机器学习定义
如果一个程序可以在任务T上,随着经验E的增加,效果P也可以随之增加,则称这个程序可以从经验中学习。
机器学习分类
机器学习可以分为以下两类
监督学习(Supervised learning):
通过大量已知的输入和输出相配对的数据,让计算机从中学习出规律,从而能针对一个新的输入作出合理的输出预测。
比如,有大量不同特征(面积、地理位置、朝向、开发商)的房子的价格数据,通过学习这些数据,能预测已知特征的房子价格。这种称为回归学习(Regression learning)即输出结果是一个具体的数值,它的预测模型是一个连续的函数。
再比如我们有大量的邮件,每个邮件都已经标记是否是垃圾邮件。通过学习这些已标记的邮件数据,最后得出一个模型,这个模型对新的邮件,能准确地判断出该邮件是否是垃圾邮件,这种称为分类学习(Classfication learning),即输出结果是离散的,即要么输出1表示是垃圾邮件,要么输出0表示不是垃圾邮件。
无监督学习(Unsupervised learning):
通过学习大量的无标记数据,去分析出数据本身的内在特点和结构。
比如有大量的用户购物的历史记录信息,从数据中去分析用户的不同类别。针对这个问题,最终能划分几个类别?每个类别有哪些特点?这个称为聚类(Clustering)。与分类学习不同,分类问题是已知哪几种类别,聚类问题是不知道有哪些类别。答案是未知的,需要利用算法从数据里挖掘出数据的特点和结构。
两类机器学习的区别:
有监督学习的训练数据里有已知的结果来监督,无监督学习的训练数据里没有结果监督,不知道到底能分析出什么样的结果出来。
机器学习开发步骤
假设,我们要开发一个房价评估系统,对一个已知特征的房子价格进行评估预测。那么需要以下几个步骤
1. 数据采集和标记:需要大量不同特征的房子和对应的价格信息,如面积、地理位置、朝向、价格等。另外还有房子所在地的学校情况。这些数据叫做训练样本,或者数据集。房子的面积、地理位置等称为特征。数据采集阶段,需要收集尽量多的特征。特征越全,数据越多,训练出来的模型越准确。
通过这个过程可以感受到数据采集的成本是很高的。拥有海量数据那么他本身的估值就会很高。
有时候为了避税,房子的评估价格会比房子的真实交易价格低很多。这时,就需要采集房子的实际成交价格,这一过程称为:数据标记。标记可以是人工标记,比如说从房中介打听价格,也可以是自动标记,比如分析数据等。数据标记对监督学习方法是必须的。
2. 数据清洗:假设采集到的数据里,关于房子面积,有按平方米计算的,也有按平方英寸计算的,这时需要对面积单位进行统一。这个过程称为数据清洗。包括去掉复杂的数据及噪声数据,让数据更具备结构化特征。
3. 特征选择:假设采集到100个房子的特征,通过逐个分析这些特征,最终选择了30个特征作为输入。这个过程称为特征选择。特征选择的方法之一是人工选择方法,即对逐个特征进行人员分析,然后选择合适的特征集合。另外一个方法是通过模型来自动完成的,例如PAC算法
4. 模型选择:房价评估系统是属于有监督学习的回归学习类型,可以选择最简单的线性方程来模拟。选择哪些模型,和问题领域、数据量大小、训练时长、模型的准确度等多方面有关。
5. 模型训练和测试:把数据集分成训练数据集和测试数据集。一般按照8:2或7:3来划分,然后用训练数据集来训练模型。训练出参数后再使用测试数据集来测试模型的准确度。单独分出一个测试数据集,是因为必须确保测试的准确性,即模型的准确性是要用没见过的数据来测试,而不能用训练的数据来测试。理论上更合理的数据集划分方案是分成3个,此外还要再加一个交叉验证数据集。
6. 模型性能评估和优化:模型出来后需要对机器学习的算法模型进行性能评估。性能评估包括,训练时长是指
需要花多长时间来训练这个模型。对一些海量数据的机器学习应用,可能需要一个月甚至更长的时间来训练一个模型,这个时候算法的训练性能就变得很重要了。
另外需要判断数据集是否足够多,一般而言,对于复杂特征的系统,训练数据集越大越好。然后还需要判断模型的准确性,即对一个新的数据能否准确地进行预测。最后需要判断模型能否满足应用场景的性能要求,如果不能满足要求,就需要优化,然后继续对模型进行训练和评估,或者更换为其他模型。
7. 模型使用:训练出来的模型可以把参数保存起来,下次使用时直接加载即可,一般来讲,模型训练需要的计算量是很大的,也需要较长时间的训练,因为一个好的模型参数,需要对大型数据集进行训练后才能得到。而真正使用模型时,其计算量是比较小的,一般是直接把新样本作为输入,然后调用模型即可得到预测结果。
开发环境搭建
直接安装Anaconda
IPython
IPython是公认的现代科学计算中最重要的Python工具之一。它是一个加强版的Python交互命令行工具,有以下几个明显的特点:
1. 可以在IPython环境下直接执行Shell指令
2. 可以直接绘图操作的Web GUI环境
3. 更强大的交互功能,包括内省、Tab键自动完成、魔术命令
基础
命令行输入ipython,即可启动交互环境
按Tab键,会自动显示命名空间下的所有开头函数,自动完成
Ctrl + A:移动光标到开头
Ctrl + E:移动光标到结尾
Ctrl + U:删除光标之前的所有字符
Ctrl + K:删除光标之后的所有字符,包含当前字符
Ctrl + L:清屏
Ctrl + P:向后搜索匹配的指令
Ctrl + N:向前搜索匹配的指令
Ctrl + C:终端当前脚本的执行
可以直接在函数或变量后面加上问号?来查询文档
在类或变量、函数后面添加两个问号??,可以查看源码,结合星号 * 和问号 ?,还可以查询命名空间里的所有函数和对象。
魔术命令
%run hello.py 可以直接运行hello.py文件。
%timeit np.dot(a,a) 可以快速评估代码执行效率。
%who 或 %whos命令查看当前环境下的变量列表
%quickref 显示IPython的快速参考文档
%magic 显示所有的魔术命令及其详细文档
%reset 删除当前环境下的所有变量和导入的模块
%logstart 开始记录IPython里的所有输入的命令,默认保存在当前工作目录的ipython_log.py中
%logstop 停止记录,并关闭log文件
需要说明的是,魔术命令后面加上问号 ? 可以直接显示魔术命令的文档。来查看%reset魔术命令的文档
IPython与shell交互的能力,可以让我们不离开IPython环境即可完成很多与操作系统相关的功能。最简单的方法就是在命令前加上叹号!既可以直接运行shell命令。
例如:!ifconfig | grep "inet "
当使用 %automagic on 启用自动魔术命令功能后,可以省略百分号%的输入即可直接运行魔术命令
IPython图形界面
除了控制台环境外,IPython另外一个强大的功能就是图形环境。与控制台环境相比,它有两个显著的特点:
1. 方便编写多行代码
2. 可以直接把数据可视化,显示在当前页面下
安装Jupyter
pip install jupyterjupyter notebook安装完Jupyter后,直接在命令行输入ipython notebook,启动网页版的图形编程界面。会在命令行启动一个轻量级的Web服务器,同时用默认浏览器打开当前目录所在的页面,在这个页面下可以直接打开某个notebook或者创建一个新的notebook。一个notebook是以.ipynb作为后缀名的、基于json格式的文本文件。
我们可以创建一个notebook,并且画一个正弦曲线 jupyter notebook inline.ipynb
# 设置 inline 方式,直接把图片画在页面上
%matplotlib inline
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
# 在[0,2*PI] 之间取100个点
x = np.linspace(0,2*np.pi,num=100)
# 计算这100个点的正弦值,并保存到变量y中
y = np.sin(x)
plt.plot(x,y)
几乎所有的IPython控制台的技巧都可以在IPython notebook里使用。一个比较大的区别是,IPython notebook使用cell作为一个代码单元。控制台里,写完代码直接按Enter键即可运行,而在IPython notebook里需要单击“运行”按钮或用快捷键Ctrl+ Enter才能运行。
notebook有两种模式,一个是编辑模式,可以修改代码。一个是命令模式,输入的按键作为命令。使用Ctrl + M快捷键在模式之间切换。
Numpy简介
Numpy是Python科学计算的基础库,主要提供了高性能的N维数组实现及计算能力,还提供了和其他语言如C/C++集成的能力,此外还实现了一些基础的数学算法,如线性代数相关、傅里叶变换及随机数生成等。
API:https://docs.scipy.org/doc/numpy/genindex.html
Numpy数组
可以直接用Python列表来创建数组
import numpy as np
a = np.array([1, 2, 3, 4])
print(a) # [1 2 3 4]
b = np.array([[1, 2], [3, 4], [5, 6]])
print(b) # [[1 2] [3 4]]
print(b.ndim) # 查看维度:2
print(b.shape) # 查看行、列 (3,2)
print(b.dtype) # 查看类型 int32
c = np.arange(10) # 创建连续数组
print(c) # [0 1 2 3 4 5 6 7 8 9]
d = np.linspace(0, 2, 11) # 将[0,2]切分成11等分之后的数组
print(d) # [0. 0.2 0.4 0.6 0.8 1. 1.2 1.4 1.6 1.8 2. ]
print(np.ones((3, 3))) # 创建3行3列的1数组
np.zeros((3, 6)) # 创建3行3列的0数组
np.eye(4) # 创建4行4列的对角线数组
np.random.randn(6, 3) # 创建6行3列的随机数组
np.random.rand(10) # 创建一个给定维度的数组,并用统一分布的随机样本[0,1]填充它
np.random_integers(1,5,(6,3)) # 创建6行3列的随机整数数组
np.random.normal(0,1,100) # 从正态分布中抽取随机样本
c[3] # 可以通过索引查找
c[:3] # 切片也可以
c[2:8:2] # 表示起始、结束、步长
c[2:: 2] # 可以省略结束为止
c[:: 3] # 开始结束都省略
a = np.arange(0, 51, 10).reshape(6, 1) + np.arange(6) # 创建6行6列的二维数组
a[0, 0] # 访问0行0列
a[:3, 3:] # 访问前三行的后三列
a[2, :] # 访问第2行
a[:, 3] # 访问第三列向量
a[:, ::2] # 访问所有行的步长为2的列
a[::2, ::3] # 访问步长为2的行的步长为3的列
a % 2 == 0 # 判断每一个数组与2取余是否等于0,返回True/False
a[a % 2 == 0] # 每个数与2取余等于0,并输出
Numpy总是试图自动把结果转换为行向量,
Numpy数组是共享内存的,如果需要独立保存,要显示备份。可以使用np.may_share_memory()函数来判断两个数组是否共享内存
如果需要显示备份:a[2:6].copy()
使用埃拉托斯特尼筛法来打印[0,100]之间的所有质数(除了1和它自身外,不能被其他自然数整除的数)。从第一个质数2开始,数据里所有能被2整除的数字都不是质数,即从2开始,以2为步长,每经过的数字能被2整除,标识为非质数。接着,从下一个质数3开始,重复上述过程
import numpy as np
a = np.arange(1, 101)
n_max = int(np.sqrt(len(a))) # 返回平方根
is_prime = np.ones(len(a), dtype=bool)
is_prime[0] = False
for i in range(2, n_max):
if i in a[is_prime]: is_prime[(i * 2 - 1):: i] = False # 省略截止,步长为2 print(a[is_prime])
Numpy运算
最简单的数值计算是数组和标量进行计算,计算过程是直接把数组里的元素和标量逐个进行计算
a = np.arange(6)
print(a * 3)
使用Numpy的优点是运行速度会比较快。
另一种是数组和数组的运算,如果数组的维度相同,那么在组里对应位置进行逐个元素的数学运算
a = np.random.random_integers(1, 5, (5, 4))
b = np.random.randn(5, 4)
print(a + b, a * b)
矩阵乘积应该使用np.dot()函数
a = np.random.random_integers(1, 5, (5, 4))
b = np.random.randn(4, 1)
print(np.dot(a, b))
如果数组的维度不同,Numpy会视图使用广播机制来匹配,如果能匹配上,就进行运算。如果不满足广播条件,则报错
符合广播的条件是两个数组必须有一个维度可以扩展,然后在这个维度上进行复制,最终复制出两个相同维度的数组,再进行运算。
import numpy as np
a = np.random.random_integers(1, 9, (5, 4))
b = np.arange(4)
print(a + b) # 符合广播条件
# 会将b转换为5行4列的向量,其中每一行的内容一致,则相当于同维度相加
数组还可以直接比较,返回一个同维度的布尔数组。针对布尔数组,可以使用all()/any()函数来返回布尔数组的标量值
a = np.array([1, 2, 3, 4])
b = np.array([4, 2, 3, 1])
print(a == b) # [False True True False]
print(a > b) # [False False False True]
print((a == b).all()) # False
print((a == b).any()) # True
Numpy还提供了一些数组运算的内置函数:
np.cos(a) 计算余弦
np.exp(a) 计算所有元素的指数
np.sqrt(a) 计算平方根
还提供了一些基本的统计功能
a.sum() 汇总
a.mean() 平均值
a.std() 标准偏差
a.min()
a.max()
a.argmin() 返回轴上最小值
a.argmax() 返回轴上最大值
针对二维数组或者更高维度的数组,可以根据行或列来计算
b.sum()
b.sum(axis=0)
b.sum(axis=1)
b.sum(axis=1).sum()
b.min(axis=1)
其中axis参数表示坐标轴,0表示按行计算,1表示按列计算。
注意:按列计算后,计算结果Numpy会默认转换为行向量。
随机漫步算法
两个人用一个均匀的硬币来赌博,硬币抛出正面和反面的概率各占一半。硬币抛出正面时甲方输给乙方一块钱,反面时乙方输给甲方一块钱。这种赌博规则下,随着抛硬币次数的增加,输赢的总金额呈现怎么样的分布。
首先让足够多的人两两组成一组参与这个游戏,然后抛出足够多的硬币,就可以统计算出输赢的平均金额。
当使用Numpy实现时,生成多个由-1和1构成的足够长的随机数组,用来代表每次硬币抛出正面和反面的事件。这个二维数组中,每行表示一组参与赌博的人抛出正面和反面的事件序列,然后按行计算这个数组的累加和就是这每组输赢的金额
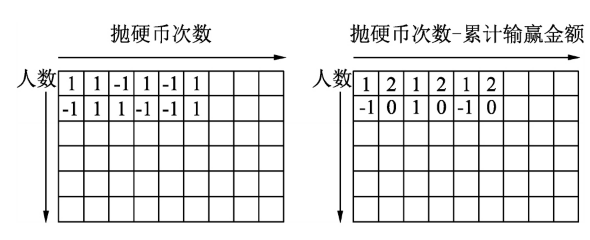
实际计算时,先求出每组输赢金额的平方,再求平均值。最后把平方根的值用绿色的点画在二维坐标上,同时画出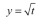 的红色曲线来对比两组曲线的重合情况
的红色曲线来对比两组曲线的重合情况
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
n_person = 2000
n_times = 500
t = np.arange(n_times) steps = 2 * np.random.random_integers(0, 1, (n_person, n_times)) - 1 amount = np.cumsum(steps, axis=1) sd_amount = amount ** 2 mean_sd_amount = sd_amount.mean(axis=0) plt.figure(figsize=(20, 12), dpi=144) plt.xlabel(r"$t$", fontsize=24) plt.tick_params(labelsize=20) plt.ylabel(r"$\sqrt{\langle (\delta x)^2 \rangle}$", fontsize=24) plt.plot(t, np.sqrt(mean_sd_amount), 'g.', t, np.sqrt(t), 'r-');
使用np.reshape() 进行数组维度变换,而np.ravel() 则正好相反,会把多维数组变成一维向量
a= np.arange(12)
b = a.reshape(4,3)
# [[ 0 1 2]
# [ 3 4 5]
# [ 6 7 8]
# [ 9 10 11]]
b.ravel()
添加维度使用np.newaxis
a = np.arange(4)
print(a.shape) # (4,)
b = a[:, np.newaxis]
print(b.shape) # (4, 1)
c = a[np.newaxis, :]
print(c.shape) # (1, 4)
np.sort(a,axis=1) 按行独立排序
a.sort(axis=0) 按列独立排序,并直接把结果给a
Numpy高级功能包括多项式求解以及多项式拟合的功能。np.polyfit() 函数可以用多项式对数据进行拟合。我们生成20个在平方根曲线周围引入随机噪声点,用3阶多项式来拟合这些点。
import matplotlib.pyplot as plt
import numpy as np
n_dots = 20
n_order = 3
x = np.linspace(0, 1, n_dots) # [0,1]之间创建20个点
y = np.sqrt(x) + 0.2 * np.random.rand(n_dots)
p = np.poly1d(np.polyfit(x, y, n_order)) # 用3阶多项式拟合
print(p.coeffs) # 画出拟合出来的多项式所表达的曲线以及原始的点 t = np.linspace(0, 1, 200) plt.plot(x, y, 'ro', t, p(t), '-');
使用Numpy求圆周率π的值。使用的算法是蒙特卡罗方法(Monte Carlo method)其主要思想是,在一个正方形内,用正方形的边长画出一个1/4圆的扇形,假设圆的半径为r,则正方形的面积为r2,圆的面积为1/4π r2,它们的面积之比是π/4
我们在正方形内随机产生足够多的点,计算落在扇形区域内的点的个数与总的点个数的比值。当产生的随机点足够多时,这个比值和面积比值应该是一致的。这样就可以算出π的值。判断一个点是否落在扇形区域的方法是计算这个点到圆心的距离。当距离小于半径时,说明这个点落在扇形内。
import numpy as np
# 假设圆的半径为1,圆心在原点
n_dots = 10000000
x = np.random.random(n_dots)
y = np.random.random(n_dots)
# 随机产生一百万个点
distance = np.sqrt(x ** 2 + y ** 2)
# 计算每个点到圆心的距离
in_circle = distance[distance < 1] # 所有落在扇形内的点 pi = 4 * float(len(in_circle)) / n_dots # 计算出PI的值 print(pi)
Numpy数组作为文本文件,可以直接保存到文件系统里,也可以从文件系统里读取出数据
a = np.arange(15).reshape(3, 5)
np.savetxt('a.txt', a) # 序列化为文本
b = np.loadtxt('a.txt') # 文本反序列化
print(b)
也可以直接保存为Numpy特有的二进制格式
np.save('a.npy', a) # 序列化为文本
b = np.load('a.npy') # 文本反序列化
Pandas简介
Pandas是一个强大的时间序列数据处理工具包,为了分析财经数据,现在已经广泛应用在Python数据分析领域中。
Pandas最基础的数据结构是Series,用它来表达一行数据,可以理解为一维的数组。比如创建一个包含6个数据的一维数组
s = pd.Series([4, 2, 5])
# 0 4
# 1 2
# 2 5
# dtype: int64
另一个关键的数据结构为DataFrame,表示是二维数组。下面的代码创建一个DataFrame对象
df = pd.DataFrame(np.random.rand(6, 4), columns=list('ABCD'))
# A B C D
# 0 0.584111 0.186057 0.204064 0.519430
# 1 0.645679 0.405943 0.032989 0.897339
# 2 0.898421 0.757804 0.948457 0.145658
# 3 0.502044 0.925613 0.599234 0.220672
# 4 0.432294 0.039789 0.577377 0.954598
# 5 0.274313 0.443114 0.416644 0.604243
DataFrame里的数据实际是Numpy的array对象来保存的,读者可以输入df.values来查看原始数据。DataFrame对象的每一行和列都是一个Series对象。可以使用行索引来访问一个行数,可以用列名称来索引一列数据
df.iloc[0] 行索引
df.A 列索引
df.shape 查看维度
df.head(3) 访问前三行
df.tail(3) 访问后三行
df.index 访问数据的行索引
df.columns 访问数据的列索引
df.describe() 计算简单的数据统计信息(可以计算出个数、平均值、标准差、最小值、最大值)
df.sort_index(axis=1,ascending=False) 可以进行列名称倒序
df.sort_values(by='B') 对B列数值进行排序
df[3:5] 索引范围访问
df[['A','B','C']] 选择3列数据
df.loc[3,'A'] 选择3行的A列
df.iloc[3,0] 通过数组索引来访问
df.iloc[2:5,0:2] 通过索引
df[df.c > 0] 插入布尔值
df["D"] = ["A","B"] 添加一列
df.groupby("D").sum() 分组
Pandas提供了时间序列处理能力,可以创建以时间序列为索引的数据集
import numpy as np
import pandas as pd
n_items = 366
ts = pd.Series(np.random.rand(n_items), index=pd.date_range('20000101', periods=n_items))
