sklearn
学习莫烦python,非常感谢~记录自己在学习python过程中的点滴。
sklearn 简介
- 机器学习 Machine Learning
- 监督学习 supervised learning;
- 非监督学习 unsupervised learning;
- 半监督学习 semi-supervised learning;
- 强化学习 reinforcement learning;
- 遗传算法 genetic algorithm.
- sklearn 安装
- Anaconda安装
- pip安装
sklearn 一般使用
- 选择学习方法
- 通用学习方式
- sklearn 强大数据库
- sklearn 常用属性与功能
选择学习方法
- 看图选方法
常用算法可分为四类:分类,回归,聚类,降维。
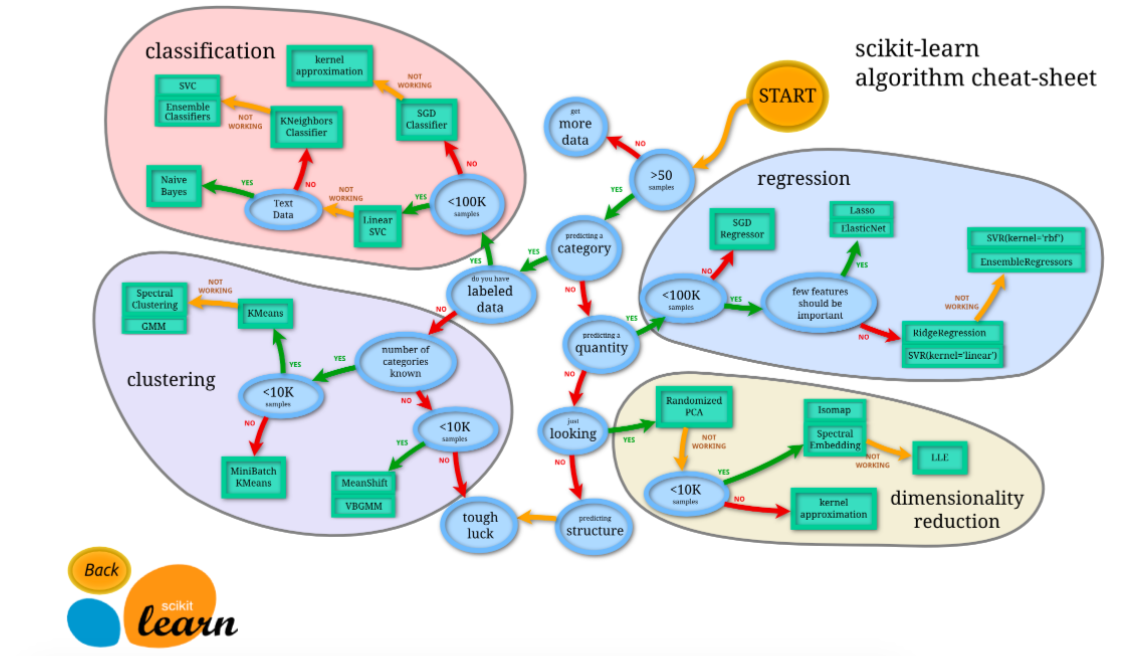
通用学习方式
- 要点
- 创建数据
- 建立模型-训练-预测
要点:用KNN classifier,对Iris数据集进行分类
创建数据:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris()
iris_X = iris.data
iris_y = iris.target
print(iris_X[:2, :])
print(iris_y)
"""
[[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
"""
X_train, X_test, y_train, y_test = train_test_split(
iris_X, iris_y, test_size=0.3)
print(y_train)
"""
[2 1 0 1 0 0 1 1 1 1 0 0 1 2 1 1 1 0 2 2 1 1 1 1 0 2 2 0 2 2 2 2 2 0 1 2 2
2 2 2 2 0 1 2 2 1 1 1 0 0 1 2 0 1 0 1 0 1 2 2 0 1 2 2 2 1 1 1 1 2 2 2 1 0
1 1 0 0 0 2 0 1 0 0 1 2 0 2 2 0 0 2 2 2 1 2 0 0 2 1 2 0 0 1 2]
"""
建立模型-训练-预测:
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
print(knn.predict(X_test))
print(y_test)
"""
[2 0 0 1 2 2 0 0 0 1 2 2 1 1 2 1 2 1 0 0 0 2 1 2 0 0 0 0 1 0 2 0 0 2 1 0 1
0 0 1 0 1 2 0 1]
[2 0 0 1 2 1 0 0 0 1 2 2 1 1 2 1 2 1 0 0 0 2 1 2 0 0 0 0 1 0 2 0 0 2 1 0 1
0 0 1 0 1 2 0 1]
"""
sklearn 强大数据库
- 要点
- 导入数据-训练模型
- 创建虚拟数据-可视化
要点:使用 sklearn 读取数据库和生成虚拟的数据,例如用来训练线性回归模型的数据
