爬取豆瓣电影TOP250
爬取豆瓣电影Top250的电影信息:电影名称,电影评分,评价人数,电影短评
源代码:
import csv
import lxml.etree as etree
import requests
def get_content(url):
try:
user_agent = 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'
response = requests.get(url,headers={'User-Agent':user_agent})
response.raise_for_status() # 如果返回的状态码不是200,则抛出异常
response.encoding = response.apparent_encoding # 根据响应信息判断网页的编码格式,便于response.text知道如何解码
except Exception as e:
print('爬取错误')
else:
print('爬取成功')
return response.text
def parser_content(html):
# 1. 将html内容转化为xpath可以解析/匹配的格式
selector = etree.HTML(html)
# 2.获取每个电影的详细信息,存储在li标签 <ol class="grid_view"><li></li></ol>
movieDetails = selector.xpath('//ol[@class="grid_view"]/li')
# 3.获取需要的电影信息
for movieDetail in movieDetails:
# 电影名称 <span class="title">肖申克的救赎</span>
movieName = movieDetail.xpath('.//span[@class="title"]/text()')[0]
# 电影评分 <span class="rating_num" property="v:average">9.6</span>
movieScore = movieDetail.xpath('.//span[@class="rating_num"]/text()')[0]
# 评价人数 <div class="star"><span>1323431人评价</span></div>
movieCommentNum = movieDetail.xpath('.//div[@class="star"]/span/text()')[1]
# 电影短评 <span class="inq">希望让人自由。</span>
movieCommentObj = movieDetail.xpath('.//span[@class="inq"]/text()')
if movieCommentObj:
movieComment = movieCommentObj[0]
else:
movieComment = '无短评'
movieInfo.append((movieName,movieScore,movieCommentNum,movieComment))
return movieInfo
def save_csv(movieInfo):
with open('doc/douban_xpath.csv','w') as f:
writer = csv.writer(f)
writer.writerows(movieInfo)
print('csv文件保存成功......')
if __name__ == '__main__':
doubanTopPage = 10
perPage = 25
movieInfo = []
for page in range(1,doubanTopPage+1):
url = 'https://movie.douban.com/top250?start=%s' %((page-1)*perPage)
content = get_content(url)
parser_content(content)
save_csv(movieInfo)
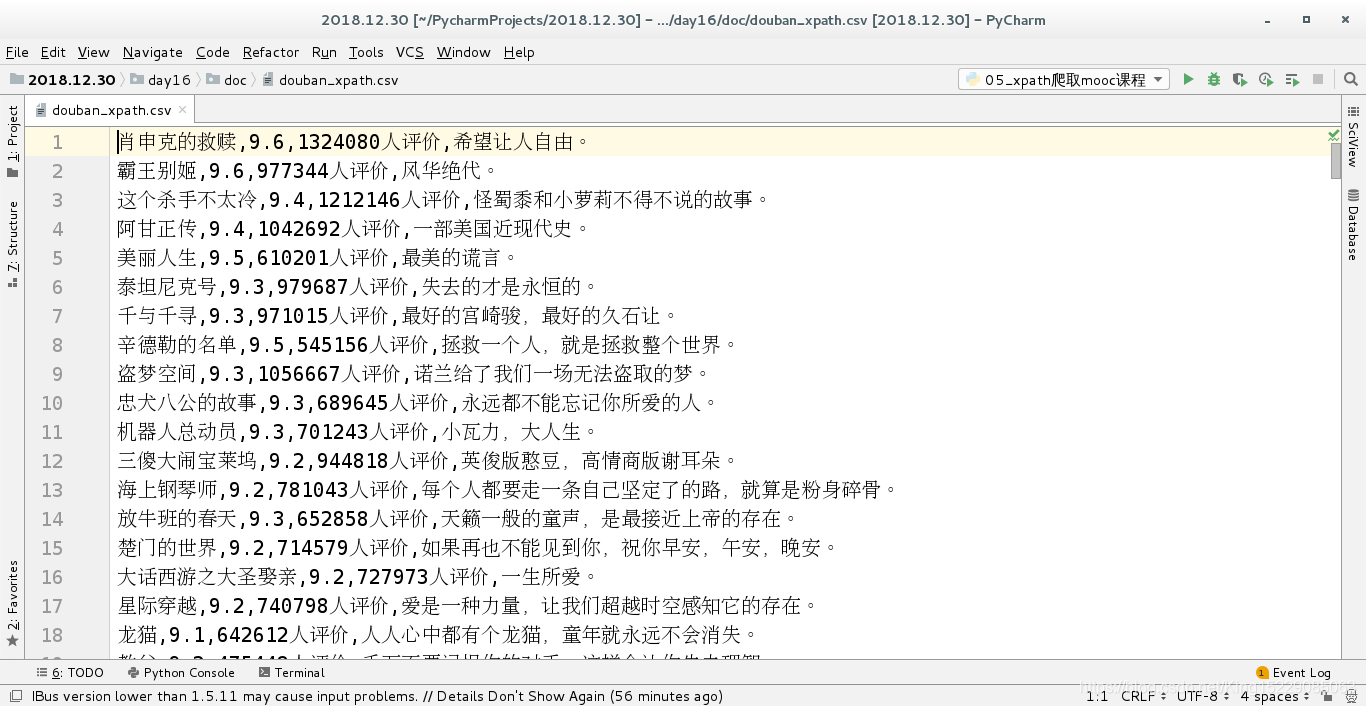
爬取结果保存到csv文件中: