

7.1 贝叶斯决策论
贝叶斯决策(Bayesion decison theory)论是概率框架下实施决策的基本方法。
对分类任务来说,在所有概率都已知的理想情形下,贝叶斯决策论考虑如何基于这些概率和误判损失来选择最优的类别标记。
下面我们以多分类任务为例来解释其基本原理。



7.2 极大似然估计


7.3 朴素贝叶斯分类器
示例:过滤网站恶意留言
一个很简单的例子,我本来想使用DataFrame来重新实现,但是这样可能比原来还复杂了,所以引用了原来的numpy结构来处理。
说明:有一堆已经清理好的留言单词及它的所属类,现在根据已有的数据求一条新的留言所属分类。
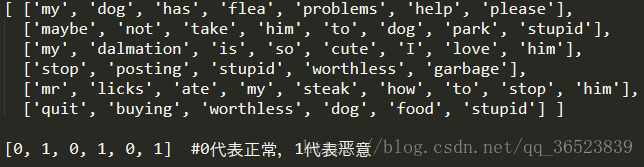
样本数据如上:六条已经划分好了的留言数据集,以及各自对应的分类。具体看下面的代码及注释:
from numpy import *
#加载数据
def loadDataSet():
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1]
return postingList, classVec
#合并所有单词,利用set来去重,得到所有单词的唯一列表
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document)
return list(vocabSet)
#优化词集模型= 为 词袋模型+=,将单词列表变为数字向量列表
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0] * len(vocabList) #获得所有单词等长的0列表
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1 #对应单词位置加1
return returnVec
# 返回的是0、1各自两个分类中每个单词数量除以该分类单词总量再取对数ln 以及0、1两类的比例
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix) # 样本数
numWords = len(trainMatrix[0]) # 特征数
pAbusive = sum(trainCategory) / float(numTrainDocs) # 1类所占比例
p0Num = ones(numWords)
p1Num = ones(numWords) #初始化所有单词为1
p0Denom = 2.0
p1Denom = 2.0 #初始化总单词为2 后面解释为什么这四个不初始化为0
for i in range(numTrainDocs):
if trainCategory[i] == 1: #求1类
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i] #求0类
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num / p1Denom) # numpy数组 / float = 1中每个单词/1中总单词
p0Vect = log(p0Num / p0Denom) # 这里为什么还用ln来处理,后面说明
return p0Vect, p1Vect, pAbusive
#P(X|C)判断各类别的概率大小(这里是0、1)
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) # 相乘后得到哪些单词存在,再求和,再+log(P(C))
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) # 由于使用的是ln,这里其实都是对数相加
if p1 > p0:
return 1
else:
return 0
#封装调用的函数
def testingNB():
listOPosts, listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat = []
for postinDoc in listOPosts:
trainMat.append(bagOfWords2VecMN(myVocabList, postinDoc))
p0V, p1V, pAb = trainNB0(array(trainMat), array(listClasses))
#上面求出了0、1两个类中各单词所占该类的比例,以及0、1的比例
#下面是预测两条样本数据的类别
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(bagOfWords2VecMN(myVocabList, testEntry)) #先将测试数据转为numpy的词袋模型 [0 2 0 5 1 0 0 3 ...]
print(testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb)) #传值判断
testEntry = ['stupid', 'garbage']
thisDoc = array(bagOfWords2VecMN(myVocabList, testEntry))
print(testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb))
if __name__=="__main__":
testingNB()

7.4 半朴素贝叶斯分类器




7.5 贝叶斯网
贝叶斯网络(Bayesian network),又称信念网络(Belief Network),
或有向无环图模型(directed acyclic graphical model),
是一种概率图模型,于1985年由Judea Pearl首先提出。它是一种模拟人类推理过程中因果关系的不确定性处理模型,
其网络拓朴结构是一个有向无环图(DAG)。
7.6 EM算法
EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),所以算法被称为EM算法(Expectation Maximization Algorithm)。EM算法受到缺失思想影响,最初是为了解决数据缺失情况下的参数估计问题,其算法基础和收敛有效性等问题在Dempster,Laird和Rubin三人于1977年所做的文章Maximum likelihood from incomplete data via the EM algorithm中给出了详细的阐述。其基本思想是:首先根据己经给出的观测数据,估计出模型参数的值;然后再依据上一步估计出的参数值估计缺失数据的值,再根据估计出的缺失数据加上之前己经观测到的数据重新再对参数值进行估计,然后反复迭代,直至最后收敛,迭代结束。
EM算法作为一种数据添加算法,在近几十年得到迅速的发展,主要源于当前科学研究以及各方面实际应用中数据量越来越大的情况下,经常存在数据缺失或者不可用的的问题,这时候直接处理数据比较困难,而数据添加办法有很多种,常用的有神经网络拟合、添补法、卡尔曼滤波法等等,但是EM算法之所以能迅速普及主要源于它算法简单,稳定上升的步骤能非常可靠地找到“最优的收敛值”。随着理论的发展,EM算法己经不单单用在处理缺失数据的问题,运用这种思想,它所能处理的问题更加广泛。有时候缺失数据并非是真的缺少了,而是为了简化问题而采取的策略,这时EM算法被称为数据添加技术,所添加的数据通常被称为“潜在数据”,复杂的问题通过引入恰当的潜在数据,能够有效地解决我们的问题。
