【https://github.com/namedBen/Convolutional-Pose-Machines-Pytorch】
【https://github.com/timctho/convolutional-pose-machines-tensorflow】
【CVPR2016】
Convolutional Pose Machines(CPM)的主要贡献在于:
a) 用Heatmap来表示关节点的位置及位置约束关系,并且将Heatmap和Feature Map同时作为数据在网络中传递,同时在多个尺度处理输入的特征,充分考虑各个关节点之间的空间位置关系。
b) 多个阶段(Stage)有监督训练,避免过深网络难以优化的问题。
OpenPose是GitHub上最受欢迎的人体姿态估计项目(14.8K Stars, 4.2K Folks),其人体关键点检测正是主要基于Convolutional Pose Machines。
Pose estimation是一种全卷积网络,输入是一张人体姿势图,输出n张热力图,代表n个关节的响应。

CPM(Convolutional Pose Machines) [5] 利用序列化的卷积神经网络来学习纹理信息和空间信息,实现 2D 人体姿态估计。CPM 通过设计多阶段的网络结构逐渐扩大网络的感受野,获取远距离的结构关系。每一阶段融合空间信息,纹理信息和中心约束来得到更为准确的热图预测。
Convolutional Pose Machine(CPM)解读
论文阅读理解 - Convolutional Pose Machines
【人体姿态】Convolutional Pose Machines
2D关键点检测之CPM:Convolutional Pose Machines - 知乎 (论文说明最全)
1、思想
本文的特色有三:
- 1.用各部件响应图来表达各部件之间的空间约束。响应图和特征图一起作为数据在网络中传递。
- 2.网络分为多个阶段(stage)。各个阶段都有监督训练,避免过深网络难以优化的问题。
- 3.使用同一个网络,同时在多个尺度处理输入的特征和响应。既能确保精度,又考虑了各个部件之间的远距离关系。

2、算法
流程如下:
- 在每一个尺度下,计算各个部件的响应图
- 对于每个部件,累加所有尺度的响应图,得到总响应图
- 在每个部件的总响应图上,找出相应最大的点,为该部件位置
为了捕捉关节点间 long-range 的相互关系,CPMs 中每个 stage 的网络设计的启发点是:同时在图像和置信图上得到大的接受野(large receptive field).




图中(a)和(b)是pose machine中的结构,(c)和(d)是其对应的卷积网络结构,(e)展示了图片在网络中传输的不同阶段的感受野
- 基于每个 scale,计算网络预测的各关节点 heatmap;
- 依次累加每个关节点对应的所有 scales 的 heatmaps;
- 根据累加 heatmaps,如果其最大值大于指定阈值,则该最大值所在位置 (x,y) 即为预测的关节点位置.
3、Stage 1:
对输入图片做处理,其中X代表经典的VGG结构,并且最后采用1×1卷积输出belief map,如果人体有p个关节点,那么belief map有p层,每一层表示一个关节点的heatmap。belief map与label计算该阶段的loss,并存储起来,在网络末尾将每一层的loss加起来作为total loss用于反向传输,实现中间监督,避免梯度消失。
stage t=1 时, CPM 根据图片局部信息(local image evidence)预测关节点. 利用图片局部信息local,是指网络的接受野被约束到输出像素值的局部图片块. 如图:
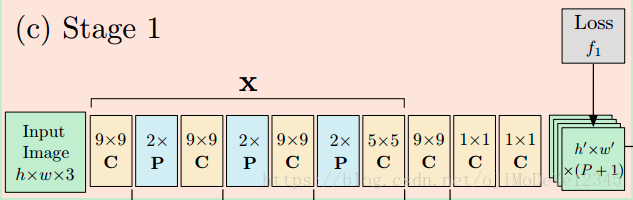
输入图片 368×368 ,卷积层不改变 feature maps 的 width 和 height,经三次 pooling 层,输出的 feature maps 大小 46×46,共 P+1 个 feature maps.(P个关节点)
t≥2 时网络的输出是一致的,都是 46×46×(P+1) 的 feature maps.
Stage T:对于Stage 2以后的Stage,其结构都统称为Stage T,其输入为上一个Stage的输出以及对原始图片的特征提取的联合,输出于Stage 1一致

4、Stage t>1
启发点:关节点的置信图(belief maps),尽管存在 noisy, 但却是包含有用信息的. 如图:

Figure 3. belief maps 的空间信息. 容易检测的关节点可以为难以检测的关节点提供有用信息. (shouler, neck, head) 关节点,对于 (right elbow) 后续 stages 的 belief maps 来说,有助于消除其错误的估计(red),并提升其正确估计(green).
如果图片中有多个人物,需要对多人进行姿态估计时,在这里还要输入一个center map。center map是一个高斯响应,当图片中有多人时,center map告诉神经网络目前要处理的人的位置,从而自底向上处理多人pose问题。



5、CPM 训练
CPM 每个 stage 都会输出关节点的预测结果,重复地输出每个关节点位置的 belief maps,以渐进精细化的方式估计关节点. 故,在每个 stage 输出后均计算 loss,作为中间监督 loss,避免梯度消失问题.

如:

每个 stage 的 Loss 函数:

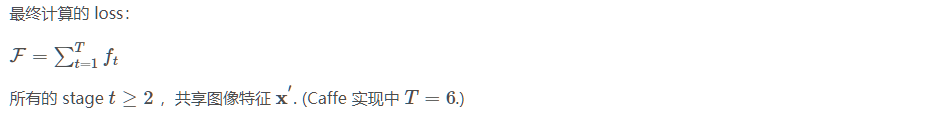
MPII 数据增强处理:
- 随机旋转图片 [-40, 40]
- 图片缩放 [0.7, 1.3]
- 水平翻转
6、intermediate supervision 中间监督方法
如果直接对整个网络进行梯度下降,输出层的误差经过多层反向传播会大幅减小,而发生梯度消失现象。
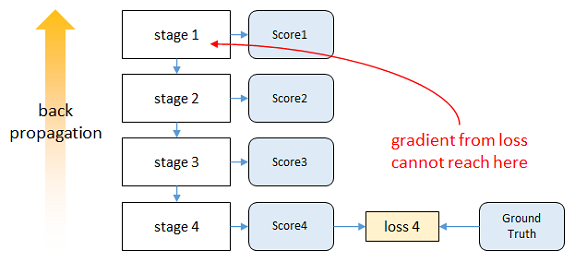
本文为了解决这个问题,提出了中间监督方法,从而保证底层参数的正常更新。

效果如下图,可以看到,加入中间监督之后,在靠近输入的stage,其梯度比没有中间监督大很多,从而保证学习的效果。
7、感受野
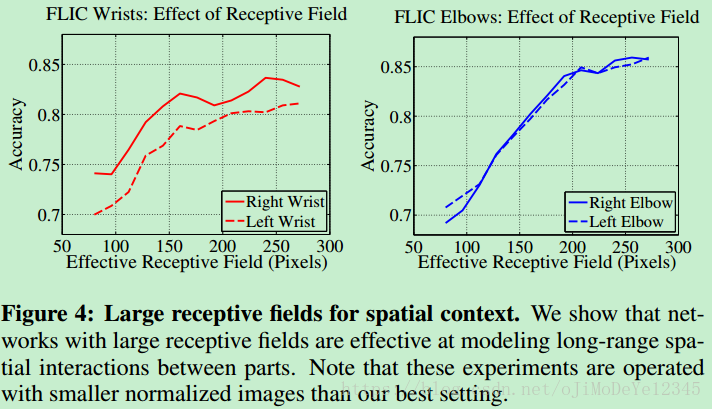
感受野即输出图片一个像素在原始图片上映射的区域大小。CMP采用大卷积核获得大感受野,对于推断被遮挡的关节很有效。可以看到在网络的stage 2 的输出部分,感受野已经扩大到400400的大小。
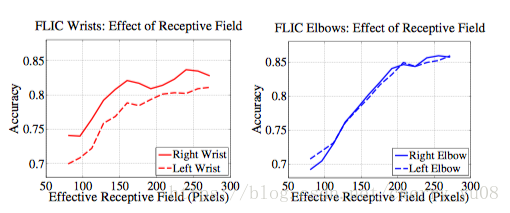
作者在论文中指出,预测的准确率随着感受野的增大而提高(这里应该指的是在同一个网络中感受野的增大,即在同一次训练过程中感受野的增大),在FLIC数据集中对于手腕关节的预测,当感受野增大到250pixcel时预测的准确率趋于稳定状态,这表明神经网络编码了(encode)身体部件之间的长距离交互。在以上网络结构图最好的输出结果中,将原始图片预处理至368368,stage 2 输出值的感受野相当于原始输入图片的400*400像素,此时感受野可以覆盖图片中身体的任何一个部件。stage越多,感受野也就越大。下面是论文中给出的准确率随感受野上升的曲线图:
8、使用阶段
人物检测
人物检测部分代码与姿态估计类似,只是最后一个stage输出的是一个指示了人物位置的map。
首先将图片resize到固定大小,然后pad(因为网络会将图片downsize所以先pad,这样能得到与原始图片相同大小的输出图片),运行网络,得到定义人物位置的块:
对应人物的位置:
单人姿态估计的话可以省略这一步。


姿态估计
根据上面的center position将每个人物分割开来,使用CPM网络进行预测。输出的图片中,另加一层background channel绘制关节点的位置,如果需要,可以连接关节点。