今日份打卡~
一定要读到最后啊,越往后越干货。@!@
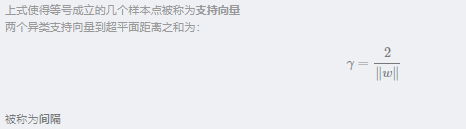
6.1 间隔与支持向量机


6.2 对偶问题

SMO
Platt的SMO算法是将大优化问题分解为许多小优化问题求解的,并且对它们顺序求解的结果与将它们作为整体求解的结果是完全一致的,时间还要短得多。
SMO算法的工作原理是:每次循环中选择两个alpha进行优化处理。一旦找到一对合适的alpha,那么就增大其中一个同时减小另一个。这里所谓的合适就是指两个alpha必须在间隔边界之外,或还没进过区间化处理或者不在边界上。(这个实现起来比较复杂,不作证明与实现)
6.3 核函数
前面在场景5里面我们有提到kernel技巧。我们SVM在处理线性不可分的问题是,通常将数据从一个特征空间转换到另一个特征空间。在新的特征空间下往往有比较清晰的测试结果。我们总结得到,如果原始空间是有限维的,即属性有限,那么一定存在一个高维特征空间使样本可分。
SVM中优化目标函数是写成内积的形式,向量的内积就是俩哥哥向量相乘得到单个标量或数值,我们假设ϕ(x)ϕ(x)表示将xx映射后的特征向量,那么优化目标函数变成:

6.4 软间隔与正则化
允许支持向量机在一些样本上出错,为此要引入”软间隔“(soft margin)的概念。

6.5 支持向量回归
回归和分类从某种意义上讲,本质上是一回事。SVM分类,就是找到一个平面,
让两个分类集合的支持向量或者所有的数据(LSSVM)离分类平面最远;
SVR回归,就是找到一个回归平面,让一个集合的所有数据到该平面的距离最近。
SVR的代价函数和SVM的很相似,但是最优化的对象却不同,对偶式有很大不同,解法同样都是基于拉格朗日的最优化问题解法。求解这类问题的早期解法非常复杂,后来出来很多新的较为简单的解法,对数学和编程水平要求高,对大部分工程学人士来说还是颇为复杂和难以实现,因此大牛们推出了一些SVM库。比较出名的有libSVM,该库同时实现了SVM和SVR。
我们来看一个简单的例子,数据为[-5.0,9.0]的随机数组,函数为y=12x2+3x+5+noise,我分别使用三种核SVR:两种惩罚系数rbf和一种poly。结果如下:
from sklearn import svm
import numpy as np
from matplotlib import pyplot as plt
X = np.arange(-5.,9.,0.1)
X=np.random.permutation(X)
X_=[[i] for i in X]
#print X
b=5.
y=0.5 * X ** 2.0 +3. * X + b + np.random.random(X.shape)* 10.
y_=[i for i in y]
rbf1=svm.SVR(kernel='rbf',C=1, )#degree=2,,gamma=, coef0=
rbf2=svm.SVR(kernel='rbf',C=20, )#degree=2,,gamma=, coef0=
poly=svm.SVR(kernel='poly',C=1,degree=2)
rbf1.fit(X_,y_)
rbf2.fit(X_,y_)
poly.fit(X_,y_)
result1 = rbf1.predict(X_)
result2 = rbf2.predict(X_)
result3 = poly.predict(X_)
plt.plot(X,y,'bo',fillstyle='none')
plt.plot(X,result1,'r.')
plt.plot(X,result2,'g.')
plt.plot(X,result3,'c.')
plt.show()
运行结果:
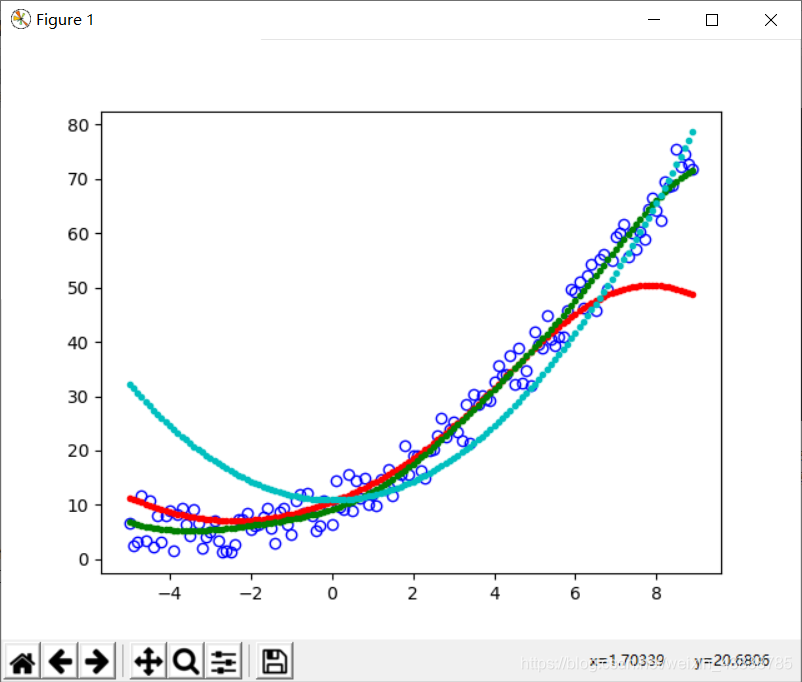
蓝色是poly,红色是c=1的rbf,绿色是c=20的rbf。其中效果最好的是c=20的rbf。如果我们知道函数的表达式,线性规划的效果更好,但是大部分情况下我们不知道数据的函数表达式,因此只能慢慢试验,SVM的作用就在这里了。就我来看,SVR的回归效果不如神经网络。
6.6 核方法

SVM训练
关于SVM的模型构建并不需要花费太多的经历,自己构建这样一个模型始终是吃力不讨好的事情,各种编程语言都有自己的机器学习工具库,其中已经实现了SVM算法。Python比较常用的机器学习库是scikit-learn。
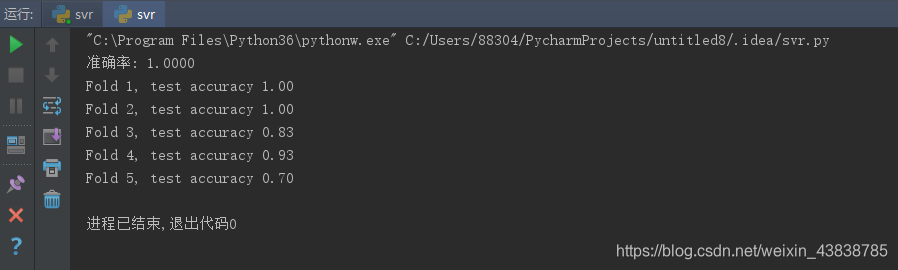
下面使用SVM分类器实现最为基础的鸢尾花数据集的分类,采用多次划分的5折交叉验证,测试模型表现,可以看到,不经过大量搜参的默认模型效果不错。
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, KFold
import numpy as np
def build_model():
"""
建立模型
:return:
"""
svc = SVC(C=1.0, kernel='rbf', gamma='scale')
return svc
if __name__ == '__main__':
data = load_iris()
x, y = data.data, data.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=2019)
model = build_model()
model.fit(x_train, y_train)
print("准确率: {:.4f}".format(np.sum(y_test == model.predict(x_test)) / y_test.shape[0]))
# 交叉验证效果
kf = KFold(n_splits=5)
i = 0
for train_index, test_index in kf.split(x):
train_x, train_y = x[train_index], y[train_index]
test_x, test_y = x[test_index], y[test_index]
model = build_model()
model.fit(train_x, train_y)
acc = np.sum(test_y == model.predict(test_x)) / test_y.shape[0]
print("Fold {}, test accuracy {:.2f}".format(i+1, acc))
i += 1
运行结果: