8.1 个体与集成
所谓集成学习(ensemble learning)简单理解就是指采用多个分类器对数据集进行预测,从而提高整体分类器的泛化能力。
有时也被称为多分类系统,基于委员会的学习等。
8.2 Boosting
Boosting 是一种可将弱学习器提升为强学习器的算法。
自适应地改变训练样本的分布,使得弱分类器聚焦到那些很难分类的样本上。它的做法是每一个训练样本赋予一个权重,在每一轮训练结束后自动地调整权重。
弱分类器是串行的,因此是个迭代的过程。

8.3 Bagging与随机森林
bagging
Bagging方法也称为汇聚法(Bootstrap Aggregating),该模型是一种元评估器。方法过程为:在原始数据集上进行随机抽样(抽样可以是放回抽样与不放回抽样),使用得到的随机子集来训练评估器,该过程重复若干次。然后使用得到的若干个评估器(一次训练获取一个评估器),最后聚合每个单独的评估器的预测,形成最终的预测结果。
预测会使用多数投票(分类)或者求均值(回归)的方式来统计最终的结果(平均方法)。


1 优势
bagging方法通过随机抽样来构建原始数据集的子集,来训练不同的基本评估器,然后再将多个基本评估器进行组合来预测结果,这样可以有效减小基本评估器的方差。因此,通过bagging方法,就可以非常便捷的对基本评估器进行改进,而无需去修改基本评估器底层的实现。
因为bagging方法可以有效的降低过拟合,因此,bagging方法适用于强大而复杂的模型。
2 bagging分类示例
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
# sklearn.ensemble 该模块存放的都是关于集成算法相关的内容。
# BaggingClassifier sklearn中提供用于分类的bagging模型。
# RandomForestClassifier sklearn中体用用于分类的随机森林模型。
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier
from sklearn.model_selection import train_test_split
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_classes=3, random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=0)
lr = LogisticRegression()
lr.fit(X_train, y_train)
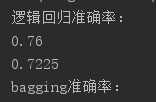
print("逻辑回归准确率:")
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
print("bagging准确率:")
# base_estimator:指定基本评估器。即bagging算法所组合的评估器。
# n_estimators:基本评估器的数量。(有多少个评估器,就会进行多少次随机采样,就会产生多少个原始数据集的子集。)
# max_samples:每次随机采样的样本数量。该参数可以是int类型或float类型。如果是int类型,则指定采样的样本数量。
# 如果是float类型,则指定采样占原始数据集的比例。
# max_features:每次随机采样的特征数量。可以是int类型或float类型。
# bootstrap:指定是否进行放回抽样。默认为True。
# bootstrap_features:指定对特征是否进行重复抽取。默认为False。
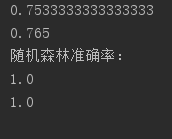
bag = BaggingClassifier(lr, n_estimators=100, max_samples=0.5, max_features=0.75)
bag.fit(X, y)
print(bag.score(X_train, y_train))
print(bag.score(X_test, y_test))
print("随机森林准确率:")
# n_estimators:随机森林评估器(决策树)的数量。
# criterion不存度度量方式。
# max_depth:树的最大深度。
# min_samples_split:节点最小分裂的样本数量。
# max_features:选择特征的数量。
# bootstrap:是否放回抽样。
rf = RandomForestClassifier(n_estimators=100, criterion="gini", random_state=0)
rf.fit(X, y)
print(rf.score(X_train, y_train))
print(rf.score(X_test, y_test))
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
# sklearn提供的用于回归的bagging模型。
# sklearn提供的用于回归的随机深林模型。
from sklearn.ensemble import BaggingRegressor, RandomForestRegressor
from sklearn.model_selection import train_test_split
X, y = load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=0)
lr = LinearRegression()
lr.fit(X_train, y_train)
print("线性回归R ^ 2值:")
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
bag = BaggingRegressor(lr, n_estimators=100, max_samples=0.5, max_features=0.75)
bag.fit(X, y)
print("bagging R ^ 2值:")
print(bag.score(X_train, y_train))
print(bag.score(X_test, y_test))
print("随机森林准确率:")
rf = RandomForestRegressor(n_estimators=100, criterion="mse", random_state=0)
rf.fit(X, y)
print(rf.score(X_train, y_train))
print(rf.score(X_test, y_test))

随机森林
随机森林(Random Forest)是一种元评估器,其使用原始数据集的子集来训练多棵决策树,并使用平均方法来计算预测结果。在随机森林中,用于训练决策树的子集样本数量与原始数据集的样本数量是相同的,其实现为:
从原始数据集中选出m个样本用于训练(原始数据集的样本数量也为m)。
使用这m个样本来构建一棵决策树。
从所有特征中随机选择K个特征(特征不重复)。
根据目标函数的要求(如最大信息增益),使用选定的特征对节点进行划分。
重复以上两步n次,即建立n棵决策树。
这n棵决策树形成随机森林,通过投票表决结果或均值决定最终的预测值。
关于随机森林,具有如下的说明:
用于训练决策树(基本评估器)的数据子集,其样本数量与原始数据集的样本数量相同。
默认情况下,随机森林中的决策树在拆分节点时,不再从所有特征中选择最优的特征,而是从随机的特征子集中,选择最优的一个特征。
由于这种随机性,随机森林的偏差通常会略微增加(相对于单个非随机决策树的偏差),但由于使用多棵决策树平均预测,其方差也会减小,从而从整体上来讲,模型更加优秀。
在分类预测时,scikit-learn中使用概率的平均值进行预测,而不是让每个分类器对单个类别进行投票。
对于回归任务,通常设置max_features=n_features,对于分类任务,通常设置max_features=sqrt(n_features)。
max_depth=None结合min_samples_split=2,通常可以获得很好的结果,但是,这往往会消耗大量的内存。
随机森林程序(with codes)
将之前bagging的两个示例,去掉注释,查看随机森林模型在分类与回归问题上的效果。
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
X, y = make_regression(n_samples=1000, noise=10, random_state=0, bias=5.5)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
lr = LinearRegression()
lr.fit(X_train, y_train)
print("线性回归结果:")
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
rf = RandomForestRegressor(n_estimators=100, criterion="mse")
rf.fit(X_train, y_train)
print("随机森林结果:")
print(rf.score(X_train, y_train))
print(rf.score(X_test, y_test))

# 葡萄酒数据集
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
X, y = load_wine(return_X_y=True)
# 为了可视化方便,简化操作,我们只取两个特征。
X = X[:, [0, 10]]
# 我们过滤掉0的类别,只取两个类别。
X = X[y != 0]
y = y[y != 0]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=0)
tree = DecisionTreeClassifier(criterion="entropy", max_depth=None)
tree = tree.fit(X_train, y_train)
print("决策树分类准确率:")
print(tree.score(X_train, y_train))
print(tree.score(X_test, y_test))
# n_jobs 开辟进程的数量。如果指定-1,则表示利用现有的所有CPU来实现并行化。
bag = BaggingClassifier(base_estimator=tree, n_estimators=100, max_samples=1.0, max_features=1.0,
bootstrap=True, bootstrap_features=False, n_jobs=-1, random_state=1)
bag = bag.fit(X_train, y_train)
print("bagging准确率:")
print(bag.score(X_train, y_train))
print(bag.score(X_test, y_test))
rf = RandomForestClassifier(n_estimators=100, criterion="gini", random_state=0, max_depth=None)
rf.fit(X_train, y_train)
print("随机森林准确率:")
print(rf.score(X_train, y_train))
print(rf.score(X_test, y_test))

# 葡萄酒数据集
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
X, y = load_wine(return_X_y=True)
# 为了可视化方便,简化操作,我们只取两个特征。
X = X[:, [0, 10]]
# 我们过滤掉0的类别,只取两个类别。
X = X[y != 0]
y = y[y != 0]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=0)
tree = DecisionTreeClassifier(criterion="entropy", max_depth=None)
tree = tree.fit(X_train, y_train)
print("决策树分类准确率:")
print(tree.score(X_train, y_train))
print(tree.score(X_test, y_test))
# n_jobs 开辟进程的数量。如果指定-1,则表示利用现有的所有CPU来实现并行化。
bag = BaggingClassifier(base_estimator=tree, n_estimators=100, max_samples=1.0, max_features=1.0,
bootstrap=True, bootstrap_features=False, n_jobs=-1, random_state=1)
bag = bag.fit(X_train, y_train)
print("bagging准确率:")
print(bag.score(X_train, y_train))
print(bag.score(X_test, y_test))
rf = RandomForestClassifier(n_estimators=100, criterion="gini", random_state=0, max_depth=None)
rf.fit(X_train, y_train)
print("随机森林准确率:")
print(rf.score(X_train, y_train))
print(rf.score(X_test, y_test))
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
cmap = ListedColormap(["r", "g"])
marker = ["o", "v"]
x1_min, x2_min = np.min(X_test, axis=0)
x1_max, x2_max = np.max(X_test, axis=0)
x1 = np.linspace(x1_min - 1, x1_max + 1, 100)
x2 = np.linspace(x2_min - 1, x2_max + 1, 100)
X1, X2 = np.meshgrid(x1, x2)
plt.figure(figsize=(18, 6))
name = ["决策树", "bagging", "随机森林"]
for index, estimator in enumerate([tree, bag, rf], start=1):
plt.subplot(1, 3, index)
for i, class_ in enumerate(np.unique(y)):
Z = estimator.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape)
plt.contourf(X1, X2, Z, cmap=cmap, alpha=0.5)
plt.scatter(x=X_test[y_test == class_, 0], y=X_test[y_test == class_, 1],
c=cmap(i), label=class_, marker=marker[i])
plt.title(name[index - 1])
plt.xlabel("色度")
plt.ylabel("酒精含量")
plt.legend()
plt.show()
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
cmap = ListedColormap(["r", "g"])
marker = ["o", "v"]
x1_min, x2_min = np.min(X_test, axis=0)
x1_max, x2_max = np.max(X_test, axis=0)
x1 = np.linspace(x1_min - 1, x1_max + 1, 100)
x2 = np.linspace(x2_min - 1, x2_max + 1, 100)
X1, X2 = np.meshgrid(x1, x2)
plt.figure(figsize=(18, 6))
name = ["决策树", "bagging", "随机森林"]
for index, estimator in enumerate([tree, bag, rf], start=1):
plt.subplot(1, 3, index)
for i, class_ in enumerate(np.unique(y)):
Z = estimator.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape)
plt.contourf(X1, X2, Z, cmap=cmap, alpha=0.5)
plt.scatter(x=X_test[y_test == class_, 0], y=X_test[y_test == class_, 1],
c=cmap(i), label=class_, marker=marker[i])
plt.title(name[index - 1])
plt.xlabel("色度")
plt.ylabel("酒精含量")
plt.legend()
plt.show()

8.4 综合策略
集成算法,介绍完后,那么如何使结合后的集成算法明显的优势呢?也就是说如何将训练出来的多个基学习器如何很好的结合在一起呢形成新的集成算法呢?本书提出平均法、投票法、学习法三种结合策略。
8.5 多样性
多样性,在前面已经提到过,一个好集成算法,需要训练出来的基学习器具有很强的多样性。
(1)误差-分歧分解
(2)多样性度量
(3)多样性增强
在集成学习中需要有效地生成多样性大的个体学习器。如果增强多样性呢?一般思路是在学习过程中引入随机性,常见的做法是对数据样本、输入属性、输出表示、算法参数进行扰动。
Adaptive Boosting(AdaBoost)是一种迭代算法。每轮迭代中会在训练集上产生一个新的学习器,然后使用该学习器对所有样本进行预测,以评估每个样本的重要性。
算法会为每个样本赋予一个权重,每次用训练好的学习器标注/预测各个样本,如果某个样本点被预测的越正确,则将其权重降低;否则提高样本的权重。权重越高的样本在下一个迭代训练中所占的比重就越大,也就是说越难区分的样本在训练过程中会变得越重要。整个迭代过程直到错误率足够小或者达到一定的迭代次数为止。

