Very Power Efficient Neural Time-of-Flight
Abstract
In this paper, we show that despite the weak signals in many areas under extreme short exposure setting, these signals as a whole can be well utilized through a learning process which directly translates the weak and noisy ToF camera raw to depth map.
在本文中,我们证明了在极短曝光设置下,尽管许多地区的信号都很弱,但这些信号作为一个整体,可以通过一个直接将弱噪声ToF camera raw转换成深度图的学习过程得到很好的利用。
1.Introduction

2. ToF cameras compute the depth by emitting a periodic amplitude modulated illumination signal and receive the demodulated signal reflected by the objects. Higher power of active illumination enables the ToF sensor to receive the signal with higher signal noise ratio (SNR) and higher level of confidence. Therefore, the power of illumination directly influences the performance of ToF cameras.
ToF相机通过发出周期性调幅照明信号来计算深度,并接收被物体反射的解调信号。主动照明功率越大,ToF传感器接收到的信号信噪比越高,置信度越高。因此,光照的强弱直接影响ToF相机的性能。
3. Traditional ToF imaging algorithms are very sensitive to illumination and the depth accuracy degenerates rapidly with the decreasing illumination power.
传统的ToF成像算法对光照非常敏感,随着光照功率的降低,深度精度迅速下降。
4. an alternative treatment to this issue is to increase the physical size of the pixels on the sensor to collect more light.However, this significantly decreases the depth map resolution.According to the inverse square law, one can also cut the depth sensing range of the camera. This obviously decreases the usability of the camera in many applications.
解决这个问题的另一种方法是增加传感器上像素的物理大小来收集更多的光。然而,这大大降低了深度地图的分辨率。根据平方反比定律,还可以减少相机的深度感知范围。这明显降低了相机在许多应用程序中的可用性。
5. Such dilemma can be tackled if there is a way to recover high quality depth information from weak signals.如果有办法从微弱信号中恢复高质量的深度信息,就可以解决这一难题。
6. Chen et al. [2] showed impressive results on recovering high quality color image from camera Bayer pattern which is captured under extremely low light condition with short exposure.Chen等人在极低光照条件下短时间曝光的Bayer模式下对高质量彩色图像的恢复效果令人印象深刻。
7. To enable the learning, we collect a comprehensive dataset under a variety of scenes and photographic conditions via a specialized ToF camera. The dataset contains ToF raw measurements and depth maps collected under extreme short exposure settings and long exposure settings respectively.为了使学习成为可能,我们通过专门的ToF相机在各种场景和摄影条件下收集了一个全面的数据集。数据集包含在极端短曝光和长曝光设置下收集的ToF原始测量值和深度图。
8. contributions::::
8.1 We show for the first time that our proposed method is able to recover high quality depth information from very weak ToF raw data (one order of magnitude shorter exposure time).我们首次证明,我们提出的方法能够从非常弱的ToF原始数据(一个数量级的短曝光时间)中恢复高质量的深度信息。
8.2 We introduce a real-world dataset used for training and validating the this learning tasks.
8.3 We shed light on the design of the next generation ToF camera by providing an effective alternative to optimize the performance and power consumption tradeoff.
2.Related work
Depth reconstruction based on ToF cameras
- ToF cameras face a lot of challenging problems when extracting depth from raw phase-shifted measurements with respect to emitted modulated infrared signal. Dorrington et al. [4] established a two-component, dual-frequency approach to resolving phase ambiguity, achieving significant improvements of the accuracy when distortion is caused by multipath interference (MPI)
ToF相机在对发射调制红外信号进行原始相移测量深度提取时,面临着许多具有挑战性的问题。Dorrington等人的[4]建立了一种双分量双频方法来解决相位模糊,实现了在多径干扰(MPI)导致失真时显著提高精度。 - Several methods were proposed to deal with MPI distortions, including adding or modifying hardware [32, 11, 24], employing multiple modulation frequencies [4, 5, 1, 9] and estimating light transport through an approximation of depth [6, 7].提出了几种处理MPI畸变的方法,包括增加或修改硬件[32,11,24],使用多重调制频率[4,5,1,9]和通过近似深度估计光传输[6,7]。
- Marco et al. [20] correct MPI errors by a two-stage training strategy, training the encoder to represent MPI-corrupted depth images with captured dataset firstly and then use synthetic scenes to train the decoder to correct the depth. However, the above pipelines are based on the assumption that there is no cumulative error and information loss introduced in the previous stage, thus the final result of these methods is likely to contain cumulative errors of multiple stages.Marco等人采用两阶段训练策略对MPI错误进行校正,首先用捕获的数据集训练编码器表示被MPI破坏的深度图像,然后利用合成场景训练解码器进行深度校正。但是,以上的管道都是基于前一阶段没有引入累积误差和信息丢失的假设,因此这些方法的最终结果很可能包含多个阶段的累积误差。
- Krishna et al. [33] filled the missing depth pixels by using a color-aware Gaussian-weighted averaging filter to estimate depth value. However, its performance is limited by the similarity between the neighborhood pixels and target pixels and the information of the target region is wasted.Krishna等人使用一种颜色感知的高斯加权平均滤波器来估计深度值,并用[33]填充缺失的深度像素。然而,由于邻域像素与目标像素之间的相似性,使得目标区域的信息被浪费。
- An end-to-end ToF image processing framework presented by Su et al. [30] can efficiently reduce noise, correct MPI and resolve phase ambiguity. However, the training data is not realistic. Therefore, depth reconstruction may fail when the scene contains low reflectivity materials and objects. To the best of our knowledge, none of existing depth reconstruction method is able to obtain high quality depth map from the weak and noisy ToF camera raw measurements.Su等人提出的端到端ToF图像处理框架可以有效地降低噪声,纠正MPI,解决相位模糊问题。然而,训练数据是不现实的。因此,当场景中含有较低反射率的材料和物体时,深度重建可能会失败。据我们所知,现有的深度重建方法没有一种能够从弱噪声的ToF相机原始测量数据中获得高质量的深度图。
Image enhancement under low light.
- For conventional RGB cameras, photography in low light is challenging. Several techniques have been proposed to increase the SNR of the recovered image [8, 23, 17, 18, 3].
- Chen at el.[2] established a pipeline by training a fully convolutional neural network which directly translate the very noise and dark Bayer pattern camera raw to high quality color images. Though impressive results from the aforementioned studies, deep learning and data-driven approaches have not yet been adopted to recover high quality depth information from weak and noisy ToF raw. It remains unclear if such methodology is effective for ToF imaging. The aim of this paper is to disclose its feasibility陈el。[2]通过训练全卷积神经网络建立了管道,该神经网络直接将非常噪声和暗Bayer模式的原始图像转换为高质量的彩色图像。尽管上述研究取得了令人印象深刻的结果,但深度学习和数据驱动方法尚未被用来从弱噪声ToF raw中恢复高质量的深度信息。目前尚不清楚这种方法是否对ToF成像有效。本文的目的是揭示其可行性
Depth datasets.
- Although recently many datasets of depth maps are proposed, most of them are consisted of synthetic data, such as transient images generated via time-resolved rendering.虽然最近提出了许多深度图数据集,但大多数数据集是由合成数据组成的,如通过时间分辨渲染生成的瞬态图像。
- A dataset of ToF measurements [20] is proposed via simulating 25 different scenes with a physically-based, time-resolved renderer.通过使用基于物理的时间分辨渲染器模拟25个不同的场景,提出了一个ToF测量[20]数据集。
- Besides, Su et al. [30] offer a largescale synthetic dataset of raw correlation time-of-flight with ground truth labels. However, the ToF raw with artificial distortions and Gaussian noise is not realistic enough to support the real life generalization especially when dealing with areas with large noise caused by low reflectivity.此外,Su等人的[30]提供了一个大规模的原始相关飞行时间与地面真值标签的合成数据集。然而,含有人工畸变和高斯噪声的ToF raw在处理低反射率引起的大噪声区域时,还不能很好地支持真实的生活泛化。
- Only the raw RGB data, depth map and accelerometer data are provided in the NYU-Depth V2 dataset [22] but ToF raw measurements are missing.Thus, this dataset can not be used to train ToF raw to depth map conversion.NYU-Depth V2数据集[22]只提供原始的RGB数据、深度地图和加速度计数据,但是ToF原始测量数据却缺失了。因此,该数据集不能用于训练ToF raw到深度映射的转换。
- In this paper, we propose a comprehensive dataset to fill these gaps and enable the training and validation of our proposed model.
3.Method and Analysis
3.1 Imaging with TimeofFlight Sensors
Distance measurement
- The distance measurement mode of Time of Flight uses the on chip driver and the external LED/LD to provide modulated light on the target. Generally, the period of the modulation control signal is programmable. The modulator generates all signals to modulate the external LED/LD and simultaneously all demodulation signals to the pixel-field. We can describe the programmable modulation optical signal with angular frequency ! as
飞行时间的距离测量模式使用芯片驱动器和外部LED/LD对目标提供调制光。一般来说,调制控制信号的周期是可编程的。该调制器产生所有信号来调制外部LED/LD,同时将所有解调信号发送到像素场。我们可以用角频率来描述可编程调制光信号Ω作为
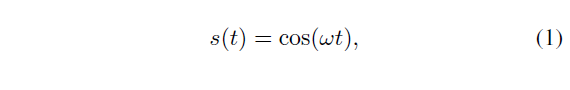
where the amplitude is normalized. Once the signal is reflected by the object, the modulated optical signal goes back to the sensor with certain amplitude attenuation and certain phase shift, then the received signal can be expressed as
这里的振幅是标准化的。当信号被物体反射后,经过调制的光信号以一定的振幅衰减和一定的相移返回到传感器,则接收到的信号可以表示为
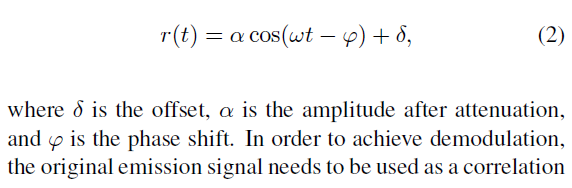

Quality of the measurement result.
Raw ToF measurements contain the distance information, as well as the quality and the validity (confidence level) of the received optical signal. A higher amplitude of the measured signal represents a more accurate distance measurement. The depth data for each pixel has its own validity and quality in ToF cameras. The amplitude of the modulated light received by the ToF sensor is the primary quality indicator for the measured distance data. It can be calculated as Eq.5. However, excessive active illumination will make the amplitude of the raw measurements very large.This leads to errors in the depth value due to the problem of over-exposure of the ToF sensor.
原始ToF测量包含距离信息,以及接收到的光学信号的质量和有效性(置信水平)。被测信号的振幅越大,表示距离测量越精确。在ToF相机中,每个像素的深度数据都有自己的有效性和质量。ToF传感器接收到的调制光幅值是测量距离数据的主要质量指标。它可以被计算为方程5。然而,过多的主动照明会使原始测量的振幅非常大。
Problems of Traditional Pipeline.
In order to recover high-quality depth maps from imperfect ToF raw measurements, traditional methods of ToF camera imaging often require a series of specialized processing techniques, such as denoising, correction of multipath distortion and nonlinear compensation, etc. However, these components are independent to each other and often relies on the assumption of no cumulative error and information loss in the previous stages. In practice, this assumption is almost always not true. It may cause large errors in the final depth map. To alleviate the overall error, a distance calibration process is conducted to adjust the offset value to the selected calibration plane and sets the Fix Pattern Noise (FPN) on the plane to zero. However, this technique can not be generalized to scenarios of weak signals.