print(ts.shape) # (366,)
print(ts.head(5))
# 2000-01-01 0.523365
# 2000-01-02 0.127577
# 2000-01-03 0.914436
# 2000-01-04 0.474645
# 2000-01-05 0.098926
# Freq: D, dtype: float64
# 按照月份聚合
print(ts.resample("1m").sum()) # 2000-01-31 14.488162 # 2000-02-29 16.219371 # 2000-03-31 14.601253
数据可视化
% matplotlib inline
# 导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
n_items = 366
ts = pd.Series(np.random.rand(n_items), index=pd.date_range('20000101', periods=n_items)) plt.figure(figsize=(10,6),dpi=144) cs = ts.cumsum() cs.plot()
文件读写
import numpy as np
import pandas as pd
n_items = 366
ts = pd.Series(np.random.rand(n_items), index=pd.date_range('20000101', periods=n_items))
ts.to_csv('data.csv') # 写入
df = pd.read_csv('data.csv', index_col=0) # 读取
print(df.shape)
print(df.head(5))
Matplotlib
Matplotlib是Python数据可视化工具包,
如果要在IPython控制台使用,可以使用ipython--matplotlib来启动
如果要在IPython notebook使用,需要开始位置插入
% matplotlib inline
并且进入包
from matplotlitb import pyplot as plt
在机器学习领域中,经常需要把数据可视化,以便观察数据的模式。对算法性能评估时,也需要把模型相关的数据可视化,才能观察出需要改进的地方。
图形样式
默认样式的坐标轴上画出正弦和余弦
% matplotlib inline
from matplotlib import pyplot as plt
import numpy as np
x = np.linspace(-np.pi, np.pi, 200)
C, S = np.cos(x), np.sin(x)
plt.plot(x, C) # 余弦
plt.plot(x, S) # 正弦
plt.show()
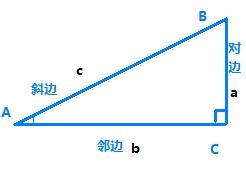
正弦值是在直角三角形中,对边的长比上斜边的长的值。sinA=∠A的对边/斜边=a/c
余弦值是在直角三角形中,邻边比三角形的斜边的值,cosA=b/c,也可写为cosa=AC/AB
画出来的图形如下

接着可以通过修改默认样式,来变成右边的正余弦曲线
% matplotlib inline
from matplotlib import pyplot as plt
import numpy as np
X = np.linspace(-np.pi, np.pi, 200, endpoint=True)
C, S = np.cos(X), np.sin(X)
# 画出余弦/正弦
plt.plot(X, C, color="blue", linewidth=2.0, linestyle="-") plt.plot(X, S, color="red", linewidth=2.0, linestyle="-") # 设置坐标轴的长度 plt.xlim(X.min() * 1.1, X.max() * 1.1) plt.ylim(C.min() * 1.1, C.max() * 1.1) # 重新设置坐标轴的刻度、X轴自定义标签 plt.xticks((-np.pi, -np.pi/2, np.pi/2, np.pi), (r'$-\pi$', r'$-\pi/2$', r'$+\pi/2$', r'$+\pi$')) plt.yticks([-1, -0.5, 0, 0.5, 1]) # 左侧图片的4个方向坐标改为两个方向的交叉坐标 # 方法通过设置颜色为透明色,把上方和右侧的坐标线隐藏 # 移动左侧和下方的坐标边线到原点(0,0)的位置 ax = plt.gca() # 获取当前坐标轴 ax.spines['right'].set_color('none') # 隐藏右侧坐标轴 ax.spines['top'].set_color('none') ax.xaxis.set_ticks_position('bottom') # 设置刻度显示到下方 ax.spines['bottom'].set_position(('data', 0)) # 设置下方坐标轴的位置 ax.yaxis.set_ticks_position('left') ax.spines['left'].set_position(('data', 0)) # 设置左侧坐标轴位置 # 在余弦去线上标识出这个点,同时用虚线画出对应的X轴坐标 # 在坐标轴上标示相应的点 t = 2 * np.pi / 3 # 画出 cos(t) 所在的点在 X 轴上的位置,即画出 (t, 0) -> (t, cos(t)) 线段,使用虚线 plt.plot([t, t], [0, np.cos(t)], color='blue', linewidth=1.5, linestyle="--") # 画出标示的坐标点,即在 (t, cos(t)) 处画一个大小为 50 的蓝色点 plt.scatter([t, ], [np.cos(t), ], 50, color='blue') # 画出标示点的值,即 cos(t) 的值 plt.annotate(r'$cos(\frac{2\pi}{3})=-\frac{1}{2}$', xy=(t, np.cos(t)), xycoords='data', xytext=(-90, -50), textcoords='offset points', fontsize=16, arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2")) # 画出 sin(t) 所在的点在 X 轴上的位置,即画出 (t, 0) -> (t, sin(t)) 线段,使用虚线 plt.plot([t, t], [0, np.sin(t)], color='red', linewidth=1.5, linestyle="--") # 画出标示的坐标点,即在 (t, sin(t)) 处画一个大小为 50 的红色点 plt.scatter([t, ], [np.sin(t), ], 50, color='red') # 画出标示点的值,即 sin(t) 的值 plt.annotate(r'$sin(\frac{2\pi}{3})=\frac{\sqrt{3}}{2}$', xy=(t, np.sin(t)), xycoords='data', xytext=(+10, +30), textcoords='offset points', fontsize=16, arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2")) # plt.annotate函数的功能时在图片上画出标示文本 # 定制坐标轴上的刻度标签字体,在刻度标签上添加一个半透明的背景 for label in ax.get_xticklabels() + ax.get_yticklabels(): label.set_fontsize(16) label.set_bbox(dict(facecolor='white', edgecolor='None', alpha=0.65)) plt.show()
