
2.1经验误差与过拟合
学习器在训练集上的误差称为“训练误差”(training error)或”经验误差“。
当学习器把训练样本学得“太好”了的时候,
很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的的一般性质,
这样就会导致泛化性能下降,
这种现象在机器学习中称为“过拟合”(overfitting)。
2.2评估方法
当我们只有一个包含m个样例的数据集D={(x1,y1),(x2,y2),·······,(xm,ym)},既要训练,又要测试,怎样才能做到呢?
答案是:
通过对D进行适当的处理,从中产出训练集S和测试级T。下面介绍几种常见的做法。
2.1、留出法
直接将数据集划分为两个互斥的集合,2/3-4/5。
划分原则:划分过程尽可能保持数据分布的一致性
方法缺陷:训练集过大,更接近整个数据集,但是由于测试集较小,导致评估结果缺乏稳定性;测试集大了,偏离整个数据集,与根据数据集训练出的模型差距较大,缺乏保真性。
2.2、交叉验证法
将数据集划分为k个大小相似的互斥子集,每个子集轮流做测试集,其余做训练集,最终返回这k个训练结果的均值。
优点:更稳定,更具准确定;
缺单:时间复杂的较大
2.3、自助法
包含m个样本的数据集D,对D进行随机抽样构建D’(抽取m次),然后将抽到的数据对象放回D,D’用作训练集,剩余数据作为测试集。某样本不被抽到的概率:
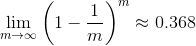
因此初始样本集D约有0.732的样本做训练集,0.368的样本做测试集
优点:适合较小的、难以有效划分训练/测试集的数据集;
缺点:产生的数据集改变了原始数据集的分布,这样会引入估计偏差。
2.4、调参
调参对象:1算法的固有参数,如k-means中的类簇个数;2模型的参数,如深度学习模型中上百亿个参数。两种参数均是产生多个模型之后基于某种评估方法来进行选择,不同之处在于前者通常是由人工设定多个参数候选值,后者通过学习。
参数是连续的,不可能一一实现,现实的做法是选取一个步长,所以选出的参数往往不是最好的,这是综合考虑开销与性能(没有免费的午餐)所做的折中的结果。
性能度量:错误率和精度,两者相加为1;均方误差,概率分布函数。
2.3性能度量
对学习器的泛化能力进行评估,不仅需要有效可行的实验评估方法,
还需要有衡量泛化能力的评价标准,这就是”性能度量“(performance measure)。
首先判断目标任务是回归还是分类。
如果是回归那么性能度量方法为聚方误差:
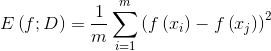
下面主要介绍分类任务中常用的性能度量。
2.3.1 错误率与精度
错误率是分类错误的样本数占样本总数的比例,精度则相反。
2.3.2 查准率,查全率与F1
分类结果混淆矩阵
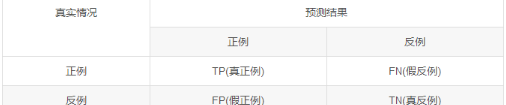
查准率:挑出来的真好瓜占所有挑出来好瓜的概率;
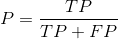
查全率(召回率):被挑出来的好瓜占所有好瓜的概率。
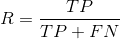
准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了
综合考虑查准率和查全率 进而提出了 F1-measure 相当于精确率和召回率的综合评价指标
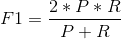 当F1较高时则能说明试验方法比较有效。
当F1较高时则能说明试验方法比较有效。
宏查准率、宏查全率,微查准率、微查全率不在单独介绍。
P-R图用来比较两学习器性能方法
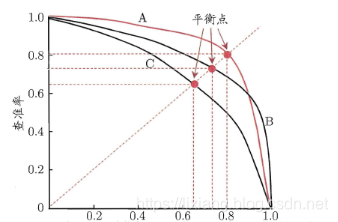
如上图,横轴是查全率
1)c曲线被ab曲线包住,毫无疑问,ab优于c学习器;
2)寻找平衡点,如图中的红点,当查准率=查全率时,数值越高,对应的学习器往往越优秀。
3.3 ROC、AUC和EER
与P-R曲线类似,我们根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别作为横、纵坐标做图。
ROC曲线的的横轴为:假正例率 FP
ROC曲线的的纵轴为:真正例率 TP
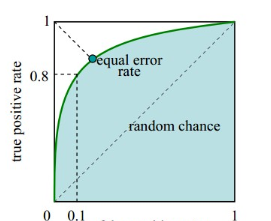
ROC曲线、AUC和EER示意图
给定一个学习系统,如果更多的正样本被识别为正样本,那么也就意味着更多的负样本被识别成了正样本。图中的对角线对应于“随机猜测”模型。
1)ROC即为绿线。视情况而定,如果面部识别开锁系统的话,观察假正率为零时,真正率的高度,越高越好;
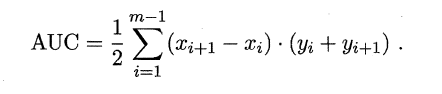
2)AUC即为蓝色面积。面积越大越好
3)EER等错误率即为绿色原点.在该点处 假正率FP和假错率FN相等,该点值越小越好。
也可以基于有限样例绘制出ROC曲线与AUC
代价敏感错误率
不同类型的错误所造成的后果或者代价是不同的,
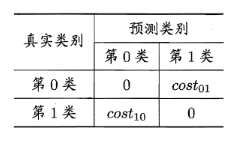
代价敏感错误率是基于非均等代价的。二分类代价矩阵:costij表示将第i类样本预测为第j类样本的代价。一般说来,costii=0;若将第0类判别为第1类所造成的损失更大,则cost01> cost10;
在非均等错误代价下,我们希望的是最小化“总体代价”,这样“代价敏感”的错误率为:
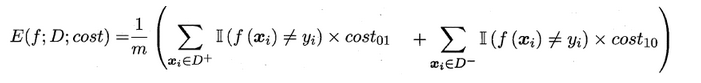
2.4 比较检验
为什么引入该部分???
1)需要比较的是泛化误差,但是我们只有经验/测试误差,测试误差是泛化误差的近似,两者接近可能性较大,偏离可能性较小;
2)测试集上的性能与测试集本身的选择有关系,同一个模型在不同测试集上的测试误差不同;
3)机器学习算法具有随机性,即便用同一个算法、同样的参数在同一个测试集上运行多次,测试结果也有可能不同。
若在某测试集上学习器A比B好,则A的泛化性能是否在统计意义上由于B,这个结论的把握又有多大???
假设检验
此处,“假设”指的是对样本总体的分布或已知分布中某个参数值的一种猜想。例如,假设模型泛化错误率为\epsilon _{0}(为假设),而测试误差为\epsilon _{1},两者是否相同???未必;但是两者接近的可能性应该比较大,相差很远的可能性比较小。因此可以通过测试错误率来推测泛化错误率的分布,这就是一种假设检验。

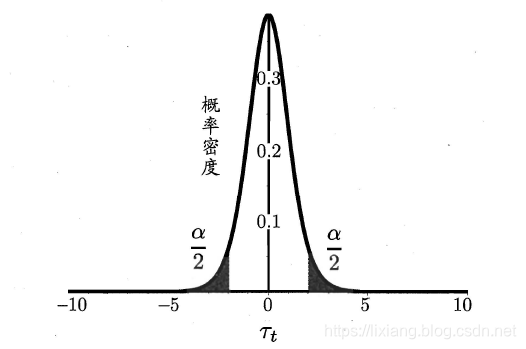
交叉验证t检验

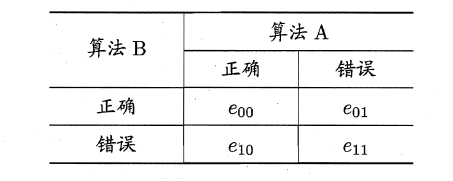
McNemar检验
MaNemar主要用于二分类问题,与成对t检验一样也是用于比较两个学习器的性能大小。主要思想是:若两学习器的性能相同,则A预测正确B预测错误数应等于B预测错误A预测正确数,即e01=e10,且|e01-e10|服从N(1,e01+e10)分布。
因此,如下所示的变量服从自由度为1的卡方分布,即服从标准正态分布N(0,1)的随机变量的平方和,下式只有一个变量,故自由度为1,检验的方法同上:做出假设–>求出满足显著度的临界点–>给出拒绝域–>验证假设。
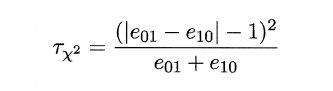
Friedman检验与Nemenyi后续检验
上述的三种检验都只能在一组数据集上,F检验则可以在多组数据集进行多个学习器性能的比较,基本思想是在同一组数据集上,根据测试结果(例:测试错误率)对学习器的性能进行排序,赋予序值1,2,3…,相同则平分序值,如下图所示:

若学习器的性能相同,则它们的平均序值应该相同,且第i个算法的平均序值ri服从正态分布N((k+1)/2,(k+1)(k-1)/12),则有:

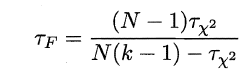
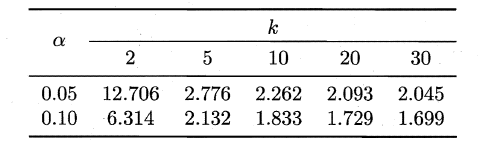
服从自由度为k-1和(k-1)(N-1)的F分布。下面是F检验常用的临界值:
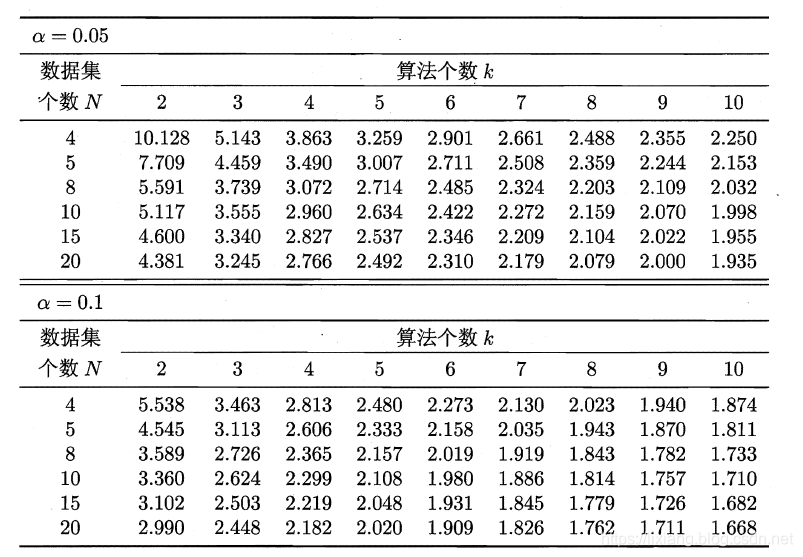
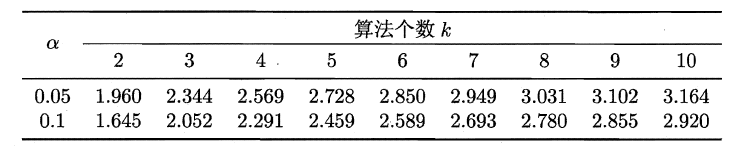
若“H0:所有算法的性能相同”这个假设被拒绝,则需要进行后续检验,来得到具体的算法之间的差异。常用的就是Nemenyi后续检验。Nemenyi检验计算出平均序值差别的临界值域,下表是常用的qa值,若两个算法的平均序值差超出了临界值域CD,则相应的置信度1-α拒绝“两个算法性能相同”的假设。
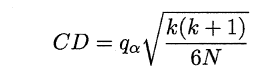
2.5偏差与方差
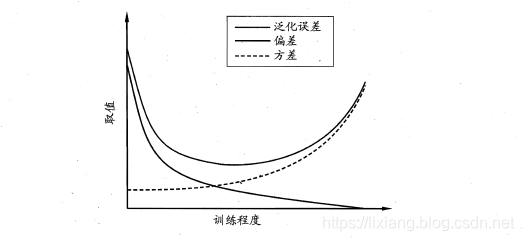
偏差-方差分解是解释学习器泛化性能的重要工具。在学习算法中,偏差指的是预测的期望值与真实值的偏差,方差则是每一次预测值与预测值得期望之间的差均方。实际上,偏差体现了学习器预测的准确度,而方差体现了学习器预测的稳定性。通过对泛化误差的进行分解,可以得到:
期望泛化误差=方差+偏差
偏差刻画学习器的拟合能力
方差体现学习器的稳定性
易知:方差和偏差具有矛盾性,这就是常说的偏差-方差窘境(bias-variance dilamma),随着训练程度的提升,期望预测值与真实值之间的差异越来越小,即偏差越来越小,但是另一方面,随着训练程度加大,学习算法对数据集的波动越来越敏感,方差值越来越大。换句话说:在欠拟合时,偏差主导泛化误差,而训练到一定程度后,偏差越来越小,方差主导了泛化误差。因此训练也不要贪杯,适度辄止。
PS:最后分享一个小故事,大家可以看一下“学生t氏检验”。哈~
