1. 数据预处理
sklearn.preprocessing.scale( data ),sklearn.preprocessing.StandardScaler 对给定数据进行标准化(均值、方差)
sklearn.preprocessing.MinMaxScaler 将属性缩放到一个指定范围
sklearn.preprocessing. nomalize(),sklearn.preprocessing.Nomalizer 正则化
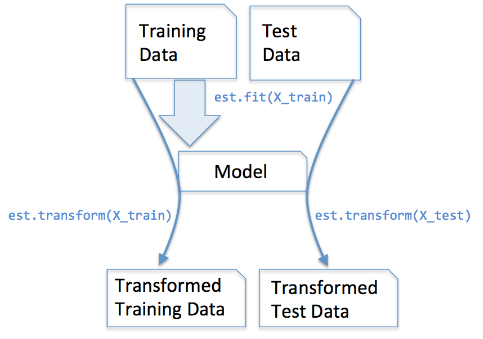
两个关键的函数 fit和transform,fit让数据适应模型,transform转换数据
2. 特征提取
DictVectorizer
参考:https://blog.csdn.net/qq_36847641/article/details/78279309
提取前的字典结构
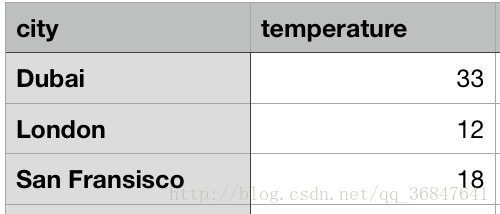
提取后的数组结构

3. 测试集和训练集划分
train_test_split 函数用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签
X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_data,train_target,test_size=0.3, random_state=0)
参考:https://www.cnblogs.com/bonelee/p/8036024.html