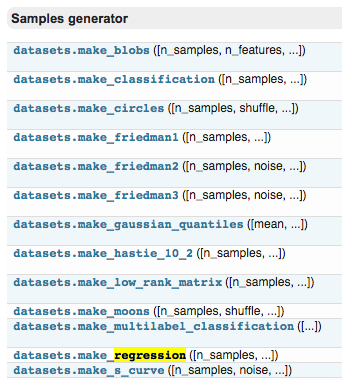
sklearn.datasets.make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)[source]
导入数据-训练模型:
from __future__ import print_function
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
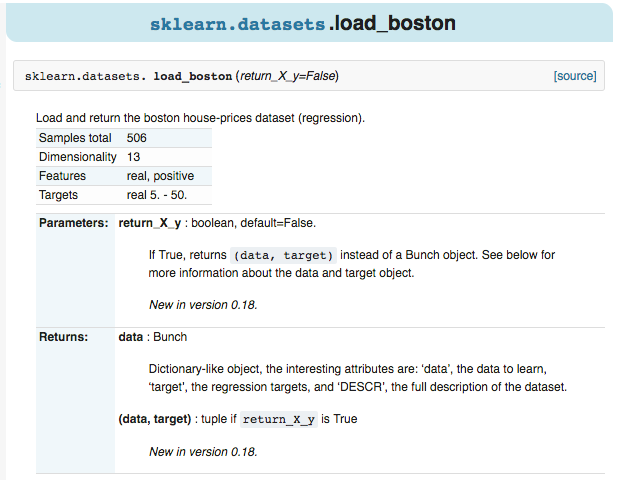
loaded_data = datasets.load_boston()
data_X = loaded_data.data
data_y = loaded_data.target
model = LinearRegression()
model.fit(data_X, data_y)
print(model.predict(data_X[:4, :]))
print(data_y[:4])
“”“
[ 30.00821269 25.0298606 30.5702317 28.60814055]
[ 24. 21.6 34.7 33.4]
”“”
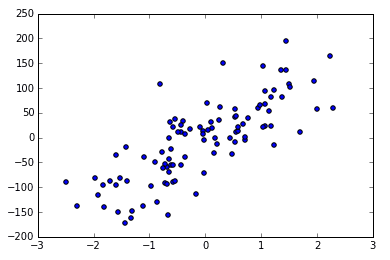
创建虚拟数据-可视化:
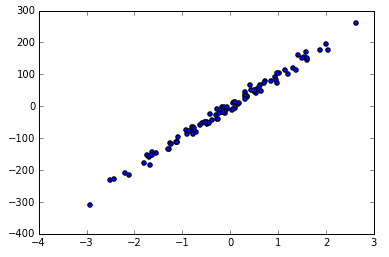
X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=10)
plt.scatter(X, y)
plt.show()
X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=50)
plt.scatter(X, y)
plt.show()
sklearn 常用属性与功能
model.coef_:输出模型的斜率model.intercept_:输出模型的截距(与y轴的交点)model.get_params():取出之前定义的参数model.score(data_X, data_y):对 Model 用 R^2 的方式进行打分
训练和预测:
from sklearn import datasets
from sklearn.linear_model import LinearRegression
loaded_data = datasets.load_boston()
data_X = loaded_data.data
data_y = loaded_data.target
model = LinearRegression()
model.fit(data_X, data_y)
print(model.predict(data_X[:4, :]))
"""
[ 30.00821269 25.0298606 30.5702317 28.60814055]
"""
参数和分数:
print(model.coef_)
print(model.intercept_)
"""
[ -1.07170557e-01 4.63952195e-02 2.08602395e-02 2.68856140e+00
-1.77957587e+01 3.80475246e+00 7.51061703e-04 -1.47575880e+00
3.05655038e-01 -1.23293463e-02 -9.53463555e-01 9.39251272e-03
-5.25466633e-01]
36.4911032804
"""
print(model.get_params())
"""
{'copy_X': True, 'normalize': False, 'n_jobs': 1, 'fit_intercept': True}
"""
print(model.score(data_X, data_y)) # R^2 coefficient of determination
"""
0.740607742865
"""
sklearn 高级使用
- 正规化 Normalization
- 检查神经网络(Evaluation)
- 交叉验证 1 Cross-validation
- 交叉验证 2 Cross-validation
- 交叉验证 3 Cross-validation
- 保存模型
正规化 Normalization
- 数据标准化
- 数据标准化对机器学习成效的影响
数据标准化:
from sklearn import preprocessing #标准化数据模块
import numpy as np
#建立Array
a = np.array([[10, 2.7, 3.6],
[-100, 5, -2],
[120, 20, 40]], dtype=np.float64)
#将normalized后的a打印出
print(preprocessing.scale(a))
# [[ 0. -0.85170713 -0.55138018]
# [-1.22474487 -0.55187146 -0.852133 ]
# [ 1.22474487 1.40357859 1.40351318]]
数据标准化对机器学习成效的影响:
# 标准化数据模块
from sklearn import preprocessing
import numpy as np
# 将资料分割成train与test的模块
from sklearn.model_selection import train_test_split
# 生成适合做classification资料的模块
from sklearn.datasets.samples_generator import make_classification
# Support Vector Machine中的Support Vector Classifier
from sklearn.svm import SVC
# 可视化数据的模块
import matplotlib.pyplot as plt
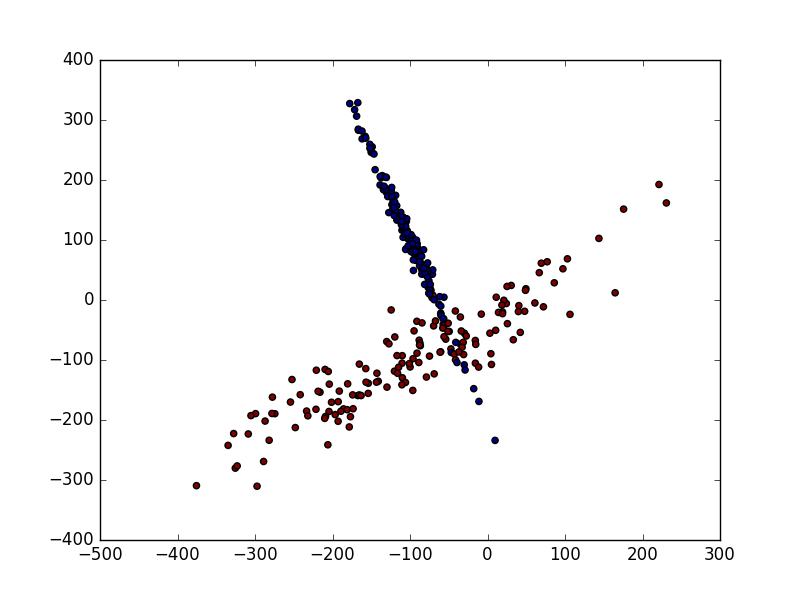
#生成具有2种属性的300笔数据
X, y = make_classification(
n_samples=300, n_features=2,
n_redundant=0, n_informative=2,
random_state=22, n_clusters_per_class=1,