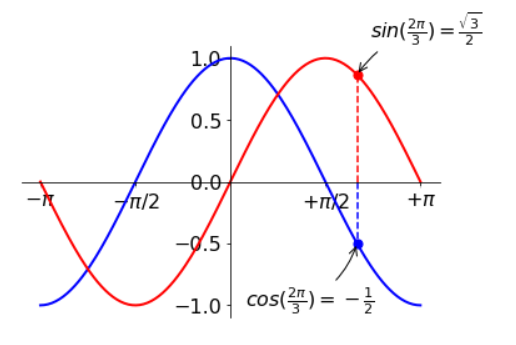
图形对象
在Matplotlib里,一个图形是指图片的全部可视区域,可以使用plt.figure来创建。在一个图形里,可以包含多个子图,可以使用plt.subplot() 来创建子图。子图按照网络形状排列显示在图形里,可以在每个子图上单独作画。。坐标轴和子图类似,唯一不同的是,坐标轴可以在图形上任意拜访,而不需要按照网络排列,这样显示起来更灵活,可以使用plt.axes()来创建坐标轴
当使用默认配置作画时,Matplotlib调用plt.gac()函数来获取当前的坐标轴,并在当前坐标轴上作画。plt.gac()函数调用plt.gcf函数来获取当前图形对象,如果当前不存在图形对象会调用plt.figure()函数创建要一个图形对象
plt.figure函数有几个常用的参数
num:图形对象的标识符,可以是数字或字符串。
figsize:以英寸为单位的图形大小,是一个元组
dpi:指定图形的质量,每英寸多少个点
下面的代码创建了两个图形,一个是sin,并且把正弦曲线画在这个图形上。然后创建了一个名称是cos的图形,并且把余弦曲线画在这个图形上。接着切换到之前创建的sin图形上,把余弦图片画在这个图形上
from matplotlib import pyplot as plt
import numpy as np
X = np.linspace(-np.pi, np.pi, 200, endpoint=True)
C, S = np.cos(X), np.sin(X)
plt.figure(num='sin', figsize=(16, 4))
plt.plot(X, S)
plt.figure(num='cos', figsize=(16, 4)) plt.plot(X, C) plt.figure(num='sin') plt.plot(X, C) print(plt.figure(num='sin').number) print(plt.figure(num='cos').number)
不同的图形可以单独保存为一个图片文件,但子图是指一个图形里分成几个区域,在不同的区域里单独作画,所有的子图最终都保存在一个文件里。plt.subplot()函数的关键参数是一个包含三个元素的元组,分别代表子图的行、列以及当前激活的子图序号。比如plt.subplot(2,2,1)表示把图标对象分成两行两列,激活的一个子图来作画
from matplotlib import pyplot as plt
plt.figure(figsize=(18, 4))
plt.subplot(2, 2, 1)
plt.xticks(())
plt.yticks(())
plt.text(0.5, 0.5, 'subplot(2,2,1)', ha='center', va='center', size=20, alpha=.5)
plt.subplot(2, 2, 2)
plt.xticks(())
plt.yticks(())
plt.text(0.5, 0.5, 'subplot(2,2,2)', ha='center', va='center', size=20, alpha=.5) plt.tight_layout() plt.show()
更复杂的子图布局,可以使用gridspec来实现,优点是可以指定某个子图横跨多个列或多个行
from matplotlib import pyplot as plt
import matplotlib.gridspec as gridspec
plt.figure(figsize=(18, 4))
G = gridspec.GridSpec(3, 3)
axes_1 = plt.subplot(G[0, :]) # 占用第一行
plt.xticks(())
plt.yticks(())
plt.text(.5, .5, 'Axes 1', ha='center', va='center', size=24, alpha=.5) axes_2 = plt.subplot(G[1:, 0]) # 占用第二行开始之后的所有行,第一列 plt.xticks(()) plt.yticks(()) plt.text(0.5, 0.5, 'Axes 2', ha='center', va='center', size=24, alpha=.5) axes_3 = plt.subplot(G[1:, -1]) # 占用第二行开始之后的所有行,最后一列 plt.xticks(()) plt.yticks(()) plt.text(0.5, 0.5, 'Axes 3', ha='center', va='center', size=24, alpha=.5) axes_4 = plt.subplot(G[1, -2]) # 占用第二行,倒数第二列 plt.xticks(()) plt.yticks(()) plt.text(0.5, 0.5, 'Axes 4', ha='center', va='center', size=24, alpha=.5) axes_5 = plt.subplot(G[-1, -2]) # 占用倒数第一行,倒数第二列 plt.xticks(()) plt.yticks(()) plt.text(0.5, 0.5, 'Axes 5', ha='center', va='center', size=24, alpha=.5) plt.tight_layout() plt.show()

使用坐标轴plt.axes()来创建,可以给矩形进行定位 plt.axes([.1,.1,.8,.8])
画图操作
绘制一个点分布图,需要使用plt.scatter()函数。np.arctan2(Y,X) 计算随机点的反正切,这个值作为随机点的颜色。
import numpy as np
from matplotlib import pyplot as plt
n = 1024 # 定义点数量
X = np.random.normal(0, 1, n)
Y = np.random.normal(0, 1, n)
T = np.arctan2(Y, X)
plt.figure(figsize=(18, 4)) plt.subplot(1, 2, 1) plt.scatter(X, Y, s=75, c=T, alpha=.5) plt.xlim(-1.5, 1.5) plt.xticks(()) plt.ylim(-1.5, 1.5) plt.yticks(())

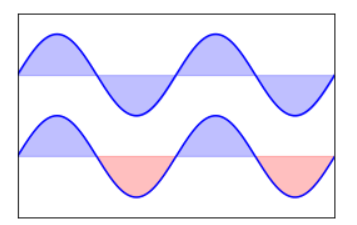
使用plt.fill_between()函数,可以画出正弦曲线。并在直线和曲线之间填充指定的颜色
import numpy as np
from matplotlib import pyplot as plt
n = 256
X = np.linspace(-np.pi, np.pi, n, endpoint=True)
Y = np.sin(2*X)
plt.figure(figsize=(10, 3)) plt.subplot(1, 2, 2) plt.plot(X, Y+1, color="blue", alpha=1.00) plt.fill_between(X, 1, Y+1, color="blue", alpha=.25) plt.plot(X, Y-1, color="blue", alpha=1.00) plt.fill_between(X, -1, Y-1, (Y-1) > -1, color="blue", alpha=.25) plt.fill_between(X, -1, Y-1, (Y-1) < -1, color="red", alpha=.25) plt.xlim(-np.pi, np.pi) plt.xticks(()) plt.ylim(-2.5, 2.5) plt.yticks(())
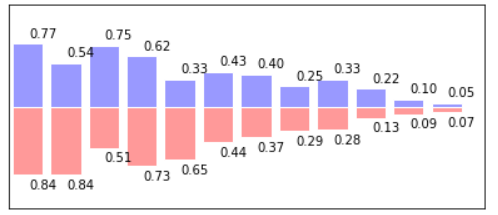
使用plt.bar()函数可以画出柱状图。生成24个随机值,调用两次plt.bar() 分别画在上下两侧。在调用plt.text()函数把数值画在对应的柱状图上。
import numpy as np
from matplotlib import pyplot as plt
n = 12
X = np.arange(n)
Y1 = (1-X/float(n)) * np.random.uniform(0.5, 1.0, n)
Y2 = (1-X/float(n)) * np.random.uniform(0.5, 1.0, n) plt.figure(figsize=(15, 3)) plt.subplot(1, 2, 1) plt.bar(X, +Y1, facecolor="#9999ff", edgecolor="white") plt.bar(X, -Y2, facecolor="#ff9999", edgecolor="white") for x, y in zip(X, Y1): plt.text(x+0.4, y+0.05, '%.2f' % y, ha='center', va='bottom') for x, y in zip(X, Y2): plt.text(x+0.4, -y-0.05, '%.2f' % y, ha='center', va='top') plt.xlim(-.5, n) plt.xticks(()) plt.ylim(-1.25, 1.25) plt.yticks(())
使用plt.contourf() 函数填充等高线,命名参数cmap表示颜色映射风格。plt.contour()函数画出等高线。plt.clable()画出等高线上的数字
import numpy as np
from matplotlib import pyplot as plt
def f(x, y):
return (1 - x / 2 + x ** 5 + y ** 3) * np.exp(-x ** 2, -y ** 2)
n = 256
x = np.linspace(-3, 3, n) y = np.linspace(-3, 3, n) X, Y = np.meshgrid(x, y) plt.figure(figsize=(30, 10)) plt.subplot(1, 2, 2) plt.contourf(X, Y, f(X, Y), 8, alpha=.75, cmap=plt.cm.hot) c = plt.contour(X, Y, f(X, Y), 8, colors="black", linewidth=.5) plt.clabel(c, inline=1, fontsize=10) plt.xticks(()) plt.yticks(())

使用plt.imshow()函数把数组当成图片画出来
import numpy as np
from matplotlib import pyplot as plt
def f(x, y):
return (1 - x / 2 + x ** 5 + y ** 3) * np.exp(-x ** 2, -y ** 2)
plt.subplot(1, 2, 1)
n = 10 x = np.linspace(-3, 3, 4 * n) y = np.linspace(-3, 3, 3 * n) X, Y = np.meshgrid(x, y) plt.imshow(f(X, Y), cmap="hot", origin="low") plt.colorbar(shrink=.83) plt.xticks(()) plt.yticks(())

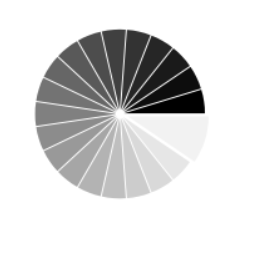
使用plt.pie()函数画出饼图
import numpy as np
from matplotlib import pyplot as plt
plt.subplot(1, 2, 2)
n = 20
Z = np.ones(n)
Z[-1] *= 2 plt.pie(Z, explode=Z*.05, colors=['%f' % (i/float(n)) for i in range(n)]) plt.axis('equal') plt.xticks(()) plt.yticks()
使用坐标轴set_major_locator()和set_minor_locator()把坐标刻度设置成MultipleLocator央视。然后使用grid()函数在刻度刻画线段。这样就生成了网格
from matplotlib import pyplot as plt
ax = plt.subplot(1,2,1)
ax.set_xlim(0,4)
ax.set_ylim(0,3)
ax.xaxis.set_major_locator(plt.MultipleLocator(1.0))
ax.xaxis.set_major_locator(plt.MultipleLocator(0.1)) ax.yaxis.set_major_locator(plt.MultipleLocator(1.0)) ax.yaxis.set_major_locator(plt.MultipleLocator(0.1)) ax.grid(which="major",axis="x",linewidth=0.75,linestyle="-",color="0.75") ax.grid(which="minor",axis="x",linewidth=0.25,linestyle="-",color="0.75") ax.grid(which="major",axis="y",linewidth=0.75,linestyle="-",color="0.75") ax.grid(which="minor",axis="y",linewidth=0.25,linestyle="-",color="0.75") ax.set_xticklabels([]) ax.set_yticklabels([])

使用plt.bar()和bar.set_facecolor()来填充不同的颜色,可以做出极坐标图
import numpy as np
from matplotlib import pyplot as plt
ax = plt.subplot(1, 2, 2, polar=True)
N = 20
theta = np.arange(0.0, 2*np.pi, 2*np.pi/N)
radii = 10 * np.random.rand(N) width = np.pi / 4 * np.random.rand(N) bars = plt.bar(theta, radii, width=width, bottom=0.0) for r, bar in zip(radii, bars): bar.set_facecolor(plt.cm.jet(r/10.)) bar.set_alpha(0.5) ax.set_xticklabels([]) ax.set_yticklabels([])

Scikit-learn简介
scikit-lear是一个开源的Python语言机器学习工具包,涵盖了几乎所有主流机器学习算法的实现,并且提供了一致的调用接口。