为了从不完善的ToF原始测量中恢复高质量的深度图,传统的ToF相机成像方法往往需要一系列专门的处理技术,如去噪、多径畸变校正和非线性补偿等。但是,这些组件彼此独立,并且通常依赖于前一阶段没有累积错误和信息丢失的假设。实际上,这种假设几乎总是不正确的。它可能会在最终的深度图中造成较大的错误。为了减轻整体误差,通过距离校准过程将偏移量调整到选定的校准平面,并将平面上的固定模式噪声(FPN)设置为零。然而,这种技术不能推广到弱信号的情况下。
As mentioned above, the amplitude of the modulated signal received by the ToF sensor is the primary quality indicator for the measured distance data. When the amplitude is lower than a certain threshold, the traditional ToF imaging method is unable to calculate a reliable depth value at such a low SNR, so that the depth information is missing in these areas (behave as a black hole on the depth map). The experiment results show that the condition for invalidating the traditional ToF camera imaging pipeline in a pixel as
如上所述,ToF传感器接收到的调制信号的幅值是测量距离数据的主要质量指标。当振幅低于某一阈值时,传统的ToF成像方法无法在如此低的信噪比下计算出可靠的深度值,导致这些区域的深度信息缺失(在深度图上表现为黑洞)。实验结果表明,传统的以像素为单位的ToF相机成像管道失效的条件为

3.2. Learning from imperfect ToF camera raw
In this section, our approach of depth reconstruction is presented in detail.
- We first describe the advantage of our method of recovering high-quality depth images from weak and noisy ToF camera raw measurements compared to traditional
ToF imaging methods. - Then, we give a brief description of our whole pipeline to learn a mapping from
ToF measurements acquired under low power illumination to corresponding high-quality depth map. - And the network architecture of our method, as shown in Tab.1, will be introduced. Finally, we present how we train the model and implementing details.
Comparison to traditional pipeline.
- The raw ToF measurements have a very low signal-to-noise ratio (SNR) and amplitude intensity, when the active illumination signal received by the ToF sensor is very low.In this case, conventional edge aware filtering methods such as bilateral filter tend to fail.
当ToF传感器接收到的主动照明信号非常低时,原始ToF测量的信噪比(SNR)和振幅强度非常低。在这种情况下,传统的边缘感知滤波方法如双边滤波往往会失败。 - Traditional method of ToF measurements denoising is based on arbitrary rules and assumptions, but these rules and assumptions often become invalid with changes in scenes and intensity of the received signals.Therefore, it is very difficult to select the optimal parameters for all the image processing components to achieve good results for all scenarios.传统的ToF测量去噪方法是基于任意规则和假设的,但这些规则和假设往往随着接收信号场景和强度的变化而失效。因此,很难为所有的图像处理组件选择最优的参数,以实现对所有场景的良好效果。
- In contrast, the proposed method adopts the end-to-end learning and inference approach to translate the weak and noisy ToF camera raw to high quality depth map which avoids the highly complex parameter tuning for such noisy and weak input signals.相比之下,该方法采用端到端学习推理的方法将弱噪声的ToF camera raw转换成高质量的深度图,避免了对这种噪声微弱的输入信号进行高度复杂的参数调整。
Our pipeline.

- Most of them have adopted an encoderdecoder network with or without skip connections [26], which are consisted of down-sampling, residual blocks and up-sampling.The pixel value of ToF depth map is closelyrelated to camera settings, scene architecture and layout, compared with RGB images. Besides, the geometry and architecture of scene for both depth map and raw measurements are required to be consistent. And these specific characteristics of ToF raw measurements should be combined with the previous work of image translation, when designing network architecture.
其中大部分采用带或不带跳接[26]的编码器译码器网络,由下采样、剩余块和上采样组成。与RGB图像相比,ToF深度图的像素值与相机设置、场景架构和布局密切相关。此外,场景的几何结构和深度地图和原始测量都需要是一致的。在设计网络体系结构时,应将ToF原始测量数据的这些特性与之前的图像翻译工作相结合。 - For the above considerations, we select the encoderdecoder with skip connections as our network architecture.
- The size of input is progressively decreasing in pace with going through the down-sampling layers for four times, until it reaches the residual blocks. And after passing through nine residual blocks and four up-sampling layers, the size of input becomes larger and restored to its original size.strided convolution layers combined with activation layers serve as decoder and the fractional convolution layers combined with activation layers are regarded as encoder. The residual blocks without normalization are adopted by the bottle neck part. Moreover, we added the skip connections to the network between each pair of layer i and layer n-i following the U-net to enhance the accurate of results.
输入的大小是逐步减少的速度通过向下采样层四次,直到它到达剩余块。经过9个残差块和4个上采样层后,输入的大小变大,恢复到原来的大小。结合激活层的跨步卷积层作为解码器,结合激活层的分数卷积层作为编码器。未归一化的残块被瓶颈部分采用。此外,我们在U-net之后的每一对层i和层n-i之间增加了网络的跳跃连接,以提高结果的准确性。 - To obtain high-quality depth reconstruction results, L1 loss is adopted to train our network
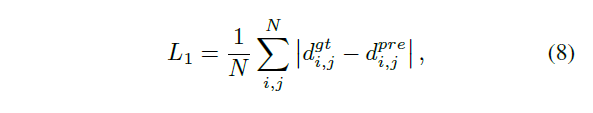
Training details.
- Pytorch.
- inputs of the network are the ToF raw measurements captured under short exposure and the ground truth is the corresponding depth map captured under regular or long exposure.
网络的输入是在短时间曝光下捕获的ToF原始测量值,而地面真值是在常规或长时间曝光下捕获的相应深度图。 - We randomly crop out 128128 images on the original 320240 images for data augmentation. This strategy effectively improves the robustness of the model.我们在原始的320240张图片上随机裁剪出128128张图片来增加数据。该策略有效地提高了模型的鲁棒性。
- We train our network using the Adam optimizer [16] with an initial learning rate of 0.0002 for the first 200 epochs, before linearly decaying it to 0 over another 1800 epochs.我们使用Adam优化器[16]对我们的网络进行训练,在前200个纪元中初始学习率为0.0002,然后在1800个纪元中将其线性衰减为0。
4. Dataset
- we can modify the intensity of received signal by changing the exposure time of the ToF camera, since the exposure time is directly proportional to the intensity of received signal.我们可以通过改变ToF相机的曝光时间来改变接收信号的强度,因为曝光时间与接收信号的强度成正比。
- We use EPC660 ToF camera from ESPROS to collect a dataset of multiple pairs of short-exposure and corresponding long-exposure depth measurements for training the proposed architecture.
- ToF raw measurements, amplitude image and depth map at 320240 resolution are collected for each scene with an exposure time. We captured 200 groups of measurements with 200us and 400us exposure time respectively and 200 groups of corresponding long-exposure images from a variety of scenes with varying materials. During the experiments, we use 150 groups for training and 50 groups for testing.ToF的原始测量,振幅图像和深度地图在320240分辨率下收集每个场景与曝光时间。我们分别用200us和400us曝光时间拍摄了200组测量数据,并从不同材质的场景中拍摄了200组对应的长时间曝光图像。在实验中,我们使用150组进行训练,50组进行测试。
- Diverse indoor scenes are collected in the dataset, including office room, restaurant, bedroom and laboratory. We adopt the ideal sinusoidal modulation functions to avoid the wiggling effect. The images are generally captured at night in rooms without infrared monitoring to avoid the influence of solar radiation and infrared light emitted by some particular machines. Note that a variety of hard cases such as distant objects, fine structures, irregular shapes and various materials including fabric, metals with low reflectivity and dark object with high absorptivity exist in our scenes.数据集中收集了各种室内场景,包括办公室、餐厅、卧室和实验室。我们采用理想的正弦调制函数来避免振荡效应。这些图像通常是在没有红外线监控的房间里拍摄的,以避免太阳辐射和某些特定机器发出的红外光的影响。需要注意的是,在我们的场景中存在着各种各样的硬物,比如远处的物体,精细的结构,不规则的形状,以及各种材料,包括织物,反射率低的金属和高吸收率的暗物体。
- We mount the ToF camera on a sturdy tripod to avoid camera shaking and other vibration when capturing. Due to continuous modulation, 6MHz was selected as modulation frequency for measuring depth in our scenes with range of
0-6 meters to prevent roll-over being observed. Then exposure time is adjusted to obtain high-quality raw data. After long-exposure ToF measurements captured, we decrease the exposure time to 200 us and 400 us respectively via software on computers to collect data without touching the cameras.