scale=100)
#可视化数据
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.477777777778
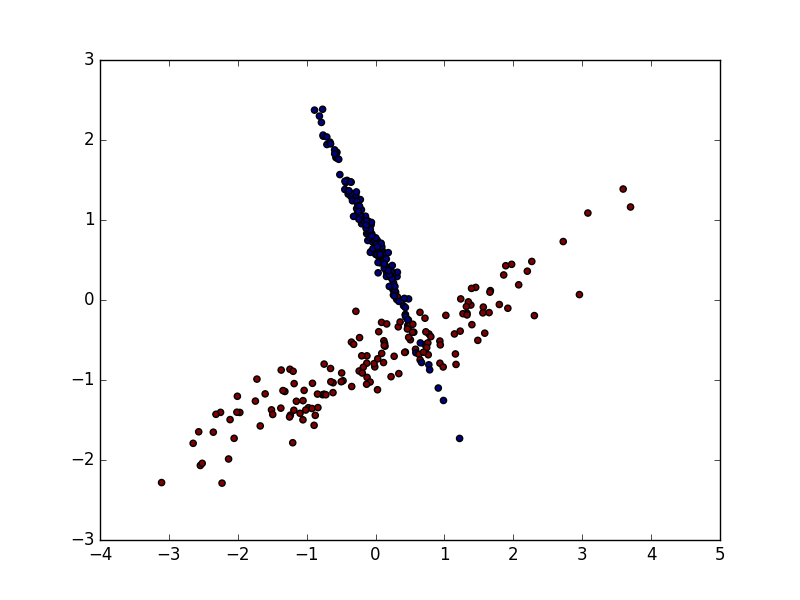
X = preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.9
检查神经网络(Evaluation)
- Training and Test data
- 误差曲线
- 准确度曲线
- 正规化
- 交叉验证
Training and Test data:70% training,30% testing
误差曲线:
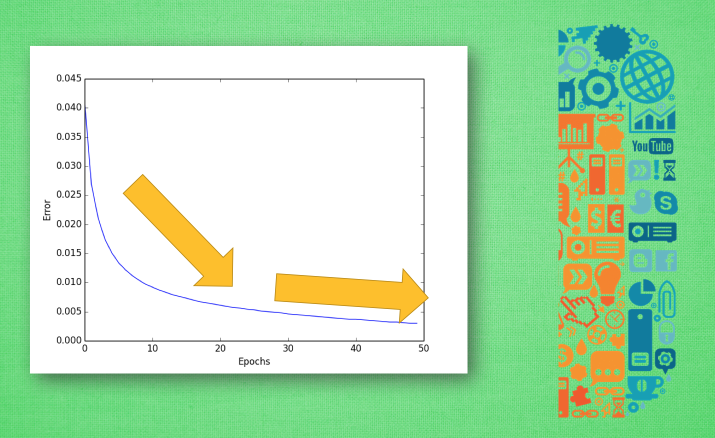
准确度曲线:
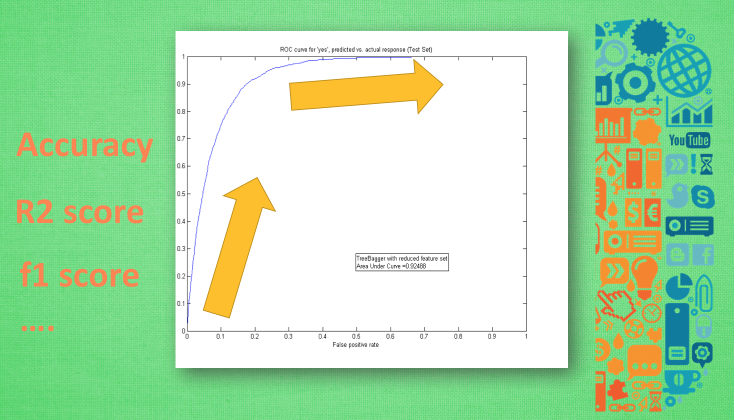
正规化:
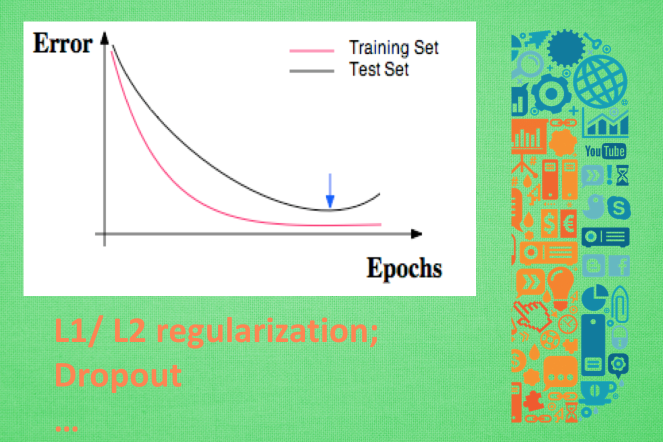
交叉验证:
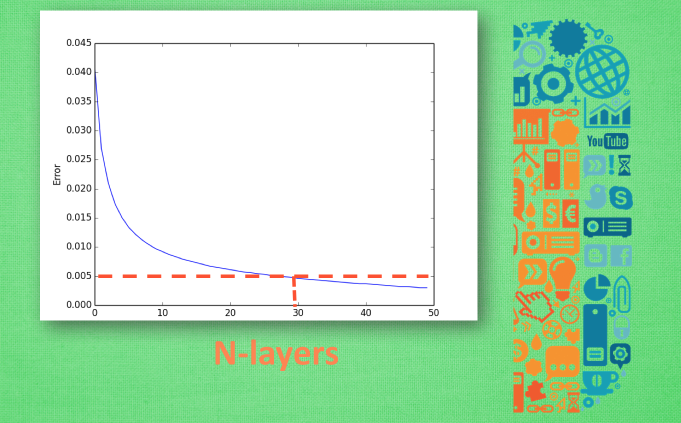
交叉验证 1 Cross-validation
- Model 基础验证法
- Model 交叉验证法(Cross Validation)
- 以准确率(accuracy)判断
- 以平均方差(Mean squared error)
Model 基础验证法:
from sklearn.datasets import load_iris # iris数据集
from sklearn.model_selection import train_test_split # 分割数据模块
from sklearn.neighbors import KNeighborsClassifier # K最近邻(kNN,k-NearestNeighbor)分类算法
#加载iris数据集
iris = load_iris()
X = iris.data
y = iris.target
#分割数据并
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4)
#建立模型
knn = KNeighborsClassifier()
#训练模型
knn.fit(X_train, y_train)
#将准确率打印出
print(knn.score(X_test, y_test))
# 0.973684210526
Model 交叉验证法(Cross Validation):
from sklearn.cross_validation import cross_val_score # K折交叉验证模块
#使用K折交叉验证模块
scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy')
#将5次的预测准确率打印出
print(scores)
# [ 0.96666667 1. 0.93333333 0.96666667 1. ]
#将5次的预测准确平均率打印出
print(scores.mean())
# 0.973333333333
以准确率(accuracy)判断
import matplotlib.pyplot as plt #可视化模块
#建立测试参数集
k_range = range(1, 31)
k_scores = []
#藉由迭代的方式来计算不同参数对模型的影响,并返回交叉验证后的平均准确率
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy')
k_scores.append(scores.mean())
#可视化数据
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
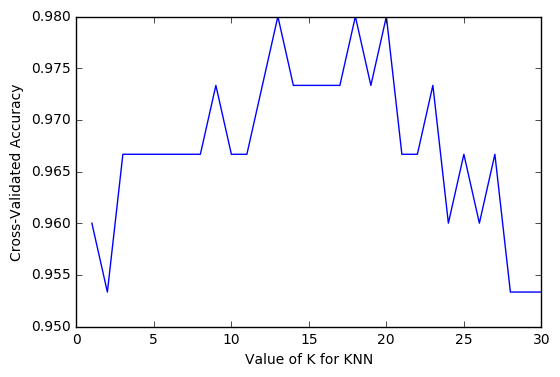
以平均方差(Mean squared error):
import matplotlib.pyplot as plt
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
loss = -cross_val_score(knn, X, y, cv=10, scoring='mean_squared_error')
k_scores.append(loss.mean())
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated MSE')
plt.show()
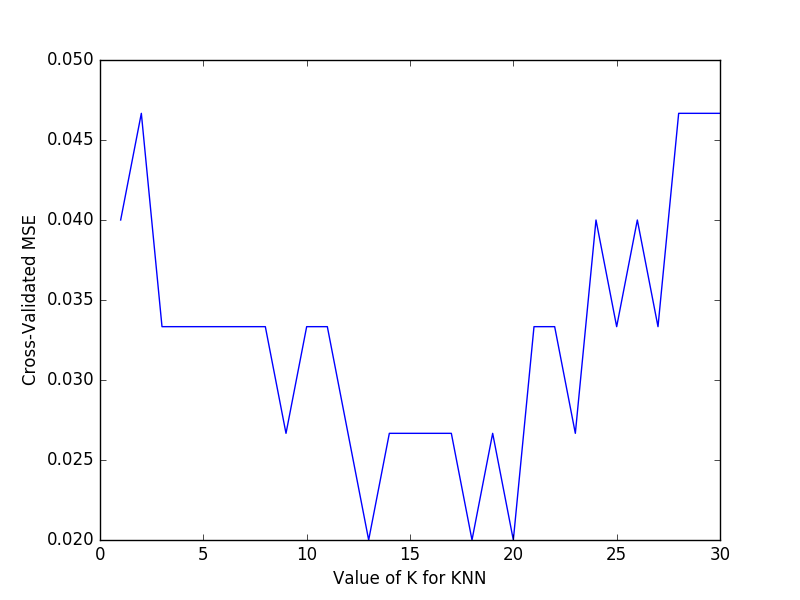
交叉验证 2 Cross-validation
sklearn.learning_curve: 检视过拟合
Learning curve 检视过拟合:
from sklearn.learning_curve import learning_curve #学习曲线模块
from sklearn.datasets import load_digits #digits数据集
from sklearn.svm import SVC #Support Vector Classifier
import matplotlib.pyplot as plt #可视化模块
import numpy as np
digits = load_digits()
X = digits.data
y = digits.target
train_sizes, train_loss, test_loss = learning_curve(
SVC(gamma=0.001), X, y, cv=10, scoring='mean_squared_error',
train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
#平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%)
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
plt.plot(train_sizes, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
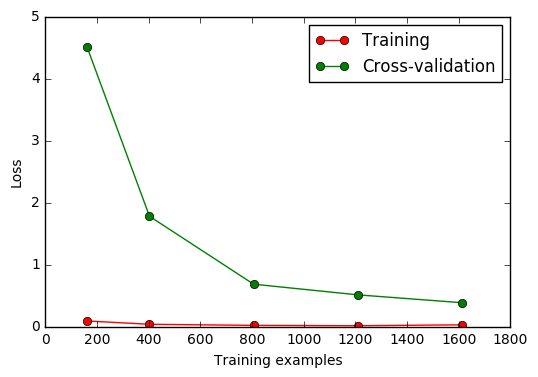
交叉验证 3 Cross-validation
sklearn.validation_curve:检视过拟合
validation_curve 检视过拟合:
from sklearn.learning_curve import validation_curve #validation_curve模块
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
#digits数据集
digits = load_digits()
X = digits.data
y = digits.target
#建立参数测试集
param_range = np.logspace(-6, -2.3, 5)
#使用validation_curve快速找出参数对模型的影响
train_loss, test_loss = validation_curve(
SVC(), X, y, param_name='gamma', param_range=param_range, cv=10, scoring='mean_squared_error')
#平均每一轮的平均方差
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
#可视化图形
plt.plot(param_range, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(param_range, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
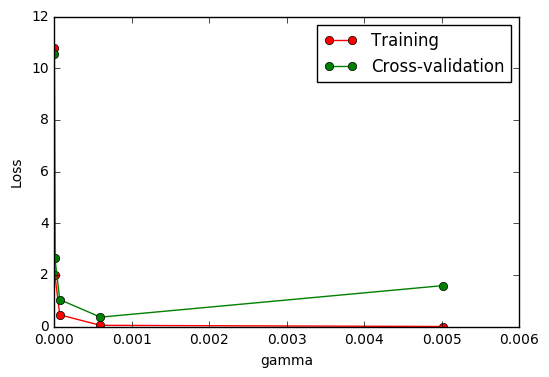
保存模型
- 使用 pickle 保存
- 使用 joblib 保存
使用 pickle 保存:
from sklearn import svm
from sklearn import datasets
clf = svm.SVC()
iris = datasets.load_iris()
X, y = iris.data, iris.target
clf.fit(X,y)
import pickle #pickle模块
#保存Model(注:save文件夹要预先建立,否则会报错)
with open('save/clf.pickle', 'wb') as f:
pickle.dump(clf, f)
#读取Model
with open('save/clf.pickle', 'rb') as f:
clf2 = pickle.load(f)
#测试读取后的Model
print(clf2.predict(X[0:1]))
# [0]
使用 joblib 保存:
from sklearn.externals import joblib #jbolib模块
#保存Model(注:save文件夹要预先建立,否则会报错)
joblib.dump(clf, 'save/clf.pkl')
#读取Model
clf3 = joblib.load('save/clf.pkl')
#测试读取后的Model
print(clf3.predict(X[0:1]))
# [0]
再次感谢莫烦python