一、kNN(k-nearest neighbor)算法原理
事物都遵循物以类聚的思想,即有相同特性的事物在特征空间分布上会靠得更近,所以kNN的思路是:一个样本在特征空间中k个靠的最近的样本中,大多数属于某个类别,这个样本就属于某个类别。
如图所示,蓝色方框和橙色三角分别代表不同的类别,此时来了一个未知类别的样本绿色圆,如何判断绿圆的类别,步骤如下:
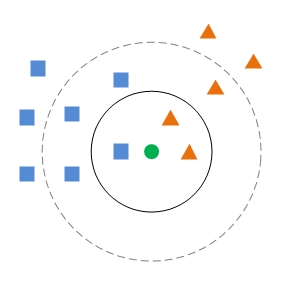
- 计算绿圆和特征空间中的每一个点的距离。
- 设定k的值。
- 选取与当前绿圆距离最近的k个点。
- 统计前k个点所在的类别出现的频率。
- 返回出现频率最高的类别作为绿圆的预测类别。
如果k=3,则距离绿圆最近的三个点是黑色实线圆圈里的点,而橙色三角个数最多,故判断绿圆的类别是橙色三角。
如果k=5,则距离绿圆最近的5个点是黑色虚线圆圈里的点,此时蓝色方框个数最多,故判断绿圆的类别是蓝色方框。
样本点之间距离的一般使用欧氏距离来计算:
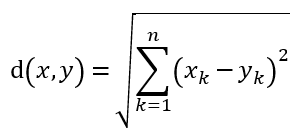
二、kNN算法python实现
- 计算各向量点之间的距离
- 选择距离最小的k个点
- 统计k个点中的类别,并从大到小排序
- 返回出现频率最高的类别
扫描二维码关注公众号,回复:
1454039 查看本文章

目前坐标中有两个黄点类和两个紫点类,需要判断蓝点属于哪个类别?

from numpy import * import operator # knn algorithm def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] # 将inX重复dataSetSize行,便于做向量计算 diffMat = tile(inX, (dataSetSize, 1)) - dataSet sqDiffMat = diffMat ** 2 sqDistinces = sqDiffMat.sum(axis=1) distinces = sqDistinces ** 0.5 # 以上求向量点之间的欧氏距离 # 从小到大返回距离的索引值 sortedDistIndicies = distinces.argsort() # 创建一个字典,用来存放类别和出现的频次 classCount = {} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # classCount.iteritems()={'A': 1, 'B': 2} # 用classCount中iteritems的第二项作为比较的数值(类别的统计频次),然后对iteritems逆序排序 sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0] def createDataSet(): group = array([[10, 11], [9, 8], [2, 3], [3, 1]]) labels = ['A', 'A', 'B', 'B'] return group, labels if __name__ == '__main__': group, labels = createDataSet() classLabel = classify0([3.5, 2], group, labels, 3) print "the classifier came back with: %c" % classLabel
返回的结果是:
the classifier came back with: B
参考资料:《机器学习实战》