版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_30399353/article/details/76726561
最终爬到的内容:
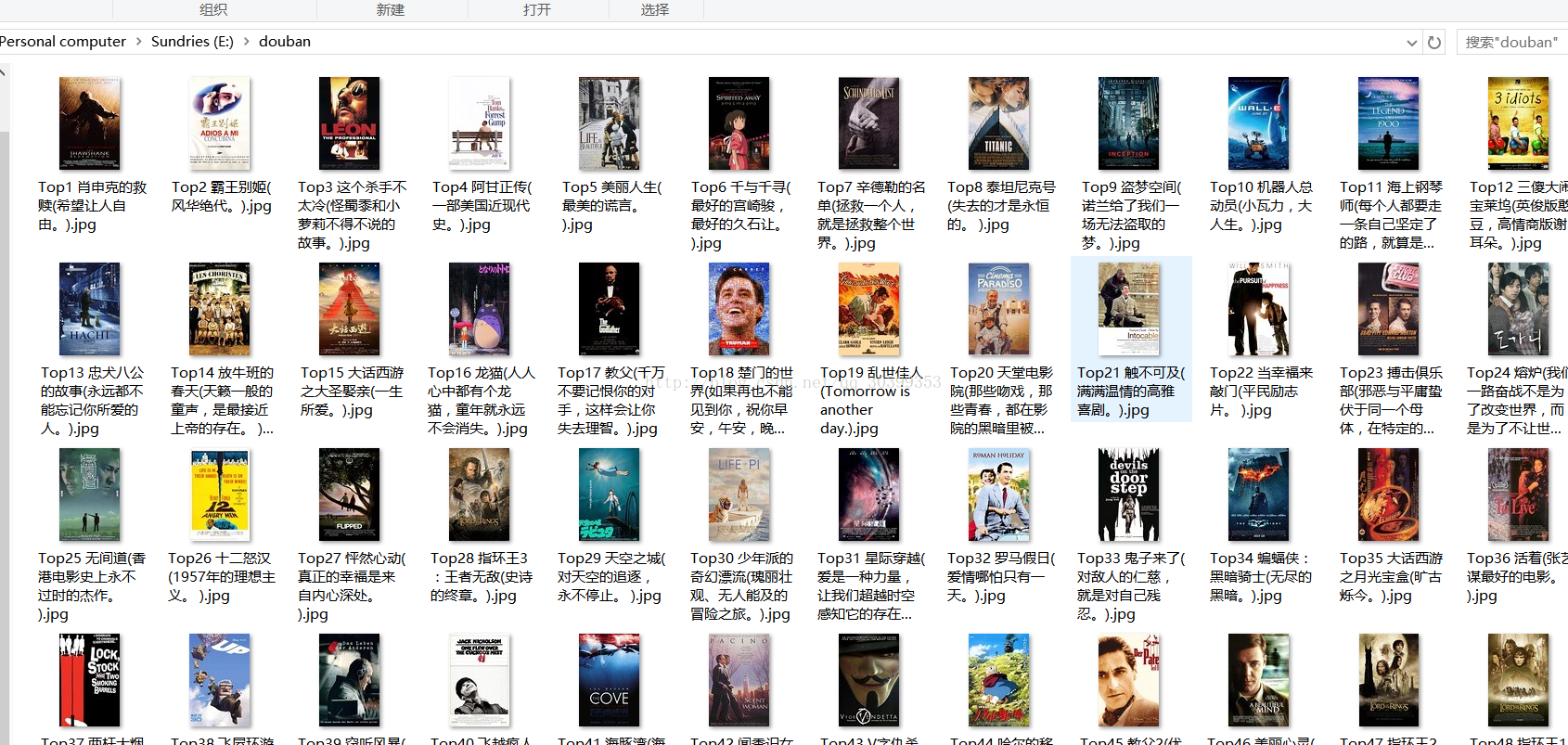
# douban_spiders.py
#coding:utf-8
import scrapy
from douban.items import DoubanItem
from scrapy.crawler import CrawlerProcess
class doubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ["douban.com"]
start_urls = ["https://movie.douban.com/top250"]
def parse(self, response):
item = DoubanItem()
item['image_urls'] = response.xpath('//div[@class="pic"]//img//@src').extract()#提取图片链接
# print 'image_urls',item['image_urls']
item['title'] = response.xpath('//div[@class="hd"]/a/span[1]/text()').extract()#提取电影标题
# print 'title',item['title']
item['quote'] = response.xpath('//p[@class="quote"]/span/text()').extract()#提取简介
# print 'quote',item['quote']
item['level'] = response.xpath('//em/text()').extract()#提取排名
# print 'level',item['level']
yield item
new_url= "https://movie.douban.com/top250" + response.xpath('//span[@class="next"]/link/@href').extract_first()#翻页
# print 'new_url',new_url
if new_url:
yield scrapy.Request(new_url,callback=self.parse)
# items.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = scrapy.Field()
title = scrapy.Field()
quote = scrapy.Field()
level = scrapy.Field()# setting.py
BOT_NAME = 'douban'
SPIDER_MODULES = ['douban.spiders']
NEWSPIDER_MODULE = 'douban.spiders'
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 1,
}
IMAGES_STORE='E:'
DOWNLOAD_DELAY = 0.25
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5' # pipelines.py
import os
import urllib
from douban import settings
class DoubanPipeline(object):
def process_item(self, item, spider):
i = 0
dir_path = '%s/%s'%(settings.IMAGES_STORE,spider.name)#存储路径
print 'dir_path',dir_path
if not os.path.exists(dir_path):
os.makedirs(dir_path)
for image_url in item['image_urls']:
file_name = "Top" + item['level'][i] + ' ' +item['title'][i] + '('+item['quote'][i]+ ").jpg"#图片名称
i = i + 1
# print 'filename',file_name
file_path = '%s/%s'%(dir_path,file_name)
# print 'file_path',file_path
if os.path.exists(file_name):
continue
with open(file_path,'wb') as file_writer:
conn = urllib.urlopen(image_url)#下载图片
file_writer.write(conn.read())
file_writer.close()
return item