给予Numpy和scipy等Python数值计算库,提供了高效的算法实现。优点有以下几点
文档齐全:官方文档齐全,更新及时
接口易用:针对所有的算法提供了一致的接口调用规则
算法全面:涵盖了主流机器学习任务的算法,包括回归算法、分类算法、聚类分析、数据降维处理等
scikit-learn不支持分布式计算,不适用用来处理超大型数据。
数字识别示例
监督学习,数据是标记过的手写数字图片。通过采集足够多的手写数字样本,选择合适的模型,并使用采集到的数据进行模型训练,,最后验证识别程序的正确性。
1. 数据采集和标记
scikit-learn自带了一些数据集,其中一个是手写数字识别图片的数据,使用以下代码来加载并显示出来
from sklearn import datasets
from matplotlib import pyplot as plt
# 加载数据
digits = datasets.load_digits()
# 可以在notebook环境把数据的图片用Matchplotlib显示出来
images_and_labels = list(zip(digits.images, digits.target))
plt.figure(figsize=(8, 6), dpi=200)
for index, (image, label) in enumerate(images_and_labels[:8]): plt.subplot(2, 4, index+1) plt.axis('off') plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest') plt.title('Digit:%i' % label, fontsize=20)

图片就是一个个手写的数字
2. 特征选择
针对手写的图片,最直接的方法是使用图片的每个像素点作为一个特征。比如图片是200*200的分辨率,那么就有40000个特征了,及特征向量的长度是40000
实际上,scikit使用Numpy的array对象来表示数据,所有的图片数据保存在digits.images里,每个元素都是一个88尺寸的灰阶图片。我们在进行机器学习时,需要把数据保存为样本个数x特征个数的array对象,针对手写数字识别这个案例,scikit已经为我们转换好了,就保存在digits.data数据里,可以通过digits.data.shape来查看它们的数据格式
print("shape of raw image data:{0}".format(digits.images.shape)) # (1797, 8, 8)
print("shape of data: {0}".format(digits.data.shape)) # (1797, 64)
总共有1797个训练样本,其中原始的数据是8*8的图片,而寻来你的数据是把图片的64个像素点都转换为特征。
3. 数据清洗
人们不可能在8*8这种分辨率上写数字,在采集的时候是让用户在一个大图片上写数字。但是如果图片是200*200,那么一个训练样例就有40000个特征,计算量将是巨大的。为了减少计算量,也为了模型的稳定性,需要把200*200图片缩小为8*8。这个过程就是数据清洗,把不适合用来做训练的数据进行预处理,从而转换为适合的数据。
4. 模型选择
不同的机器学习算法针对特定的机器学习应用有不同的效率,模型的选择和验证留到后面章节详细介绍。这里使用支持向量机(SVM)
5. 模型训练
首先需要把数据分为训练数据集和测试数据集。使用8:2的划分。接着使用训练数据集进行训练,完成后clf就会包含我们训练出来的模型参数,使用这个模型对象进行预测即可。
from sklearn import datasets, svm
from sklearn.model_selection import train_test_split
# 加载数据
digits = datasets.load_digits()
# 把数据分成训练数据集和测试数据集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(digits.data, digits.target, test_size=0.20, random_state=2)
# 接着使用训练数据集来训练模型
clf = svm.SVC(gamma=0.001, C=100.)
clf.fit(Xtrain, Ytrain)
6. 模型测试
我们用训练出来的模型测试一下准确度,可以直接把预测结果和真实结果做比较。scikit提供了现成的比较方法
from sklearn import datasets, svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from matplotlib import pyplot as plt
# 加载数据
digits = datasets.load_digits()
# 把数据分成训练数据集和测试数据集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(digits.data, digits.target, test_size=0.20, random_state=2) # 接着使用训练数据集来训练模型 clf = svm.SVC(gamma=0.001, C=100.) clf.fit(Xtrain, Ytrain) # 评估模型的准确度 Ypred = clf.predict(Xtest) accuracy_score(Ytest, Ypred)
模型的准确率大概97.8%
除此之外,可以直接把测试数据集里的部分图片显示出来,并且在左下角显示预测值,右下角显示真实值。
% matplotlib inline
from sklearn import datasets, svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from matplotlib import pyplot as plt
# 加载数据
digits = datasets.load_digits() # 把数据分成训练数据集和测试数据集 Xtrain, Xtest, Ytrain, Ytest = train_test_split(digits.data, digits.target, test_size=0.20, random_state=2) # 接着使用训练数据集来训练模型 clf = svm.SVC(gamma=0.001, C=100.) clf.fit(Xtrain, Ytrain) # 评估模型的准确度 Ypred = clf.predict(Xtest) accuracy_score(Ytest, Ypred)
clf.scroe(Xtest,Ytext) # 两个一样 # 查看预测情况 fig, axes = plt.subplots(4, 4, figsize=(8, 8)) fig.subplots_adjust(hspace=0.1, wspace=0.1) for i, ax in enumerate(axes.flat): ax.imshow(Xtest[i].reshape(8, 8), cmap=plt.cm.gray_r, interpolation='nearest') ax.text(0.05, 0.05, str(Ypred[i]), fontsize=32, transform=ax.transAxes, color="green" if Ypred[i] == Ytest[i] else 'red') ax.text(0.8, 0.05, str(Ytest[i]), fontsize=32, transform=ax.transAxes, color="black") ax.set_xticks([]) ax.set_yticks([])

7. 模型保存与加载
当我们对模型的准确度感到满意后,就可以把模型保存下来。这样下次需要预测时,可以直接加载模型进行预测,而不是重新训练一遍模型。可以使用下面的代码来保存模型:
# 保存模型参数
from sklearn.externals import joblib
joblib.dump(clf, 'digits_svm.pk1')
在我们使用的时候,就可以直接加载成clf使用
from sklearn import datasets
from sklearn.externals import joblib
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# 加载数据
digits = datasets.load_digits()
# 把数据分成训练数据集和测试数据集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(digits.data, digits.target, test_size=0.20, random_state=2) clf = joblib.load('digits_svm.pk1') Ypred = clf.predict(Xtest) print(accuracy_score(Ytest, Ypred))
Scikit-Learn一般性原理和通用规则
scikit包含大部分流行的监督学习算法(分类和回归)和无监督学习算法(聚类和数据降维)的实现
1. 评估模型对象
scikit里的所有算法都以一个评估模型对象来创建对外提供接口。上面的svm.SVC()函数返回的就是一个支持向量机评估模型对象。
创建评估模型对象时,可以指定不同的参数,这个称为评估对象参数,评估对象参数直接影响评估模型训练时的效率以及准确性。
学习机器学习算法的原理,其中一项非常重要的任务就是了解不同的机器学习算法有哪些可调的参数,这些参数代表什么意思。
对机器学习算法的性能以及准确性有没有什么影响。因为在工程应用上,要从头实现一个机器学习算法的可能性很低,除非是数值计算科学家。更多情况下,是分析采集到的数据,根据数据特征选择合适的算法,并且调整算法的参数,从而实现算法效率和准确度之间的平衡。
2. 模型接口
scikit所有的评估模型对象都有fit()这个接口,是用来训练模型的接口。针对有监督学习的机器学习,使用fit(X,y)来进行训练,其中y是标记数据。针对无监督的机器学习算法,使用fit(X)来进行训练,因为无监督机器学习算法的数据集是没有标记的,不需要传入y。
针对所有的监督学习算法,scikit模型对象提供了predict()接口,经过训练的模型,可以用这个接口来进行预测。针对分类问题,有些模型还提供了predict_proba()的接口,用来输出一个待预测的数据,属于各种类型的可能性,而predict()接口直接返回了可能性最高的那个类别。
几乎所有的模型都提供了scroe()接口来评价一个模型的好坏,得分越高越好。不是所有的问题都只有准确度这个评价标准,比如异常检测系统,一些产品不良率可以控制到10%以下,这个时候最简单的模型是无条件地全部预测为合格,即无条件返回1,其准确率将达99.999%以上,但实际上这是一个不好的模型。评价这种模型,就需要使用查准率和召回率来衡量。
针对无监督的机器学习算法,scikit的模型对象也提供了predict()接口,用来对数据进行聚类分析,把新数据归入某个聚类里。无监督学习算法还有transform()接口,这个接口用来进行转换,比如PCA算法对数据进行降维处理时,把三维数据降为二维数据,此时调用transform()算法即可把一个三维数据转换为对应的二维数据。
模型接口也是scikit工具包的最大优势之一,即把不同的算法抽象出来,对外提供一致的接口调用。
3. 模型检验
机器学习应用开发的一个非常重要的方面就是模型检验,需要检测我们训练出来的模型,针对陌生数据其预测准确性如何。除了模型提供的score()接口外,在sklearn.metrics包的下面还有一系列用来检测模型性能的方法。
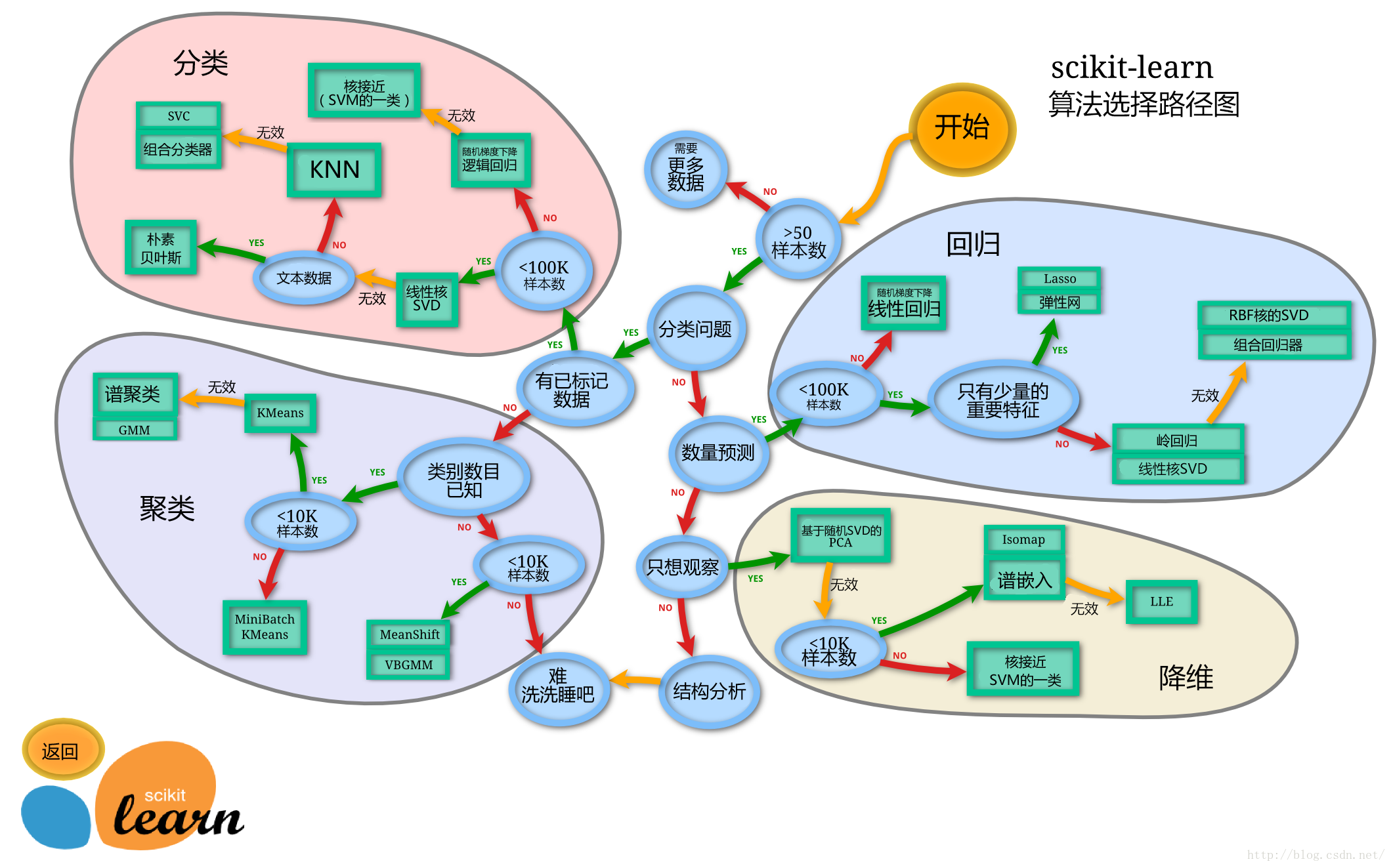
4. 模型选择
模型选择是个非常重要的课题,根据要处理的问题性质,数据是否经过标记。数据规模多大,等等这些问题,可以对模型有个初步的选择。下面两个图是速查表,可以快速选择要给相对合适的模型。
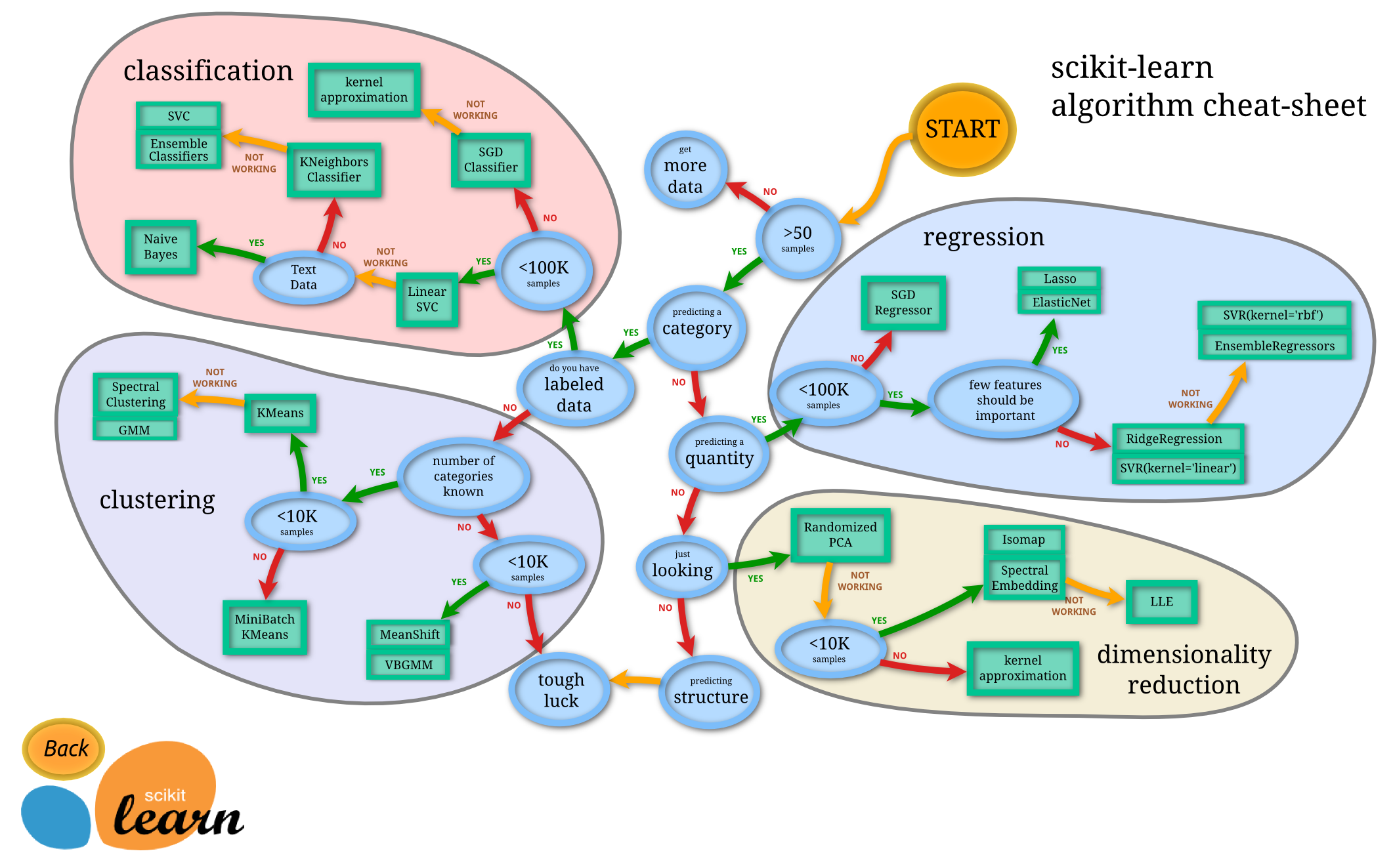
机器学习理论基础
过拟合和欠拟合
拟合:指已知某函数的若干离散函数值{f1,f2,…,fn},通过调整该函数中若干待定系数f(λ1, λ2,…,λn),使得该函数与已知点集的差别(最小二乘意义)最小。
离散:连续的对应(就是反义词)就是离散 。离散就是不连续。比如人眼看到的图片,就是连续的。计算机里的照片就是离散的二进制比特流,图像(灰度图像)像素的灰度值在计算机里是从0到255(实际上是用二进制表示的),即0,1,2,3,...,255,0代表黑色,255代表白色,只有0到255的整数,没有其他整数,而且没有两个整数之间的小数,即不连续的,这就叫离散。
过拟合是指模型能很好地拟合训练样本, 但对新数据的预测准确性很差。欠拟合是指模型不能很好的拟合训练样本,且对新数据的预测准确性也不好。
n_dots = 20
x = np.linspace(0, 1, n_dots)
y = np.sqrt(x) + 0.2 * np.random.rand(n_dots) - 0.1
训练样本是 ,其中r是[-0.1,0.1] 之间的一个随机数。
,其中r是[-0.1,0.1] 之间的一个随机数。
然后分别用一阶多项式、三阶多项式、十阶多项式3个模型来拟合这个数据集,得到的结果如下
多项式(polynomial)是指由变量、系数以及它们之间的加、减、乘、幂运算(非负整数次方)得到的表达式。

图中的点是我们生成的20个训练样本。虚线为实际的模型,实线是用训练样本拟合出来的模型
左侧是欠拟合(underfitting),也称高偏差(high bias),因为试图用一条直线来拟合样本数据。
右侧是过拟合(overfitting),也称高方差(high variance),用了十阶多项式来拟合数据,虽然模型对现有的数据集拟合的很好,但对新数据预测误差却很大。
中间的模型较好的拟合了数据集,可以看到虚线和实线基本重合。
成本函数
成本是衡量模型与训练样本符合程度的指标。简单地理解,成本是针对所有的训练样本,模型拟合出来的值域训练样本的真实值的误差平均值。而成本函数就是成本与模型参数的函数关系。模型训练的过程,就是找出合适的模型参数,使得成本函数的值最小。成本函数记为J(θ),其中θ表示模型参数
用一阶多项式来拟合数据,则得到的模型是y=θ0+θ1x。此时[θ0,θ1] 构成的向量就是模型参数。训练这个模型的目标,就是找出合适的模型参数[θ0,θ1] ,使得所有的点到这条直线上的距离最短。
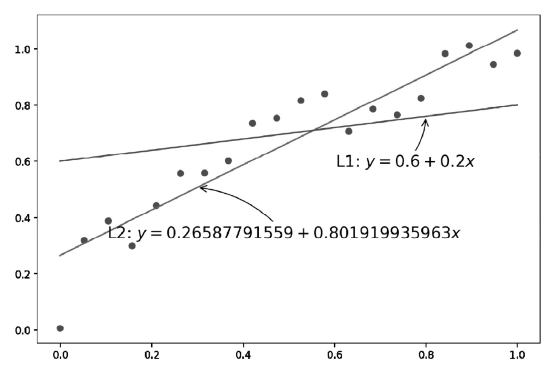
不同的模型参数θ对应不同的直线,明显可以看出L2比L1更好地拟合数据集。根据成本函数的定义,我们可以容易地得出模型的成本函数公式

m是训练样本个数,20个点,h(x(i)) 就是模型对每个样本的预测值,y(i) 是每个样本的真实值。这个公式实际上就是线性回归算法的成本函数简化表达式。
一个数据集可能有多个模型可以用来拟合它,而一个模型有无穷多个模型参数,针对特定的数据集和特定的模型,只有一个模型参数能最好地拟合这个数据集,这就是模型和模型参数的关系。
针对一个数据集,可以选择很多个模型来拟合数据,一旦选定了某个模型,就需要从这个模型的无穷多个参数里找出一个最优的参数,使得成本函数的值最小。
多个模型之间怎么评价好坏呢?在例子中,十阶多项式针对训练样本的成本最小,因为它的预测曲线几乎穿过了所有的点,训练样本到曲线的距离的平均值最小。但是十阶多项式不是最好的模型,因为它过拟合了。
模型准确性
#