爬取豆瓣电影top250的相关信息以及可视化数据
前言
文章写得比较简陋,是俺第一次的作品,部分代码也是在网上遨游中获得,没能完全理解,望各位看官海涵。
分享一个自己做的小爬虫项目,代码比较简单。
项目大体分为爬取数据模块,分析数据模块,数据可视化模块
先讲一下大致的流程,再贴代码,写一下我遇到的问题
准备工作
下载requests库,Beautifulsoup库,xlsxwriter,re,pandas,pyecharts,numpy库,本实验在eclipse上运行
流程
首先,是伪造浏览器的头部,让网站以为是浏览器在访问
不过要是爬取次数过多的话,会导致网页封掉你的ip
我这里没有做什么技术性处理,直接用了代理(因为太懒和菜了)
接着就是用Beautifulsoup来解析网页,用soup.find这条语句来一个个获得标签下的数据,一些不好爬取的数据,就用蠢蠢的正则表达式来处理了。
爬取完数据后,就把数据给导进excel文件中,方便待会的数据分析与数据可视化
爬取网页数据
我这次爬取数据用的最多的就是soup.find和soup.find_all语句,

两者的差别在在于,find只返回第一个找到的元素,而find_all返回找到的所有元素.。find的用法比较简单,一个个标签往下剥离就行了。
我在这个模块中还利用到了正则表达式来爬取一些find语句不方便爬取的标签,而且正则表达式爬取到的数据比find语句好看,你可以设置其去掉空格。
部分代码如下:

爬取到数据后,将其加入到excel表格中
这段写入excel的代码是在网上翻阅获得,现在找不到出处了…代码作者要是不愿意的话,联系我把其删去
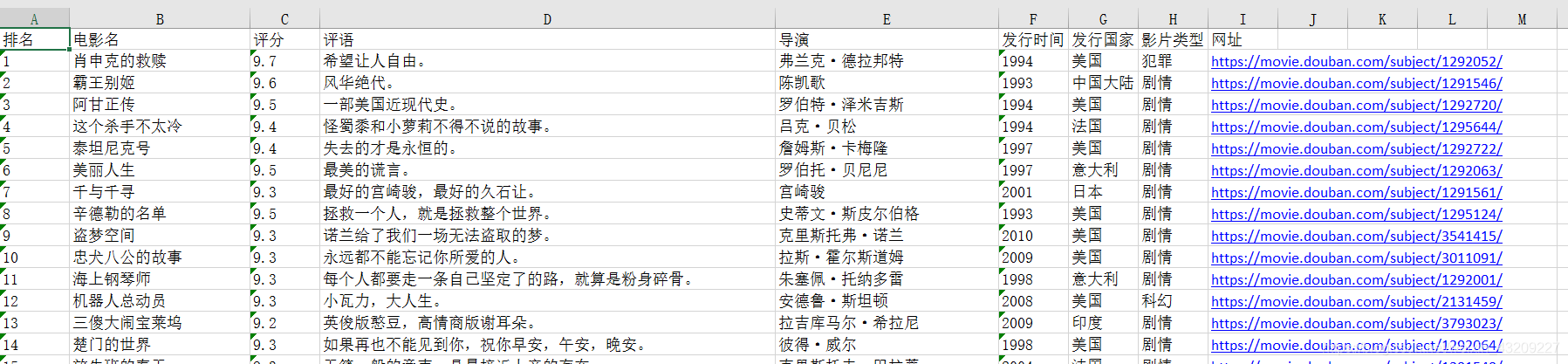
得到的表格如图
数据分析与数据可视化
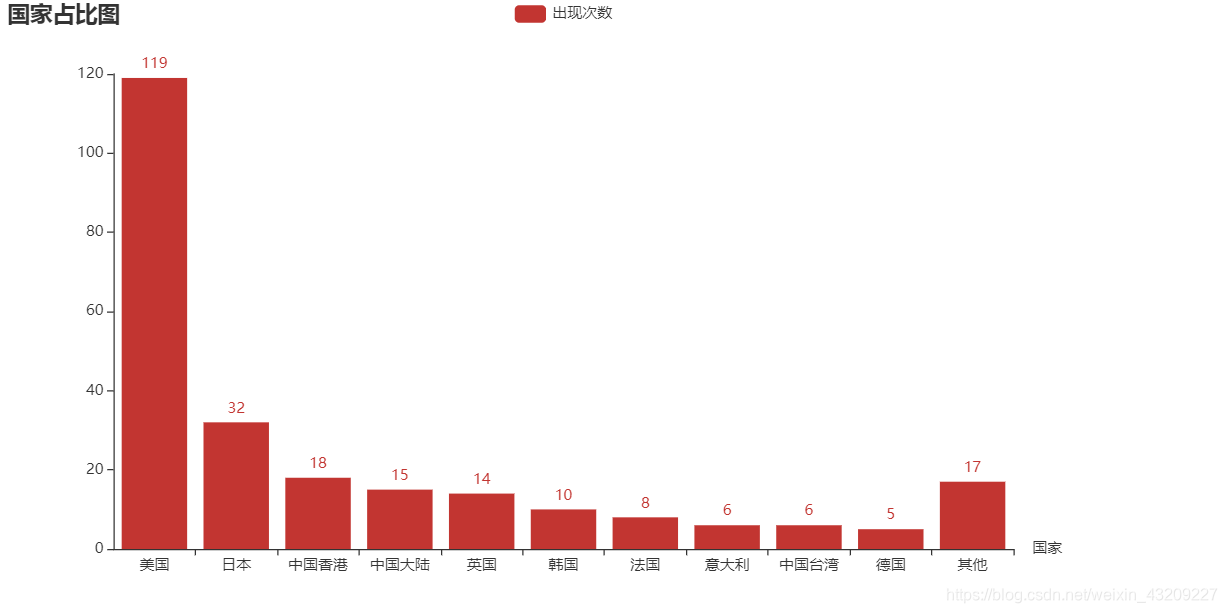
以做一个条形图为例
分析哪个国家在电影top250的榜单中出现的最多
df = pd.read_excel(“C:/Users/tanweiming/workspace/dsc/work/d.xlsx”,sheet_name= “Sheet1”)
k = df[‘发行国家’].value_counts().reset_index()[‘index’].to_list()
g = df[‘发行国家’].value_counts().reset_index()[‘发行国家’].to_list()
length = len(k)
a=0
i=10
sum=0
list=[]
b=[]
for a in range(i):
list.append(k[a])
b.append(g[a])
list.append(‘其他’)
for i in range(10,length):
p=g[i]
sum=sum+p
b.append(sum)
def bar_base(x,y) -> Bar:
c = (
Bar()
.add_xaxis(x)
.add_yaxis(“出现次数”,y)
.set_global_opts(title_opts=opts.TitleOpts(title=“国家占比图”),xaxis_opts=opts.AxisOpts(name=“国家”))
)
return c.render(“条形图.html”)
bar_base(list,b)
得出的效果如图:
代码块
爬取数据与导入数据的代码
#coding=gb18030
import requests
from bs4 import BeautifulSoup
from idlelib.iomenu import encoding
from ast import parse
from cgitb import text
import re
import xlsxwriter
def get_html(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'}
html = requests.get(url,headers=headers)
return html.text
def parse_html(html):
soup = BeautifulSoup(html, 'html.parser')
big_film =soup.find('ol', attrs={'class':'grid_view'})
#print(big_film)
films = big_film.find_all('li')
list=[]
pattern = re.compile('info.*?<br>(.*?) / ',re.S)
pattern1 = re.compile('info.*?<br>.*? / (.*?) ',re.S)
pattern2 = re.compile('info.*?<br>.*? / .*? / (.*?) ',re.S)
results = re.findall(pattern,str(html))
