12.1 基础知识
顾名思义,研究的是通过“计算”来进行“学习”的理论,即关于机器学习的理论基础,
其目的是分析学习任务的苦难本质,为学习算法提供理论保证,
并根据分析结果指导算法设计。
12.2 PAC学习
为什么要学习PAC学习理论?
此理论可以帮助我们更深入的了解机器学习的学习机制。
已经入门或者从事过一段时间机器学习相关工作的你有没有想过为什么在训练样本上学习了一个假设(函数?模型?下文统一叫假设)就能保证这个假设在训练样本之外的数据上有效?看完这篇文章你就会明白有效性是有严谨的理论保证的。
几千条样本数据就敢用CNN/RNN?你心也够大的。如果你非要这么做,老司机会语重心长的教育你:“数据太少,会导致过拟合”。看完这篇文章就会明白为什么了。
如果看完这篇文章后你能回答这两个问题,那么恭喜你,你已经对PAC学习理论有了大致的了解了。



12.3 有限假设空间
- 可分情形
怎么找到满足误差参数的假设?
任何在训练集D上出现标记错误的假设肯定不是目标概念C,一点点剔除即可,直到只剩下一个。
到底需要多少样例才能学得目标概念c的有效近似呢?
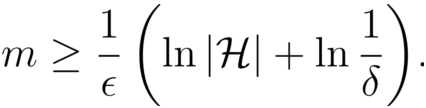
可分情况下的有限假设空间 H 都是PAC可学习的, 输出假设h的泛化误差随样例数目的增多而收敛到0, 收敛速率为O(1/m)
- 不可分情况
找泛化误差最小的假设 近似
有限假设集是不可知PAC可学习的
12.4 VC维
针对无限假设
增长函数(growth function)
随着m的增大, H 中所有假设对 D 中的示例所能赋予标记的可能结果数也会增大.
H 对示例所能赋予标记的可能结果数越大, H 的表示能力越强, 对学习任务的适应能力也越强.
增长函数表述了假设空间 H 的表示能力, 由此反映出假设空间的复杂度
对分(dichotomy)
对二分类问题来说, H 中的假设对 D 中示例赋予标记的每种可能结果称为对 D 的一种“对分”.
打散(shattering)
假设空间 H 能实现实例集 D 上的所有对分(对所有结果都表现出)
基于VC维的泛化误差界是分布无关、数据独立的, 这使得基于 VC维的可学习性分析结果具有一定的“普适性”。
无论基于VC维和Rademacher复杂度来分析泛化性能, 得到的结果均与具体的学习算法无关, 这使得人们能够脱离具体的学习算法来考虑学习问题本身的性质。
若学习算法L 满足经验风险最小化且稳定的,则假设空间H可学习。
12 .5 Rademacher复杂度

12.6 稳定性
无论是基于VC维还是Rademacher复杂度来推导泛化误差界,所得到的结果均与具体的学习算法无关,对所有学习算法都适用。
但在另一方面,若希望获得与算法有关的分析结果,则需另辟蹊径。稳定性(stability)分析是这一方面值得关注的方向。
