(limb),尽管有些对不是人的肢体(例如,脸)。

Figure 4.各个阶段的右手腕(第一排)和PAF的置信度图(第二排)右前臂。 虽然在早期阶段左右身体部位和四肢之间经常会混乱,但是通过后期阶段的全面推理,预测越来越精确,如图中高亮区域所示。
特别地,第t阶段的两个损失函数如下:
(3)
(4)
是真实的身体部位置信图
是真实的身体关节连接向量,W是一个二进制位,当这个关节p并没有在图像上显示的时候,W = 0。W参数的目的是避免在训练过程中惩罚真实情况的预测。每个阶段的中间监督是通过周期性的调整梯度来解决梯度消失问题,总体的表示如下:
(5)
2.2. Confidence Maps for Part Detection
这里介绍一下confidence maps 的GT是怎么来的,也就是标注的过程。
首先,当我们检测到第 k 个人的部位 j 时,在这里,我们使用高斯分布,越接近真实的 j ,那么得到的结果也就越大,由于如上面的二维图所示,当然,出现多个人后,就会有多个峰值(比如正常情况下,俩人的话,就有两个左手,在这里就有两个峰值)。由于图像是二维的,就会得到类似上面这种热力图,但是这个图是我在网上随便找的!!仅仅是示意图,在我们实际检测中不是这样的。
实际的二维图像应该是一个个峰值相同(这个说法存疑,论文没说)的突起,因为肯定都是在最高处为GT。
得到所有人的所有部位的GT后,取最大值。(因为所有最大值都相同,这里不会漏人)
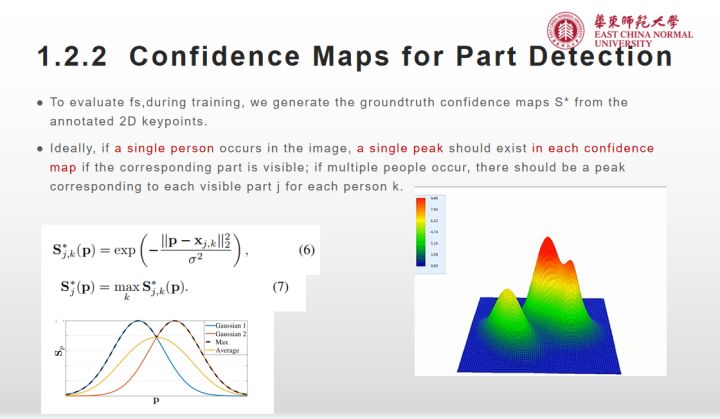
关键点的标注和CPM以及其他论文的一样都是关键点的高斯撒点;如下公式6所示
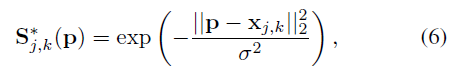
实际上就是使用2D高斯分布建模,求出一张图像上身体j部位的heatmap,记第k个人的第j个关节的heatmap为
(高斯分布),
表示位置信息,则有:
(7)
σ控制置信图峰的范围。网络要预测的真实的置信图是独立的置信图通过取最大运算得到的聚合。
我们取置信图中最大的部分而不是取平均,使得靠近峰值的预测会很明显,就像上图所示。在测试的时候,我们预测置信图(在Figure 4.中的第一行),通过非最大值抑制得到身体部位的候选。
2.3. Part Affinity Fields for Part Association
给出一组检测出来的 人体部分【body parts】(如图 5a 中的红点和蓝点),在人的数量未知的情况下,我们要怎么组合他们【指检测出来的人体部分】来形成一个 全身姿势【full-body poses】呢?我们需要为每一对 人体部分探测【body part detections】的相关性【association】进行置信测量【confidence measure】,即 他们【指检测出来的人体部分】是否属于同一个人。一种可行的检测其相关性的方法是,在每一对处在 同一肢体上的部分【parts on a limb】之间 检测【detect】出一个额外的 中间点【midpoint】,然后检查它们在 候选部分探测【candidate part detections】之间的 关联【incident,这个意思不知道怎么翻译】,如图 5b。可是,当人们聚集到一起时,(人很容易会聚集到一起),这些中点很可能会支持了 错误的关联【false association】。(如图 5b 中的绿线所示)。这种 错误关联【false association】的出现时由于表示的两个限制【two limitationsin the representation】:(1)它只为每个 肢体【limb】编码了位置,却没有编码方向;(2)它减少了 肢体【limb】对于一个单点的支持区域。
为了解决这些限制,我们提出了一个 新的特征表示【novel feature representation】,即部件亲和场【part affinity fields】,它保存了 肢体的支持区域【the region of support of the limb】中的位置和方向信息(如图 5c 所示)。部件亲和场是每一个肢体的二维向量域,如图 1d 所示:对于属于 每个肢体(指手臂,或腿,或躯干)的区域中的每个像素,二维向量编码了从肢体上的一个 部件【part】指向另一个部件【part】的方向。每一种肢体(指手臂,或腿,或躯干)都有对应的亲和场来联系到整个身体【body parts】。

Figure 5.身体部位关联策略。(a)两个不同身体部位检测候选点(红色和蓝色点)和它们之间的全部连接(灰色的线)(b)连接结果用中间点(黄色的点)表示:正确的连接(黑色的线)和满足发生率约束的不正确的连接(绿色的线)(c)结果使用PAFs(黄色的箭头),通过编码肢体的位置和方向,PAFs消除了错误的连接。
表示了使用part affinity fields(PAF)建模的骨骼区域,对于骨骼区域内的每一个像素,使用2D向量同时表征位置和方向信息,这里的方向指代当前骨骼对应的关节点对的连接方向,对应vectormap。以下图的骨骼区域为例
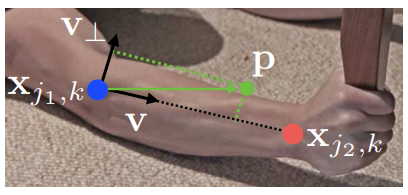

其中,分别表示关节
与
的位置坐标。
分别表示人物索引与关节对索引(c),则有:


其中,,表示位置
指向
位置的单位向量。
图中绿色虚线框内的区域以点集表示,数学公式如下:
其中肢体的宽度是像素距离,肢体的长度是
,
是垂直与v的向量。
关节对c中的PAF的真实值是所有人的PAF的平均值。所有的肢体(limb)关节对c的平均值,
(9)(
是向量,那么它合计也是向量,而
是标量,收缩了
分之一)
是所有 k 个人在点 p 处的非零向量的数目(即不同人的肢体重叠处的像素平均值),仅计算有值的PAF,如果一些原因导致值为0,则不计入n中。
表示某个关节c在p点的PAF。从而知道所有关键点的PAF。
到这里,PAF的GT便得到了。
评估两个关键点之间的相关性:
关键点dj1,dj2和PAF已知之后,计算两个关键点连线向量和两关键点连线上各像素的PAF向量之间的点积的积分作为两个关键点之间的相关性
在测试中,我们通过对应的PAF,来计算 连接候选点的线段上的线积分,然后获取候选点之间的连接。换句话说,我们计算预测的PAF与候选肢体的alignment(这里应该指“距离”/"差距"等意思),其中候选肢体将检测到的身体关节点连接而成。具体来说,对于两个候选位置,我们沿着线段与预测的亲和场
进行采样,测量它们之间的关联的置信度。
(11)
这里p(u) 是肢体两端关键点 的之间的点集(两个关键点之间的插值点)。
实际中,我们通过取样u的等间距值,求和对应L值来计算积分。
是在点p位置上的PAF数值;
是两个关键点之间的单位向量
- p(u) 是两个关键点之间的插值
- E 是通过计算PAF L 和向量
之间的点积积分得到的。
例如计算关键点之间连线的10个插值点,然后这10个插值点的PAF与单位向量
在实践中,我们通过抽样来估计积分求和的均匀间隔值

Figure 6.图匹配。(a)带有检测出的身体部位的原图(b)K分图(c)树结构(d)一组二分图
2.4 Multi-Person Parsing using PAFs
对预测的置信度图进行nms操作后可以得到一组候选关键点的离散集,对于每一个身体部位可能存在多个候选,主要因为图像上会有多个人或者存在FP的情况,从这些候选身体部位可以定义一个大的可能肢体集合,通过上面的积分公式(11)计算每一个候选肢体的分数。
对于每一个part,都有多个候选点,如何把他们一一对应起来,是一个K维匹配问题,已知为NP-Hard [54](图6c)。本文提出greedy relaxation方法来产生高质量的匹配,究其原因可能是由于PAF网络的接收域很大,使得成对关联分值(pair-wise association scores)对全局上下文进行了隐式的编码。
注:为了解决NP-Hard问题,作者采用d的形式,为什么可以呢,由于人体骨架结点,都是有父结点的,所以完全可以在分类的基础上,做二对搜索,即d。如果采用了这种方法,间接的将两都联系起来了,同一个人的能量越高,不同人的能量越低,这样就非常有效利用了全局信息,不同人之间,在图像层面距离会比较远,那么就有了更大的感受野,所以在网络设计上,应该会有所考量。
首先我们已经得到多人的一个身体部位检测候选集
![]()
是身体部位j的检测到的数量;
是身体部位j的第m个候选检测到的身体部位。这些检测到的身体部位如果属于同一个人,就需要与同一个人的其他部位关联,也就是说,在算法上我们需要查找的可以组成肢体的身体部位的配对(pairs of part)。
例如图片中存在多个手肘和手腕时,如何确定每一个人的手腕和手肘并进行连接?即一张图像上存在n个手肘m个手腕(关键点),手肘标签{
},手腕标签
,手臂(手腕和手肘相连)集合Zc。
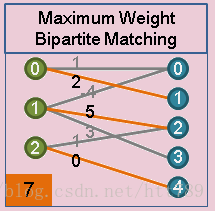
关键点和关键点之间的相关性PAF已知,将关键点作为图的顶点,将关键点之间的相关性PAF看为图的边权,则将多人检测问题转化为二分图匹配问题,并用匈牙利算法求得相连关键点最优匹配。


是c类肢体的的匹配的总体权重,
是第c类肢体的集合,Z的子集,
-
是关节点
之间的两种关键点之间的相关性 (前面公式定义的 E)
Dj1,Dj2是两种关节的集合,Zc是第c种肢体的集合,Emn是两种关键点之间的相关性,求最优的zc集合。

二分图匹配:
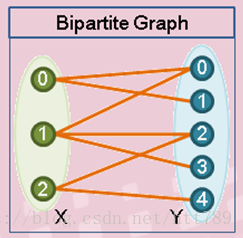
二分图:是图的一种特例,图中包含两个点群X、Y,同一个点群内无边,不同点群之间有边。
二分匹配:二分图上进行匹配,一个点群中的点只与另一个点群中的点进行唯一匹配,即任意两条边没有公共顶点
最大匹配:匹配边数最多
完美匹配:所有点都是匹配点
最大权重匹配:所有匹配边权重之和最大
求解最大匹配方法:匈牙利算法
这些检测的关键点的候选点依然需要与同一个人的其他关键点进行连接。换句话说,我们需要找出正确的每对的肢体连接。我们定义变量 z j 1 j 2 m n ∈ { 0 , 1 } z_{j_1j_2}^{mn} \in \{0,1\} zj1j2mn∈{0,1} 表示两个相连的关键点 d j 1 m d_{j1}^m dj1m 和 d j 2 m d_{j2}^m dj2m 是否相连,目标是为了找到 所有正确连接的集合的最优分配。其中
当需要找到多个人完整的姿态时,确定 Z 是一个 k 维的匹配问题。这是一个 NP Hard问题,同时存在很多【松弛】(应该是找寻最短路径问题。链接1 、链接2)。
这项工作中,我们添加了两个松弛算法到优化里。(释:relaxation(松弛法)定义理解)首先,我们选择一个最小边数来获取人体姿势的一块棵生成树的骨架,而不是使用完成的图,如图 (c )。然后,我们进一步的将这个匹配问题分解成二分图匹配的集合,同时分别确定【相邻树节点】的匹配,如图 (d)。我们在3.1节中展示了结果对比,证明了最小贪心推断 可以在很小的计算成本上得到很好的全局结果。原因是在相邻树节点时间的关系可以通过PAFs精准的模型化,但内在的,不相邻节点之间的关系通过CNN隐式的模型化了。这一性质的出现是因为CNN训练时有个很大的感受野,同时不同相邻树节点的PAFs 也会影响着预测的PAF。
这两个【松弛】,优化式被简单的分解为
因此对于每种肢体类型,我们使用本节内容的前三个公式,分别获取了每个肢体连接的候选。对于所有肢体连接的候选,我们组合这些共享同一个关键点的连接,来得到多人完整的姿势。我们的基于数结构的优化方案是数量级的快于基于全部连接图上的优化。


2.5 算法总结
最后总结一下,这一套操作都做了啥。
- 首先得到关键点和PAF的GT,也就是标注的过程。
- 关键点就是用一个高斯函数,由于是一个单峰的函数,在峰值出便是关键点GT;
- PAF就是先选取一段limb,然后得到这段limb的方向,最后取平均值,便得到了PAF的GT;
- 在得到这两个GT后,将各个关键点连接起来。
- 连接方式便是上述所说的,计算期望,取最大值,得到连接。
3. Result
我们评估我们的方法在两个多人姿态估计的基准上完成:(1)MPII 人体多人姿态估计、(2)COCO 2016 关键点挑战数据。这两个数据集收集了不同场景下的图片,其包含许多真实世界的挑战,例如:拥挤的人群、不同尺寸、遮挡、接触。我们的方法创造了先进的效果在开始的COCO数据集上,而且明显的超过之前在MPII数据集上的最先进的效果。我们还提供了运行时间来量化系统的效率。下图展示了我们算法的一些定性结果。

3.1 Results on the MPII Multi-Person Dataset
为了对比MPII数据集,我们使用工具包来测量 基于PCKh阈值的人体关键点的mAP(mean Average Precision)。表1 在相同的288个测试图片上,使用我们的方法和其它方法对比了mAP 性能,另外在整个MPI测试集,还有我们自己的验证集上的自我比较。除了这些测量,我们在每张图上比较了平均 预测/优化 时间。对于288子测试集,我们的方法比之前最先进的自下而上的方法好了8.5%的mAP。惊人的是,我们的预测时间少了6个数量级。我们在3.3节中报告了更详细的运行时间分析。对于整个MPII数据集,我们的方法不用尺度搜索已经比之前最先进的方法要好很多,即在mAP上了13%。使用了3个尺度(x0.7, x1, x1.3)进一步的增加性能,mAP提高到75.6%。与之前的自下而上的方法的mAP相比较,表明了我们新的特征表示的有效性。基于树结构,我们的贪心划分方法,与基于全部连接图的图割优化公式相比,实现了更好的准确性。
在表2中,我们我们展示了在我们验证集中,使用图6中不同结构的对比结果,343张不在MPII训练集中的图片。我们基于全连接图训练我们的模型,并与选择所有的边的方式进行对比(图6b,用整数线性规划近似求解),以及最小树边(图6c,用整数线性规划近似求解。以及图本文算法图6d,使用贪心算法)。他们相似的性能表示了使用最小表就足够了。我们训练另外一个模型,只学习最小欧变来充分利用网络容量,正如这篇论文所展示的方法图6d。这种方式保持了效率的同时,效果超越了图6c和图6d。原因是许多很小数量的关节点连接通道(13边数 vs 91边树),使这更容易训练收敛。
图7a展示了,基于我们验证集上的一个消融分析。对于PCKh-0.5的阈值,使用PAFs的结果比使用 中点表示的结果更好。明确的说,比单中点表示高2.9%,比双中点表示高2.3%。PAFs 同时编码了人体肢体的位置信息和方向信息,这可以更好区分出常见的肢体交叉重叠的情况,例如手臂重叠。训练中 使用未标签的人的mask 提高了性能2.3%,因为在训练损失中,避免了惩罚真实正确预测的位置。
在图7a中,在不同的PCKh阈值下 我们使用GT检测划分的mAP保持不变,这是由于没有定位错误。基于我们的关键点检测上使用GT连接,到达了81.6% mAP。值得注意,我们基于PAFs的划分算法达到了使用GT连接相似的mAP(79.4% vs 81.6%)。这表明基于PAFs的划分方式 在正确的连接检测的关键点上,是十分鲁棒的。图7b展示了不同阶段的性能的比较。在迭代优化框架下,mAP单调递增。图4展示了多个stage后的预测的质量的提升。


3.2 Results on the COCO Keypoints Challenge
COCO训练集是由100k人的实例,其中超过1百万个关键点的标注(人体关节点)。测试集包括“测试挑战”、“测试开发”、“测试标准”,每一个包括大约20k张图片。COCO评估定义了目标关键点的相似性【the object keypoint similarity (OKS)】,同时在10个OKS阈值上使用AP,作为主要竞争指标。OKS在目标检测中扮演着相同的角色。它由人的尺度、预测点和真实点之间的距离计算而来的。表3展示了这项工作中顶尖团队的结果。
值得注意的是,在小尺寸人时,我们的方法比自上而下的方法的精度低很多。是因为我们的方法需要同时处理较大尺寸范围,其包括了图片中的所有人。相比,自上而下的方法能够重新调整每个检测区域的尺寸,到更大的尺寸,因此在较小的尺寸下面临较小的恶化。
在表4中,我们报告了在COCO验证集的子集中的自我比较,随机选择的的1160张图片。如果我们使用真实边界框和单人的CPM,使用CPM 我们可以达到自上而下的方法的上限62.7%的AP。如果我们使用最先进的目标检测SSD,性能下降10%。自我比较表明了自上而下方式的性能十分依赖人体检测器。相比而言,我们自下而上方式达到了58.4%的AP。如果用我们的方法将被估计的人的区域重新缩放,然后使用CMP,将会改善我们的结果,获得了2.6% AP的提升。注意,我们仅仅更新了对两种发放一致的预测的估计,从而提高了精度和召回率。我们希望更大的尺寸搜索能够进一步的提升我们自下而上的性能。图8展示了在COCO验证集上我们方式错误的情况。大多数假阳性来源于不准确的定位,除了背景的混淆。这说明捕获空间的依赖 比识别身体部分的外观,有更多的提升空间。