A mask to evaluate the quality of ToF measurements will be introduced into our dataset. Actually, the quality and validity of the received signal exists in raw data collected by ToF cameras. The signal amplitude as well as the ratio of ambient-light EBW to the value of modulated light
EToF (AMR) indicates the quality and validity of received signal. We combine these two features of received signals in a certain proportion to generate a quantitative criteria for evaluating the quality of each pixel in measurements.A threshold for criteria can be defined to produce a mask for each pixel. This mask can be adopted in network training and depth map generation. For instance, unconfident pixels in the labels can be ignored during the computation of error gradients in training.我们将ToF相机安装在一个坚固的三脚架上,以避免相机在拍摄时抖动和其他震动。由于是连续调制,所以我们选择6MHz作为调制频率来测量场景深度,测量范围为
0-6米,防止翻车。然后调整曝光时间,获得高质量的原始数据。在长时间曝光ToF测量数据后,我们通过计算机上的软件,在不接触相机的情况下,将曝光时间分别减少到200 us和400 us。
一个评估ToF测量质量的掩模将被引入.标准的阈值可以被定义为为每个像素生成一个掩码。该掩模可用于网络训练和深度地图生成。例如,在计算训练中的误差梯度时,可以忽略标签中不可靠的像素。 - Fig.3 shows quantitative analysis of depth-range distribution of ToF measurements in our dataset. The depth range is reasonable for indoor scenes of our dataset, for depth values range from 0cm to 591cm and has a mean of 236.88cm. There are some regions with no depth value or much noise when short-exposure, due to few reflected photons detected. The ToF measurements is sufficient to serve as ground truth, though some noise still exists.图3是对数据集中ToF测量值深度范围分布的定量分析。深度范围对于我们数据集的室内场景来说是合理的,深度值的范围从0cm到591cm,平均值为236.88cm。由于探测到的反射光子较少,在短时间曝光时,有些区域没有深度值或噪声较大。虽然仍然存在一些噪声,但ToF测量值足以作为地面真值。
7.
5. Experiments and Results
5.1. Qualitative results
- We first quantify depth error with the mean absolute error (MAE) and the structural similarity (SSIM) [34] of predicted depth map compared to the ground truth.
- At the same time, we will analyze the impact of different network structures on our results.
- Finally, we will quantitatively analyze the variation of the error of our method at different detection distances.
Effect of exposure time.
- We have trained two models on the ToF raw measurements under 200us and 400us exposure respectively, and tested the accuracy of the two models with the corresponding test set.
- As shown in Tab.2, our results meet an overall 7.94cm depth error with raw captured under 400us exposure time and 10.13cm with raw captured under 200us exposure time.如表2所示,我们的结果总的深度误差为7.94cm,原始数据在400us曝光时间下采集,10.13cm,原始数据在200us曝光时间下采集。

Effect of network structures.
- The network structure of the the least square GAN [19] is used to recover depth map from ToF raw measurements by [30], we also compare the impact of applying this structure to our framework on the results.使用最小二乘GAN[19]的网络结构来恢复[30]对ToF原始测量数据的深度图,我们还比较了将这种结构应用到我们的框架中对结果的影响。
- Tab.3 reports the result of replacing the U-net [26] (our default architecture) by the the least square GAN [19].

