前言:
爬取豆瓣电影TOP250的数据,并将爬取的数据存储于Mysql数据库中
本文为整理代码,梳理思路,验证代码有效性——2020.1.4
环境:
Python3(Anaconda3)
PyCharm
Chrome浏览器
主要模块: 后跟括号内的为在cmd窗口安装的指令
requests(pip install requests)
lxml(pip install lxml)
re
pymysql(pip install pymysql )
time
1.
在Mysql名为mydb的数据库中新建数据表,下为建表语句
CREATE TABLE doubanmovie
(
NAME TEXT,
director TEXT,
actor TEXT,
style TEXT,
country TEXT,
release_time TEXT,
time TEXT,
score TEXT
)
ENGINE INNODB DEFAULT CHARSET = utf8;
2.
分析爬取的网页结构
https://movie.douban.com/top250
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
...
同豆瓣音乐,豆瓣图书的TOP250一样
我们对其构造列表解析式
urls = ['https://movie.douban.com/top250?start={}'.format(str(i))for i in range(0, 250, 25)]
3.
分析html结构,获取详情页链接
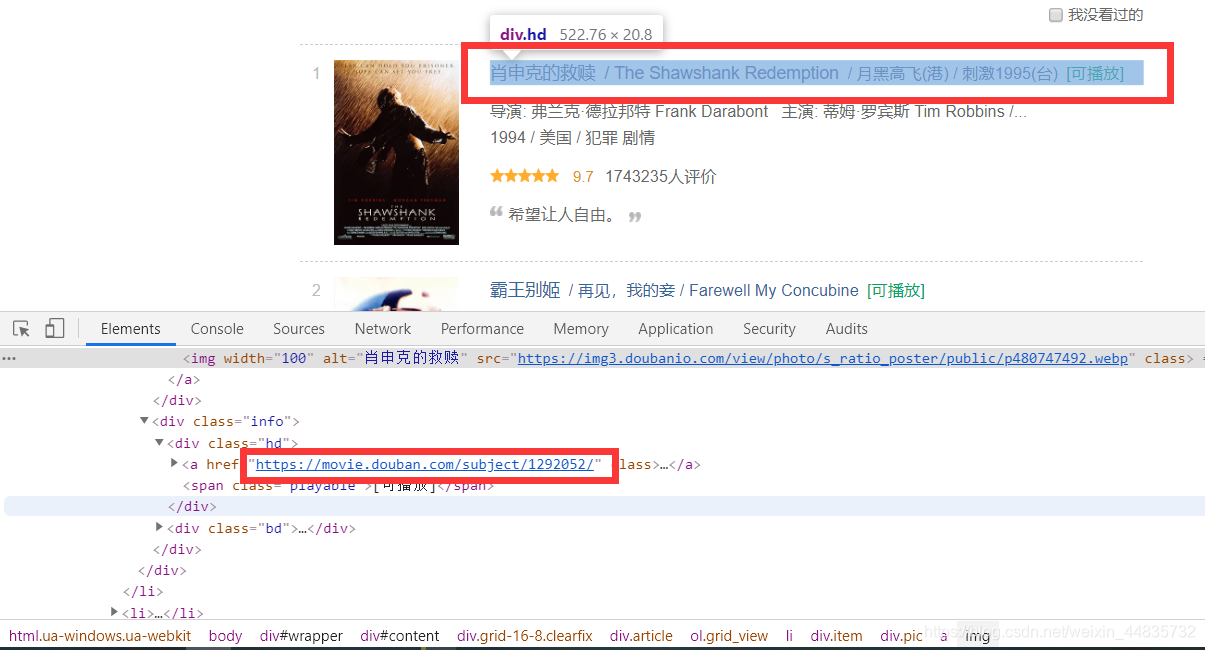
4.
进入详情页后,打开开发者工具(F12),分析html结构获取详细信息

代码如下:
演员取前五个为主演,不足五个的则全取
#标题
name = selector.xpath('//*[@id="content"]/h1/span[1]/text()')[0]
# 导演
director = selector.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')[0]
# 演员
actors_s = selector.xpath('//span[@class="attrs"]/a/text()')
actors = ""
if len(actors_s) > 5:
for s in actors_s[1:5]:
actors += (s + '/')
actors += actors_s[5]
else:
for s in actors_s[-1]:
actors += (s + '/')
actors += actors_s[-1]
# 类型
styles = selector.xpath('//*[@id="info"]/span[@property="v:genre"]/text()')
style = ""
if len(styles) > 1:
for s in styles[:-1]:
style += (s + '/')
style += styles[-1]
else:
style = styles[0]
# 国家
country = re.findall('制片国家/地区:</span>(.*?)<br', html.text, re.S)[0].strip()
# 上映时间
release_time = re.findall('上映日期:</span>.*?>(.*?)\(', html.text, re.S)[0]
# 片长
time = re.findall('片长:</span>.*?>(.*?)</sp', html.text, re.S)[0]
# 评分
score = selector.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0]
5.
将数据保存在Mysql数据库中,有以下“大象装冰箱”三步
- “打开冰箱” 连接数据库及光标
conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='mydb', port=3306, charset='utf8')
cursor = conn.cursor()
- “将大象装进冰箱” 获取信息插入数据库
cursor.execute("insert into doubanmovie (name, director, actor, style, country,release_time, time,score) "
"values(%s, %s, %s, %s, %s, %s, %s, %s)",
(str(name), str(director), str(actors), str(style), str(country),
str(release_time), str(time), str(score)))
- “关上冰箱” 提交事务
conn.commit()
完整代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 导入相应的库文件
import requests
from lxml import etree
import re
import pymysql
import time
# 连接数据库及光标
conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='mydb', port=3306, charset='utf8')
cursor = conn.cursor()
# 加入请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64)AppleWebKit/ 537.36 '
'(KHTML, like Gecko) Chrome/56.0.2924.87 Safari/ 537.36'
}
# 定义获取详细页URL的函数
def get_movie_url(url):
html = requests.get(url, headers=headers)
print(url, html.status_code)
selector = etree.HTML(html.text)
movie_hrefs = selector.xpath('//div[@class="hd"]/a/@href')
for movie_href in movie_hrefs:
# 调用获取详细页信息的函数
get_movie_info(movie_href)
# 定义获取详细页信息的函数
def get_movie_info(url):
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
print(url, html.status_code)
name = selector.xpath('//*[@id="content"]/h1/span[1]/text()')[0]
director = selector.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')[0]
actors_s = selector.xpath('//span[@class="attrs"]/a/text()')
actors = ""
if len(actors_s) > 5:
for s in actors_s[1:5]:
actors += (s + '/')
actors += actors_s[5]
else:
for s in actors_s[-1]:
actors += (s + '/')
actors += actors_s[-1]
styles = selector.xpath('//*[@id="info"]/span[@property="v:genre"]/text()')
style = ""
if len(styles) > 1:
for s in styles[:-1]:
style += (s + '/')
style += styles[-1]
else:
style = styles[0]
country = re.findall('制片国家/地区:</span>(.*?)<br', html.text, re.S)[0].strip()
release_time = re.findall('上映日期:</span>.*?>(.*?)\(', html.text, re.S)[0]
time = re.findall('片长:</span>.*?>(.*?)</sp', html.text, re.S)[0]
score = selector.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0]
# 获取信息插入数据库
cursor.execute("insert into doubanmovie (name, director, actor, style, country,release_time, time,score) "
"values(%s, %s, %s, %s, %s, %s, %s, %s)",
(str(name), str(director), str(actors), str(style), str(country),
str(release_time), str(time), str(score)))
print((name, director, actors, style, country, release_time, time, score))
# 程序主入口
if __name__ == '__main__':
urls = ['https://movie.douban.com/top250?start={}'.format(str(i))for i in range(0, 250, 25)]
for url in urls:
# 构造urls并循环调用函数
get_movie_url(url)
# 睡眠2秒
time.sleep(2)
# 提交事务
conn.commit()
# conn.commit()
print("爬取结束!!!")
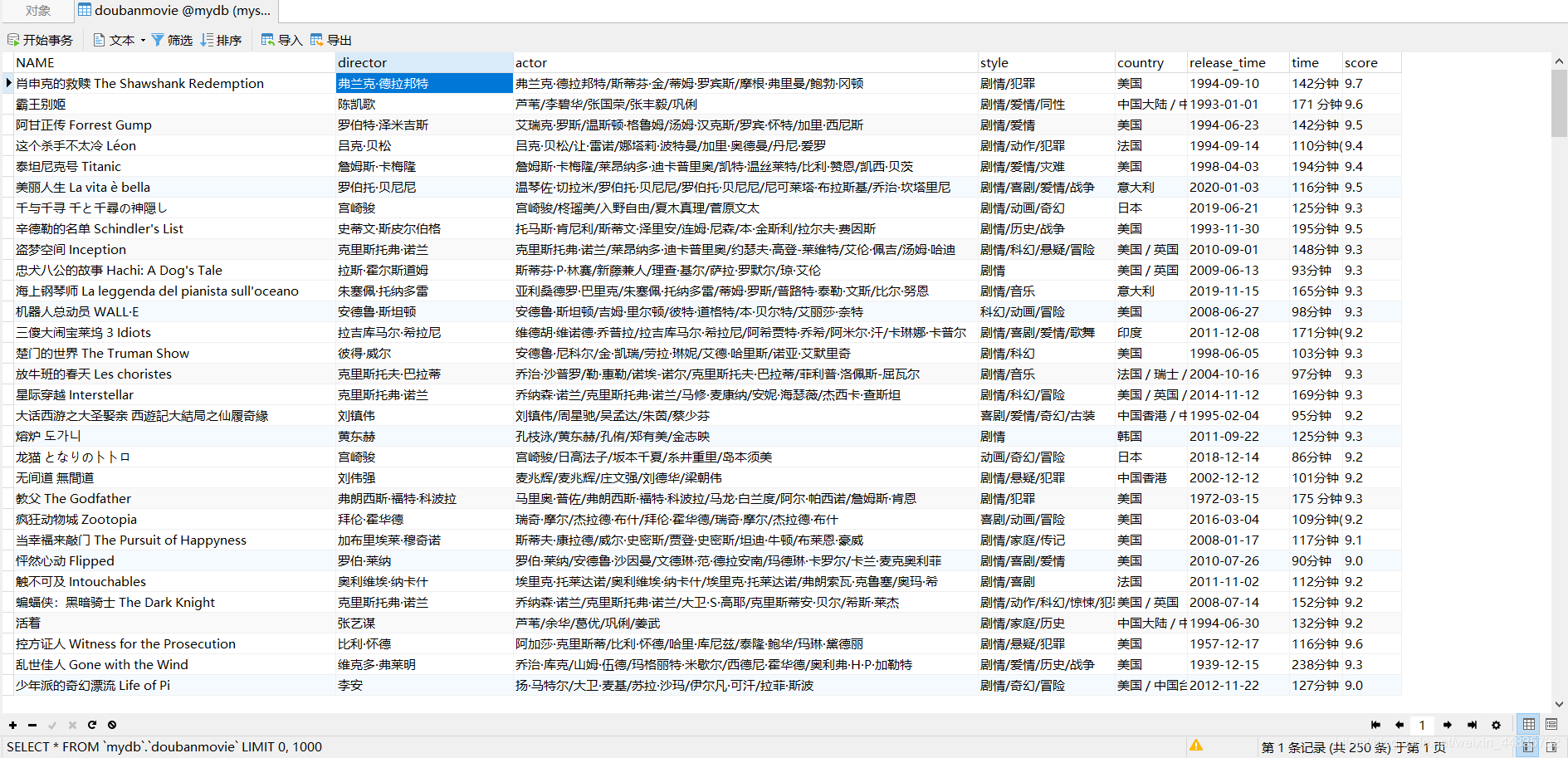
数据截图