results1 = re.findall(pattern1,str(html))
results2 = re.findall(pattern2,str(html))
i=0
for film in films :
result = results[i].strip()[ :4]
result1 = results1[i].replace('&n',' ')[ :4].strip()
result2 = results2[i].strip('\n').strip()
i+=1
rank = film.find('em', attrs={'class':""}).text
name = film.find('span',attrs={'class':"title"}).text
point = film.find('span',attrs={'class':"rating_num"}).text
talk = film.find('span',attrs={'class':"inq"}).text
link = film.div.div.a['href']
other_html = get_html(link)
professor = parse_htzml1(other_html)
list.append([rank,name,point,talk,professor,result,result1,result2,link])
return list
def save_excel(fin_result, tag_name, file_name):
book = xlsxwriter.Workbook(r'%s.xlsx' % file_name)
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num+2):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-2] # -2是因为当i=2时下标应为0
tmp.write_row(con_pos, content)
book.close()
def parse_html1(html):
soup = BeautifulSoup(html, 'html.parser')
film = soup.find('div',attrs={'id':"info"})
professor = film.find('span',attrs={'class':"attrs"}).text
#print(professor)
return professor
if __name__ == '__main__':
result = []
for i in range (10):
url = 'https://movie.douban.com/top250?start=' + str(i*25)
html = get_html(url)
result+=parse_html(html)
title_list = ["排名","电影名","评分","评语","导演","发行时间","发行国家","影片类型","网址"]
save_excel(result, title_list, "d")
#encoding=gb18030
import numpy as np #国家
import pandas as pd
from pyecharts import options as opts
from pyecharts.faker import Faker
from pyecharts.charts import Bar
df = pd.read_excel("C:/Users/tanweiming/workspace/dsc/work/d.xlsx",sheet_name= "Sheet1")
k = df['发行国家'].value_counts().reset_index()['index'].to_list()
g = df['发行国家'].value_counts().reset_index()['发行国家'].to_list()
length = len(k)
a=0
i=10
sum=0
list=[]
b=[]
for a in range(i):
list.append(k[a])
b.append(g[a])
list.append('其他')
for i in range(10,length):
p=g[i]
sum=sum+p
b.append(sum)
def bar_base(x,y) -> Bar:
c = (
Bar()
.add_xaxis(x)
.add_yaxis("出现次数",y)
.set_global_opts(title_opts=opts.TitleOpts(title="国家占比图"),xaxis_opts=opts.AxisOpts(name="国家"))
)
return c.render("条形图.html")
bar_base(list,b)
