本章主要知识点:
- 过拟合和欠拟合的概念
- 模型的成本及成本函数的含义
- 评价一个模型的好坏的标准
- 学习曲线,以及用学习曲线来对模型进行诊断
- 通用模型优化方法
- 其他模型评价标准
##3.1过拟合和欠拟合
过拟合就是模型能很好的拟合训练样本,但对新数据的预测性很差。欠拟合是指模型不能很好的拟合训练样本。且对新数据的预测的准确性也不好。
随机生成20个眼本店的训练样本:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
n_dots = 20
x = np.linspace(0, 1, n_dots) # [0, 1] 之间创建 20 个点
y = np.sqrt(x) + 0.2*np.random.rand(n_dots) - 0.1;
样本为
,其中r 是[-0.1,0.1]之间的一个随机数。
然后用一阶多项式,二阶多项式,十阶多项式来拟合这个数据集,得到如下三个图。
说明:图中的点是我们生存的20个训练样本点;虚线中实际的模型
;实线是我们用训练样本拟合出来的模型。
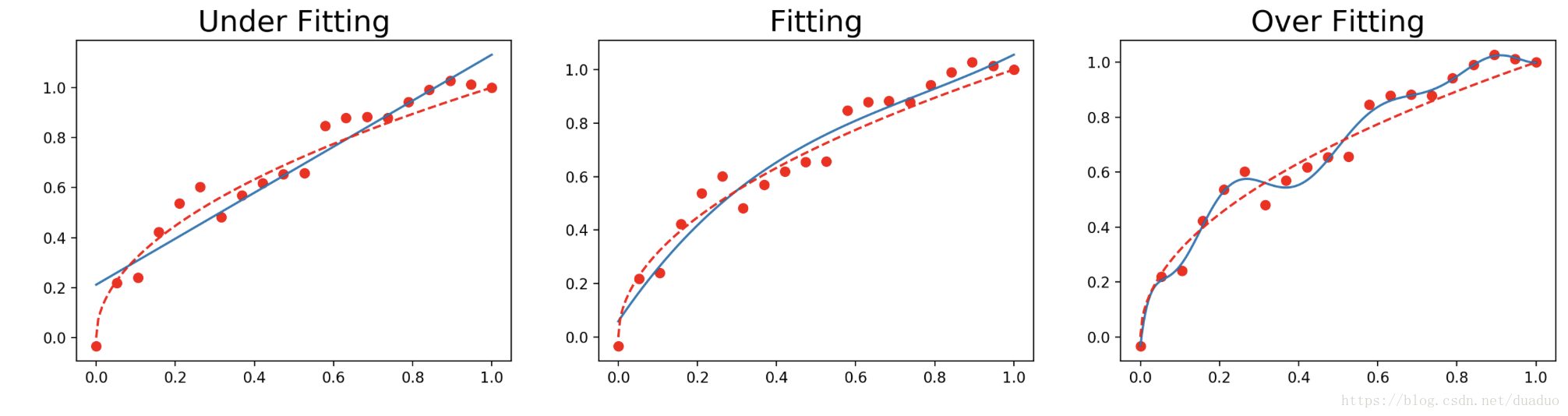
左边是欠拟合,也称为高偏差,一阶多项式尝试用一条直线去拟合数据,右侧为过拟合,也称为高方差,用了十阶多项式来拟合数据,虽然模型对享有数据拟合的较好,但对新数据预测误差却很大,只有中间很好的拟合来数据集,可以看到虚线和实现基本重合。
以上曲线图是由以下方法绘制,曲线绘制方法函数:
def plot_polynomial_fit(x, y, order):
p = np.poly1d(np.polyfit(x, y, order))
#np.ployfit(x,y,order)为用最小二乘法拟合x,y,自由度order
#np.poly1d(2,1,1) 2*x*x+x+1
# 画出拟合出来的多项式所表达的曲线以及原始的点
t = np.linspace(0, 1, 200)
plt.plot(x, y, 'ro', t, p(t), '-', t, np.sqrt(t), 'r--')
return p
调用此函数绘图
plt.figure(figsize=(18, 4), dpi=200)
titles = ['Under Fitting', 'Fitting', 'Over Fitting']
models = [None, None, None]
for index, order in enumerate([1, 3, 10]):
plt.subplot(1, 3, index + 1)
models[index] = plot_polynomial_fit(x, y, order)
plt.title(titles[index], fontsize=20)
##3.2成本函数
成本是衡量模型与训练样本符合程度的指标。
成本是针对所有的训练样本,模型拟合出来的值与训练样本真实值的误差平均值。
成本函数是成本与模型参数的函数关系。
模型训练的过程就是找出合适的模型参数,让成本函数的值最小。
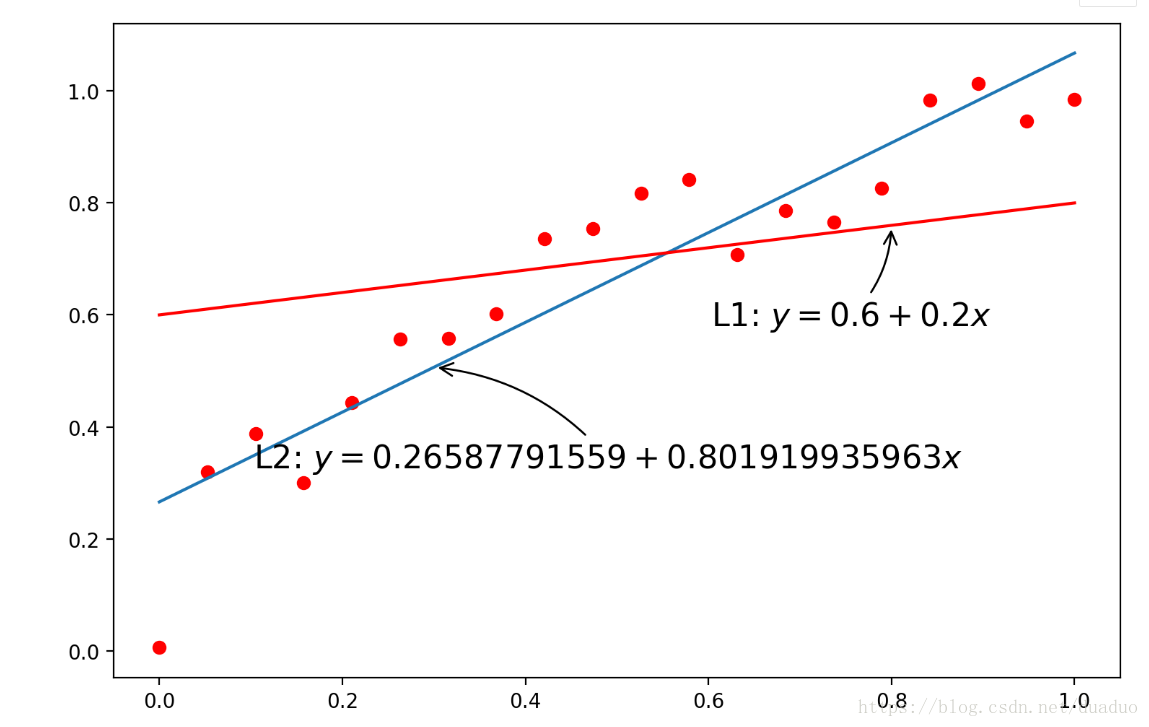
针对一阶多项式模型,不同的参数拟合出来的直线和训练样本之间的关系。
[k1,k2]就是一个模型参数,训练这个模型,使所有的训练集的点到这条直线的距离最短。
# 添加注释
# 第一个参数是注释的内容
# xy设置箭头尖的坐标
# xytext设置注释内容显示的起始位置
# arrowprops 用来设置箭头
# facecolor 设置箭头的颜色
# headlength 箭头的头的长度
# headwidth 箭头的宽度
# width 箭身的宽度
plt.annotate(u"This is a zhushi", xy = (0, 1), xytext = (-4, 50),\
arrowprops = dict(facecolor = "r", headlength = 10, headwidth = 30, width = 20))
# 可以通过设置xy和xytext中坐标的值来设置箭身是否倾斜
# 针对一阶多项式的模型,不同的参数拟合出来的直线和训练样本对应的位置关系
coeffs_1d = [0.2, 0.6]
plt.figure(figsize=(9, 6), dpi=200)
t = np.linspace(0, 1, 200)
plt.plot(x, y, 'ro', t, models[0](t), '-', t, np.poly1d(coeffs_1d)(t), 'r-')
plt.annotate(r'L1: $y = {1} + {0}x$'.format(coeffs_1d[0], coeffs_1d[1]),
xy=(0.8, np.poly1d(coeffs_1d)(0.8)), xycoords='data',
xytext=(-90, -50), textcoords='offset points', fontsize=16,
arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2"))
plt.annotate(r'L2: $y = {1} + {0}x$'.format(models[0].coeffs[0], models[0].coeffs[1]),
xy=(0.3, models[0](0.3)), xycoords='data',
xytext=(-90, -50), textcoords='offset points', fontsize=16,
arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2"))
##3.3模型准确性
测试数据集的成本是描述模型准确性的最直观的的指标。成本越小,说明模型预测出来的值与实际值差异越小。对显得数据的预测准确性越好。
###3.3.1 模型性能的不同表述方式
在sciki-learn中,使用分数来表达模型性能,在0~1之间,数值越大说明模型准确性越好,误差越小,成本越低。
###3.3.2 交叉验证数据集
一个科学的方法将数据集分为三分,训练数据集,交叉验证数据集,测试数据集。比例为6:2:2
测试数据集的主要功能是测试模型的准确性,需要确保模型“没见过”这些数据。若我们用测试数据集来选择参数,相当于把测试数据集让模型看到了,这样选择出来的参数本来就是对模型友好的。
我们用悬链数据集来训练算法参数,用交叉验证数据集来验证参数,选择交叉数据集的成本Jcv(θ)最小的模型参数来最为模型参数,最后再用测试数据集来测试选择出来的模型针对测试数据集的准确性。
##3.4 学习曲线
把Jtrain(θ)和 Jcv(θ )为纵坐标,画出与数据集m的大小关系。这就是学习曲线,通过学习曲线可以直观的看出模型的准确性与训练数据集的大小的关系。
如果数据集的大小为m,则通过以下流程来画出学习曲线。
- 把数据集分为训练数据集和交叉验证数据集
- 去蓄念数据集的20%作为训练样本,训练出模型参数。
- 使用交叉验证数据集来计算训练出来的模型的准确性
- 以训练数据集的准确性,交叉验证训练集的准确性为纵坐标,以数据集的大小为横坐标,在坐标轴上画出上述步骤计算出来的模型准确性。
-训练数据集增加10%,跳到第三步执行,知道训练数据集的大小为100%为止。
学习曲线想要表达的内容是,当训练数据集增加时,模型对训练数据拟合的准确性及对交叉验证数据集预测的准确性的变化规律。
###3.4.1画出学习曲线
##3.6查准率和召回率
定义:
查准率:Precision=TruePosition/(TruePosition+FalsePositive)
召回率:Recall=TruePositive/(TruePositive+FalseNegative)
如何理解True/False和Positive/Negative?True/False 表示预测结果是否正确,而Positive/Negative表示预测结果是1(恶性肿瘤)还是0(良性肿瘤)
TurePositive表示正确地预测出恶性肿瘤的数量,False表示错误地预测出恶性肿瘤的数量。
在处理先验概率较低的问题时,我们总是把概率较低的事件定义为1,并且把y=1作为Positive的预测结果。
##3.7 F1 Score
引入F1score的概念:
F1Score=2*PR/(P+R)
其中P是查准率,R是召回率。这样就可以用一个数值判断哪个算法性能更好。 在scikit-learn中,的接口为sklearn.metrics.f1_score().