数据集划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
训练数据和测试数据常用的比例一般为:70%: 30%, 80%: 20%, 75%: 25%
sklearn数据集划分API:
sklearn.model_selection.train_test_split
常用参数:
- 特征值和目标值
- test_size:测试数据的大小,默认为0.25
返回值:训练数据特征值,测试数据特征值,训练数据目标值,测试数据目标值的元组
scikit-learn数据集API
自己准备数据集耗时耗力,而且不一定真实,scikit-learn提供了非常方便的获取数据集的API。
sklearn.datasets:加载获取流行数据集
- datasets.load_*():获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None):获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
- datasets.make_*():本地生成数据集
load*和 fetch* 函数返回的数据类型是 datasets.base.Bunch,本质上是一个 dict,它的键值对可用通过对象的属性方式访问。主要包含以下属性:
- data:特征数据数组,是 n_samples * n_features 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名
- target_names:标签名
数据集目录可以通过datasets.get_data_home()获取,clear_data_home(data_home=None)删除所有下载数据
datasets.get_data_home(data_home=None):返回scikit学习数据目录的路径。这个文件夹被一些大的数据集装载器使用,以避免下载数据。默认情况下,数据目录设置为用户主文件夹中名为“scikit_learn_data”的文件夹。或者,可以通过“SCIKIT_LEARN_DATA”环境变量或通过给出显式的文件夹路径以编程方式设置它。'〜'符号扩展到用户主文件夹。如果文件夹不存在,则会自动创建。
sklearn.datasets.clear_data_home(data_home=None):删除存储目录中的数据
加载小批量数据:
加载并返回鸢尾花数据集,并对其进行划分:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
li = load_iris()
# print("获取特征值")
# print(li.data)
# print("获取目标值")
# print(li.target)
# print(li.DESCR)
x_train, x_test, y_train, y_test = train_test_split(
li.data, li.target, test_size=0.25)
print("训练集特征值和目标值", x_train, y_train)
print("测试集特征值和目标值", x_test, y_test)加载大批量的数据:
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
- subset: 'train'或者'test','all',可选,选择要加载的数据集.训练集的“训练”,测试集的“测试”,两者的“全部
from sklearn.datasets import load_iris, fetch_20newsgroups
news = fetch_20newsgroups()
print(news.data)
print(news.target)加载波士顿房价
from sklearn.datasets import load_boston
lb = load_boston()
print("获取特征值")
print(lb.data)
print("获取目标值")
print(lb.target)
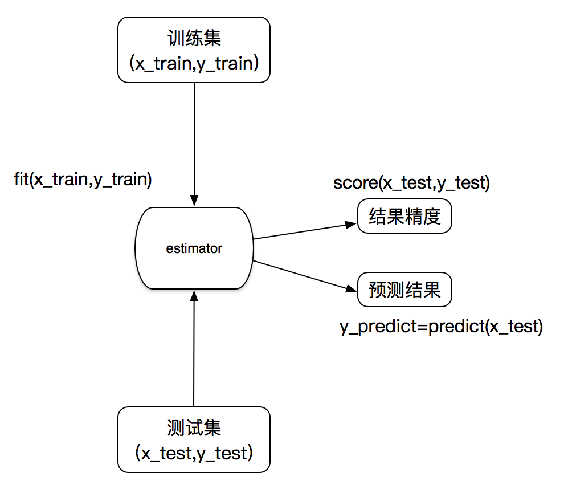
print(lb.DESCR)sklearn机器学习算法的实现-估计器
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API。
- fit方法用于从训练集中学习模型参数
- transform用学习到的参数转换数据
1、用于分类的估计器:
sklearn.neighbors k-近邻算法
sklearn.naive_bayes 贝叶斯
sklearn.linear_model.LogisticRegression 逻辑回归
2、用于回归的估计器:
sklearn.linear_model.LinearRegression 线性回归
sklearn.linear_model.Ridge 岭回归
估计器的工作流程: