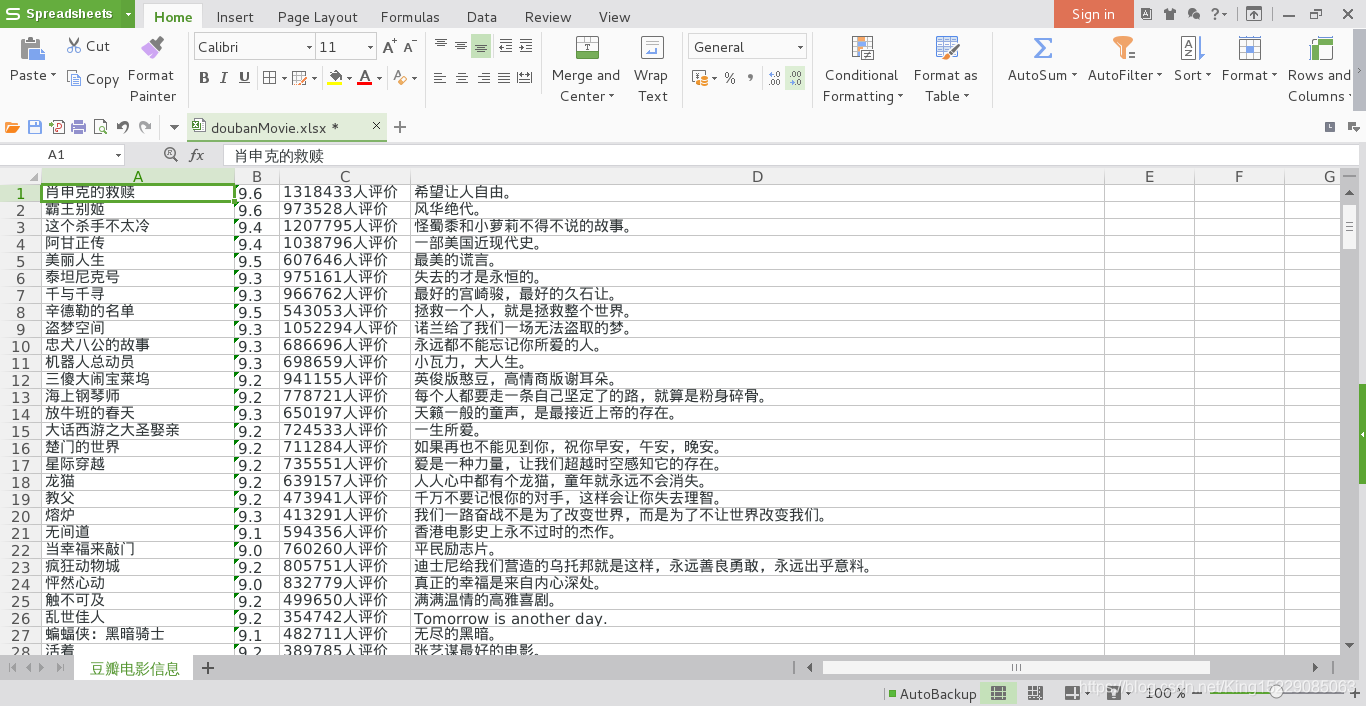
爬取豆瓣电影Top250
爬取豆瓣电影Top250的电影信息:电影名称,电影评分,评价人数,电影短评
源代码:
import re
import openpyxl
import requests
from bs4 import BeautifulSoup
def get_content(url):
try:
user_agent = 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'
response = requests.get(url,headers={'User-Agent':user_agent})
response.raise_for_status() # 如果返回的状态码不是200,则抛出异常
response.encoding = response.apparent_encoding # 根据响应信息判断网页的编码格式,便于response.text知道如何解码
except Exception as e:
print('爬取错误')
else:
print('爬取成功')
return response.text
def parser_content(htmlContent):
# 实例化soup对象
soup = BeautifulSoup(htmlContent,'html.parser')
# 1.所有电影信息存储在ol标签
olObj = soup.find('ol',class_='grid_view')
# 2.获取每个电影的详细信息,存储在li标签
details = olObj.find_all('li')
# 3.获取需要的电影信息
for detail in details:
# 电影名称
movieName = detail.find('span',class_='title').get_text()
# 电影评分
movieScore = detail.find('span',class_='rating_num').get_text()
# 评价人数
movieCommentNum = str(detail.find(text=re.compile('\d+人评价')))
# 电影短评
movieCommentObj = detail.find('span',class_='inq')
if movieCommentObj:
movieComment = movieCommentObj.get_text()
else:
movieComment = '无短评'
movieInfo.append((movieName,movieScore,movieCommentNum,movieComment))
def create_to_excel(wbname,data,sheetname='Sheet1'):
"""将指定信息保存到新建的excel表格"""
print('正在创建eccel表格%s......' %(wbname))
# 如果文件不存在,自己实例化一个Workbook的对象
wb = openpyxl.Workbook()
# 获取当前活动工作表对象
sheet = wb.active
# 将数据data写入excel表格中
sheet.title = sheetname
print('正在写入数据......')
for row,item in enumerate(data):
for column,cellValue in enumerate(item):
cell = sheet.cell(row=row+1,column=column+1,value=cellValue)
# cell = sheet.cell(row=row+1,column=column+1)
# cell.value = cellValue
wb.save(wbname)
print('保存工作簿%s成功......' %(wbname))
if __name__ == '__main__':
doubanTopPage = 10
perPage = 25
movieInfo = []
for page in range(1,doubanTopPage+1):
url = 'https://movie.douban.com/top250?start=%s' %((page-1)*perPage)
content = get_content(url)
parser_content(content)
create_to_excel('doc/doubanMovie.xlsx',movieInfo,sheetname='豆瓣电影信息')
将爬取的信息保存到Excel表格里: