基本术语
- 数据集(data set):一组记录的集合。例如:(色泽=青绿;根蒂=稍蜷;敲声=沉闷)。
- 样本(sample):数据集中的每条记录,它是关于一个事件或对象的描述。又称示例(instance)。例如:色泽=青绿。
- 属性(attribute):反映事件或对象在某方面的表现或性质的事项。又称特征(feature)。例如色泽。
- 属性值(attribute value):属性上的取值。例如:青绿。
- 属性空间(attribute space):属性张成的空间。又称样本空间(sample space)。例如:把色泽、根蒂、敲声作为三个坐标轴,它们张成的一个描述西瓜的三维空间,每个西瓜都可以在这个空间中找到一个对应的坐标位置,这个点对应一个坐标向量,这个示例又称为一个“特征向量”(feature vector)。
- 学习(learning)/训练(training):从数据中学得模型的过程,这个过程是通过执行某个学习算法来完成。
- 训练数据(training data):训练过程中使用的数据。
- 训练样本(training sample):训练数据中的每个样本。
- 训练集(training set):训练样本组成的集合。
- 假设(hypothesis):学得模型对应了关于数据的某种潜在的规律。
- 学习器(learner):模型又称学习器。
- 标记(label):学得一个模型,仅有已有的示例数据是不够的。要建立一个关于“预测”(prediction)的模型,需要获得训练样本的“结果”信息。例如“((色泽=青绿;根蒂=稍蜷;敲声=浊响),好瓜)”。这里关于示例结果的信息“好瓜”,称为标记。
- 样例(example):拥有了标记信息的示例。
- 分类(classification):欲预测的是离散值。
- 回归(regression):欲预测的是连续值。
- 测试(testing):学得模型后,使用其进行预测的过程。
- 簇(cluster):将训练集中的记录分组,每个组就是一个簇。
- 聚类(clustering):将训练集分组的过程。
- 监督学习(supervised learning):训练数据既有特征(feature)又有标签(label),通过训练,让机器可以自己找到特征和标记之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。代表:分类和回归。
- 无监督学习(unsupervised learning):在只有特征没有标记的训练数据集中,通过数据之间的内在联系和相似性将他们分成若干类。代表:聚类。
- 泛化能力(generalization):学得模型适用于新样本的能力。
- 独立同分布(independent and identically distributed 简称i.i.d.):假设样本空间中全体样本服从一个未知的“分布”D,我们获得的每个样本都是独地从这个分布上采样获得的,即“独立同分布”。
- 归纳偏好:机器学习算法在学习过程中对某种类型假设的偏好,称为“归纳偏好”。与特征选择(feature selection)有关。
没有免费的午餐定理(No Free Lunch Theorem)
若学习算法La在某些问题上比学习算法Lb要好,那么必然存在另一些问题,在这些问题中Lb比La泛化能力强。
La在训练集之外的所有样本上的误差为:
- χ:样本空间。
- H:假设空间。
- La、Lb:学习算法。学习算法有其偏好性,对于相同的训练数据,不同的学习算法可以产生不同的假设,学得不同的模型,因此才会有哪个学习算法对于具体问题更好。这里这个没有免费的午餐定理要证明的就是:若对于某些问题算法La学得的模型更好,那么必然又有在另一些问题中,算法Lb学得的模型更好。这里的好坏在下文中使用算法对于所有样本的总误差来表示。
- P(h|X,La): 算法La基于训练数据X产生假设h的概率。既然前面有假设空间这个概念,那么假设h自然不止一个,并且对于整个空间的每一个h,P(h|X,La)的总和等于1。这里的假设是一个映射,是y=h(x),是基于数据X产生的对于学习目标(判断好瓜)的预测。因数据X不一样,所以可能产生不一样的假设h。
- f:希望学得的真实目标函数。这个函数不是唯一的,而是存在一个函数空间,在这个空间中按某个概率分布,下文证明中采用的是均匀分布。
继续回到这个公式:
- E是期望expectation,这个下标ote,是off-training error,即训练集外误差。
- Eote(La|X,f): 算法La学得的假设在训练集外的所有样本上的误差的期望。
- P(x): 样本空间中的每个样本的取得概率不同。比如:(色泽=浅白,根蒂=硬挺,敲声=清脆)的西瓜可能比(色泽=浅白,根蒂=稍蜷,敲声=沉闷)的西瓜更多,取到的概率更大。所以有P(x)这个概率。
- II(h(x)≠f(x)):指示函数,括号里为真就=1,为假就=0。
下面来理解一下求和符号:
- ∑h: 对假设的求和。这里我参考的博客博主,对于对假设的求和,也没有很好的解释。不知道这个对假设求和的空间到底是:同一个算法对于不同训练集产生不同的假设,每个假设有不同的概率;还是算法对于同一个训练集会产生不同的假设,每个假设有不同的概率。
- ∑x∈χ−X:对于样本空间中每一个训练集外的数据都进行右边的运算。
整体下来,这个公式的意思就是:
对于算法La产生的每一个不同的假设h,进行训练外样本的测试,然后测试不成功(因为求的是误差)指示函数就为1,并且两个概率相乘,最后所有的结果加起来,就是该算法在训练集外产生的误差。
然后下面考虑二分类问题,先要说明,对于我们想要求得的真实目标函数f可能也不止一个,这个好理解,因为满足版本空间中的假设的函数都可以是真实目标函数,然后这些不同的f有着相同的概率(均匀分布),函数空间为{0,1},那么有多少个这种函数呢?
我们来看对于同一个样本的这个预测值,对于样本空间χ中的某个样本x,如果f1(x)=0,f2(x)=1, 那么这就是两个不同的真实目标函数,所以对于某个样本可以区分出两个真实目标函数,一共有|χ|个样本,所以一共有2|χ|个真实目标函数,这些真实目标函数是等可能分布的(均匀分布),所以对于某个假设h(x)如果h(x)=0那么就有1/2的可能与真实目标函数相等。 所以下面公式中,
所以下面来看这个公式推导:
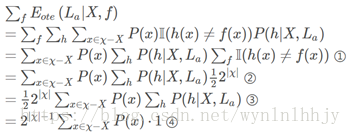
所以,可以得出总误差与学习算法无关。