3.3 运行时间分析
为了分析我们的方法的运行时间性能,我们挑选了有着巨大数量的人的视频。原始帧的尺寸是1080x1920,在测试时为了使用GPU的显存,resize到368x654。运行时间的分析在显卡为GTX-1080的笔记本上执行。在图8d中,我们用人体检测器+单人CPM作为一个自上而下的比较,其运行时间与图片中人的数量大概成正比。相比之下,我们的自下而上方法,随着人数的增减,其的运行时间增加缓慢。这个运行时间包括两部分:(1) CNN处理的运行时间,其复杂度记为 O ( 1 ) O(1) O(1),为常量;(2) 多人划分时间(肢体的正确连接),其复杂度记为 O ( n 2 ) O(n^2) O(n2),这里的n是人的数量。然而,划分时间不会是整体运行时间的主要因素,因为它比CNN处理时间少两个量级。例如,9个人肢体划分需要0.58ms,CNN需要99.6ms。我们的方法在视频有19人时,已经达到了8.8 fps的处理速度。
References
- [1] MSCOCO keypoint evaluation metric http://mscoco.org/dataset/##keypoints-eval 5, 6
- [2] M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele. 2D human pose estimation: new benchmark and state of the art analysis. In CVPR, 2014. 5
- [3] M. Andriluka, S. Roth, and B. Schiele. Pictorial structures
revisited: people detection and articulated pose estimation.
In CVPR, 2009. 1
Figure 10.包含视点和外观变化,遮挡,拥挤,接触和其他常见成像伪像的结果
-
[4] M. Andriluka, S. Roth, and B. Schiele. Monocular 3D pose estimation and tracking by detection. In CVPR, 2010. 1
-
[5] V. Belagiannis and A. Zisserman. Recurrent human pose estimation.In 12th IEEE InternationalConference and Workshops on Automatic Face and Gesture Recognition (FG),2017. 1
-
[6] A. Bulat and G. Tzimiropoulos. Human pose estimation via convolutional part heatmap regression. In ECCV, 2016. 1
-
[7] X. Chen and A. Yuille. Articulated pose estimation by a graphical model with image dependent pairwise relations. InNIPS, 2014. 1
-
[8] P. F. Felzenszwalb and D. P. Huttenlocher. Pictorial structures for object recognition. In IJCV, 2005. 1
-
[9] G. Gkioxari, B. Hariharan, R. Girshick, and J. Malik. Using k-poselets for detecting people and localizing their keypoints. In CVPR, 2014. 1
-
[10] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016. 1
-
[11] E. Insafutdinov, L. Pishchulin, B. Andres, M. Andriluka, and B. Schiele. Deepercut: A deeper, stronger, and faster multiperson pose estimation model. In ECCV, 2016. 1, 5, 6
-
[12] U. Iqbal and J. Gall. Multi-person pose estimation with local joint-to-person associations. In ECCV Workshops, Crowd Understanding, 2016. 1, 5
-
[13] S. Johnson and M. Everingham. Clustered pose and nonlinear appearance models for human pose estimation. In BMVC,
-
[14] H. W. Kuhn. The hungarian method for the assignment problem. In Naval research logistics quarterly. Wiley Online Library,
-
[15] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick. Microsoft COCO: com- mon objects in context. In ECCV, 2014. 5
-
[16] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, and S. Reed. Ssd: Single shot multibox detector. In ECCV, 2016. 6
-
[17] A. Newell, K. Yang, and J. Deng. Stacked hourglass networks for human pose estimation. In ECCV, 2016. 1
-
[18] W. Ouyang, X. Chu, and X. Wang. Multi-source deep learning for human pose estimation. In CVPR, 2014. 1
-
[19] G. Papandreou, T. Zhu, N. Kanazawa, A. Toshev, J. Tompson, C. Bregler, and K. Murphy. Towards accurate multi-person pose estimation in the wild. arXiv preprint arXiv:1701.01779, 2017. 1, 6
-
[20] T. Pfister, J. Charles, and A. Zisserman. Flowing convnets for human pose estimation in videos. In ICCV, 2015. 1
-
[21] L. Pishchulin, M. Andriluka, P. Gehler, and B. Schiele. Poselet conditioned pictorial structures. In CVPR, 2013. 1
-
[22] L. Pishchulin, E. Insafutdinov, S. Tang, B. Andres, M. Andriluka, P. Gehler, and B. Schiele. Deepcut: Joint subset partition and labeling for multi person pose estimation. In CVPR, 2016. 1, 5
-
[23] L. Pishchulin, A. Jain, M. Andriluka, T. Thormahlen, and ¨B. Schiele. Articulated people detection and pose estimation:Reshaping the future. In CVPR, 2012. 1
-
[24] V. Ramakrishna, D. Munoz, M. Hebert, J. A. Bagnell, and Y. Sheikh. Pose machines: Articulated pose estimation via inference machines. In ECCV, 2014. 1
-
[25] D. Ramanan, D. A. Forsyth, and A. Zisserman. Strike a Pose: Tracking people by finding stylized poses. In CVPR, 2005.1
-
[26] K. Simonyan and A. Zisserman. Very deep convolutionalnetworks for large-scale image recognition. In ICLR, 2015.2
-
[27] M. Sun and S. Savarese. Articulated part-based model for joint object detection and pose estimation. In ICCV, 2011. 1
-
[28] J. Tompson, R. Goroshin, A. Jain, Y. LeCun, and C. Bregler. Efficient object localization using convolutional networks. In CVPR, 2015. 1
-
[29] J. J. Tompson, A. Jain, Y. LeCun, and C. Bregler. Joint training of a convolutional network and a graphical model for human pose estimation. In NIPS, 2014. 1
-
[30] A. Toshev and C. Szegedy. Deeppose: Human pose estimation via deep neural networks. In CVPR, 2014. 1
-
[31] S.-E. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh. Convolutional pose machines. In CVPR, 2016. 1, 2, 3, 6
-
[32] D. B. West et al. Introduction to graph theory, volume 2. Prentice hall Upper Saddle River, 2001. 4, 5
-
[33] Y. Yang and D. Ramanan. Articulated human detection with
flexible mixtures of parts. In TPAMI, 2013. 1