版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_25343557/article/details/81743845
爬取目标:豆瓣电影TOP250,并且存入csv文件中
爬取内容:

首页请求地址:https://movie.douban.com/top250?start=0&filter=
多查看几页的请求地址我们可以发现以下规律:
1、每页显示25条内容,共10页;
2、每页的请求地址只改变start的值,第一页为0,第二页为25,第三页为50,所以第n页为(n-1)*25。
右键查看网页源代码我们可以发现每部电影的信息都在li标签中:

这就表明我们不需要去抓包分析。思路很简单了:发送请求→获取网页源代码→正则匹配→保存匹配信息。
实现代码:
import requests
from requests import RequestException
import re
import logging
import csv
logging.captureWarnings(True)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE'}
proxyIp = {'http':'106.75.9.39:8080','http':'118.190.95.35:9001'}
def getHtml(url):
'''
:param url: 请求地址
:return:
'''
try:
response = requests.get(url,headers=headers,proxies=proxyIp,verify=False)
if response.status_code == 200:
return response.text
return ""
except RequestException as e:
print("出异常了!!")
print(e)
def parseHtml(text):
'''
:param text: 网页源代码
:return:
'''
pat = r'<div class="item">.*?<em class="">(\d+)</em>.*?<img width="100" alt="(.*?)".*?...<br>.*?\n\s*(.*?) / (.*?) / (.*?)\n.*?</p>.*?<div class="star">.*?<span>(\d+)人评价</span>'
list = re.compile(pat,re.S).findall(text)
return list
def saveCsv(filename,head,data):
'''
:param filename: 文件名
:param head: csv文件表头
:param data: 数据
:return:
'''
with open(filename,'w',encoding='gbk') as file:
writer = csv.writer(file)
writer.writerow(head)
writer.writerows(data)
if __name__=="__main__":
data=[]
head = ['序号','片名','年份','国家','类型','评论数']
for page in range(10):
print("正在爬取第{}页".format(page+1))
url = "https://movie.douban.com/top250?start={}&filter=".format(str(page*25))
text = getHtml(url)
items = parseHtml(text)
for item in items:
data.append(list(item))
print("第{}页爬取完毕!".format(page+1))
saveCsv('TOP250.csv',head,data)保存结果如下:
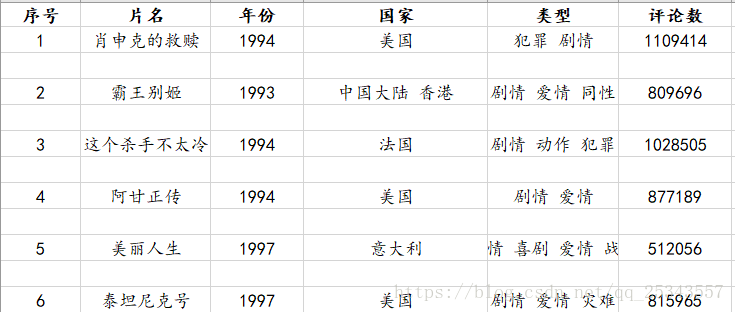
其实这里并没有爬取所有显示的缩略信息,因为有的信息根本就没有。无法写一个正则表达式匹配到所有的信息。所以我退而求其次值获取了部分的信息。思路为重。不懂我们可以交流
拓展:获取每部电影完整信息。
思路其实一样,只不过还要再点击进入每部电影(每部电影链接又是可以获取到)而已,再用正则匹配。
看电影去了,250部呐!!