Knowledge-Embedded Representation Learning
Authors

Abstract
- 研究如何将丰富的专业知识与深度神经网络架构统一起来,并提出了一个知识嵌入式表示学习(KERL)框架来处理细粒度图像识别问题。
- 以知识图的形式组织丰富的视觉概念,并使用门控图神经网络通过图传播节点消息以生成知识表示。
- 通过引入一种新颖的门控机制,KERL框架将这种知识表示形式纳入了判别性图像特征学习中,即,将特定属性与特征图隐式关联。
- 与现有的细粒度图像分类方法相比,KERL框架具有几个吸引人的属性:
a)嵌入的高级知识可增强特征表示,从而有助于区分下级类别之间的细微差异。
b)我们的框架可以以有意义的配置学习特征图,突出显示的区域与知识图的节点(特定属性)完全一致。
(一) Introduction
-
人类不仅基于物体的外观,而且还基于从日常生活或专业中获得的知识来执行物体识别任务。通常,此知识是指包括类别标签及其属性的全面视觉概念组织。
-
对于细粒度的图像分类而言,这非常有益,因为属性始终是区分不同下属类别的关键。
-
例如,我们可能从一本书中得知,“波希米亚连雀”类别的鸟的头顶上有黑白相间的颜色,翅膀上有虹彩的羽毛。有了这些知识,要识别给定鸟类图像的“波希米亚连雀”类别,我们可能首先会回想起该知识,参加相应的部分以查看其是否具有这些属性,然后进行推理。
-
图1举例说明了专业知识如何帮助进行细粒度的图像识别。

-
用于细粒度图像分类的常规方法通常会忽略此知识,而仅依靠低级图像提示进行识别。
-
利用自然语言描述来帮助搜索信息区域,并与视觉流结合以进行最终预测。集成了高级信息,但它直接为图像语言对建模,并且需要对每个图像进行详细的语言描述(例如,每个图像的十个句子)。
-
与这些方法不同,本论文以知识图的形式组织有关类别和基于零件的属性的知识,并制定了知识嵌入表示学习(KERL)框架,将知识图纳入图像特征学习中,以促进细粒度图像识别。
-
提出的框架能够将特定属性与图像特征表示相关联。
KERL框架包含两个关键组件:
- 门控图神经网络(GGNN),该节点通过图传播节点消息以生成知识表示;
- 一种新颖的门控机制将此表示形式与图像特征学习集成在一起,以学习属性感知特征。
具体步骤:
- 首先构建一个大规模的知识图,该图将类别标签与部件级属性相关联,如图2所示。
- 通过使用给定图像的信息初始化图节点,KERL框架可能会隐含地推理出该对象的判别属性并将它们与特征图相关联。通过这种方式,我们的KERL框架可以通过有意义的配置学习特征图,突出显示的区域与图中的相关属性紧密关联。
举例:
从“波希米亚连雀”类别中学习的样本特征图始终会突出显示头部和翅膀的区域,因为这些区域与属性“头部图案:遮罩”,“头部颜色:白色和黑色”和“翅膀:虹彩”相关”是区分此类别与其他类别的关键。此特征还提供了对为什么框架可以提高性能的深入了解。

图2:用于对Caltech-UCSD鸟类数据集上的类别-属性相关性进行建模的示例知识图。
论文贡献:
- 这项工作制定了一个新颖的知识嵌入式表示学习框架,该框架结合了高级知识图作为图像表示学习的额外指导。这是调查这一点的第一项工作。
- 在知识的指导下,论文框架可以学习具有意义且可解释的配置的属性感知特征图,其中突出显示的区域与图中的相关属性精细相关,这也可以解释性能的提高。
- 对广泛使用的Caltech-UCSD鸟类数据集进行了广泛的实验,并证明了所提出的KERL框架优于领先的细粒度图像分类方法。
(二) Related Work
从两个研究阶段回顾了相关工作:细粒度图像分类和知识表示。
2.1 Fine-Grained Image Classification
目前主流方法:
- 深度卷积神经网络(CNN)来学习判别性特征以进行细粒度图像识别。
- 首先定位区分区域,然后学习以这些区域为条件的外观模型。但是,这些方法涉及对象部分的大量注释,此外,手动定义的部分对于最终识别可能不是最佳的。
- 采用突出区域定位技术自动生成判别区域的边界框注释。
- 视觉注意力模型自动搜索信息区域。
- 引入循环注意力卷积神经网络,以递归学习多尺度的注意力区域和基于区域的特征表示。
- 利用局部属性指导关注区域的定位。
论文方法:
以知识图的形式组织类别-属性关系,并隐含地推理图表上的区别属性,而不是直接使用对象-属性对。
2.2 Knowledge Representation
目前主流方法:
- 使用马尔可夫逻辑网络学习知识库,并采用一阶概率推理来推理对象的承受能力。这些方法通常包含手工制作的功能和手动定义的传播规则,从而阻止了它们进行端到端训练。
- 根据图的边缘对图上的节点进行排序,以使其具有规则的顺序,并将其直接馈送到标准CNN进行特征学习。
GGNN:
- 一种完全可区分的递归神经网络体系结构,用于图结构化数据,该结构以递归方式将节点消息传播到其邻居,以学习节点级特征或图形级表示。
- 图神经网络变体,用于RGBD语义分割的3DGNN,用于情况识别的基于模型的GNN 。用于多标签图像识别的GSNN 。
- GSNN是将图像和知识特征连接起来进行图像分类。相反,此论文提出一种新的门机制将知识表示嵌入到图像特征学习中,以增强特征表示。此外,我们学到的特征图展示了有见地的配置,突出显示的区域与图中的语义属性很好地吻合。
(三)KERL Framework
主要任务:
- 回顾GGNN,
- 介绍将类别标签与其零件级属性相关联的知识图的构造。
- 详细介绍KERL框架,该框架由用于知识表示学习的GGNN和将知识嵌入判别式图像表示学习的门控机制组成。
框架的总体流程如图3所示。
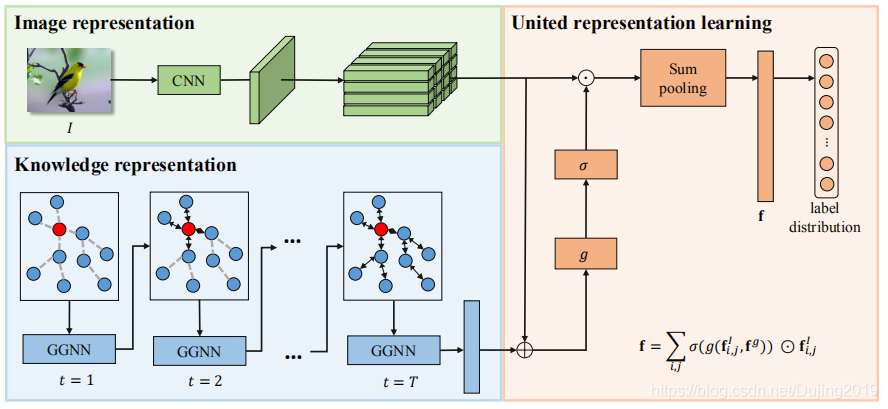
图3:知识嵌入式表示学习框架的总体流程。
图解: 该框架主要包括一个以知识图作为输入并通过该图传播节点信息以学习知识表示的GGNN,以及一个将表示嵌入到特征学习中以学习属性感知特征的门控机制。可以端到端的方式训练框架的所有组件。
3.1 Review of GGNN
- GGNN是递归神经网络体系结构,可以通过迭代更新节点特征来学习任意图结构数据的特征。
- 对于传播过程,输入数据表示为图形 G = { V , A } G=\left \{V,A\right \} G={ V,A},其中 V V V是节点集, A A A是邻接矩阵,表示图中节点之间的连接。对于每个节点 v ∈ V v∈V v∈V,它在时间步 t t t处具有隐藏状态 h v t h_{v}^{t} hvt,并且 t = 0 t = 0 t=0时的隐藏状态由输入特征向量 x v x_{v} xv初始化,该输入特征向量 x v x_{v} xv取决于当前的问题。
- 基本的循环过程表述为:

注释:
- A v A_{v} Av是A的子矩阵,表示节点 v v v与它的邻居的连接。
- σ σ σ和 t a n h tanh tanh分别是逻辑S形和双曲正切函数。
- ⊙ \odot ⊙表示逐元素乘法运算。
- 重复传播过程直到固定迭代 T T T,可以获得最终的隐藏状态 { h 1 T , h 2 T , . . . , h ∣ V ∣ T } \left \{h_{1}^{T},h_{2}^{T},...,h_{|V|}^{T}\right \} { h1T,h2T,...,h∣V∣T}。
- 为了简化符号,将等式 ( 1 ) (1) (1)的计算过程表示为 h v t = G G N N { h 1 t − 1 , . . . , h ∣ V ∣ t − 1 ; A v } h_{v}^{t}=GGNN\left \{h_{1}^{t-1},...,h_{|V|}^{t-1};A_{v}\right \} hvt=GGNN{ h1t−1,...,h∣V∣t−1;Av}。
3.2 Knowledge Graph Construction
知识图是指视觉概念库的组织,该视觉概念库包括类别标签和零件级属性,其中节点表示视觉概念,而边缘表示其相关性。
该图是根据训练样本的属性注释构建的。图2展示了CaltechUCSD鸟类数据集的示例知识图。
Visual concepts.
- 视觉概念是指类别标签或属性。属性是对象的中间语义表示,通常,区分两个从属类别是关键。
- 给定一个涵盖 C C C对象类别和 A A A属性的数据集,该图具有一个包含 C + A C + A C+A元素的节点集 V V V。
Correlation.
- 类别标签和属性之间的相关性指示此类别是否拥有相应的属性。
- 但是,对于细粒度的任务,它通常仅类别的某些实例具有特定属性。例如,对于特定类别,一个实例可能具有特定属性,而另一实例则没有。因此,这种类别/属性相关性是不确定的。
- 幸运的是,我们可以为属性/对象实例对分配一个分数,该分数表示该实例具有该属性的可能性。然后,我们可以对属于特定类别的所有实例的属性/对象实例对的分数求和,并获得分数来表示该类别具有该属性的置信度。
- 将所有分数线性归一化为[0,1],以获得C×A矩阵S。因此完整的邻接矩阵可以表示为:

其中 O W × H O_{W\times H} OW×H表示大小为 W × H W\times H W×H的零矩阵。通过这种方式,我们可以构造知识图 G = { V , A c } G=\left \{V,A_c\right \} G={ V,Ac}。
3.3 Knowledge Representation Learning
总体流程:
- 构建知识图后,使用GGNN通过图传播节点消息,并为每个节点计算特征向量。
- 将所有特征向量连接起来,以生成知识图的最终表示形式。
具体步骤:
-
用分数 s i s_i si初始化引用类别标签 i i i的节点,该分数表示给定图像中呈现的该类别的置信度,并且节点引用零矢量的每个属性。
-
得分向量 s = { s 0 , s 1 , . . . , s C − 1 } s=\left \{s_{0},s_{1},...,s_{C-1}\right \} s={ s0,s1,...,sC−1}对所有类别的估计都是由预训练的分类器估计的,将在4.1节中详细介绍。因此,每个节点的输入特征可以表示为

其中 O n O_n On是尺寸为 n n n的零向量。如上所述,所有节点的消息在传播过程中相互传播。 -
通过公式1的计算过程, A c A_c Ac用来将消息从某个节点传播到它的邻居,使用矩阵 A c T A_{c}^{T} AcT进行反向消息传播。因此,邻接矩阵为 A = [ A c A c T ] A = \begin{bmatrix} A_{c} & A_{c}^{T} \end{bmatrix} A=[AcAcT]。
-
对于每个节点v,使用 x v x_v xv初始化其隐藏状态,并在时间步 t t t处,使用传播过程(等式1)更新隐藏状态 h v t h_{v}^{t} hvt,表示为:

-
在每次迭代中,每个节点的隐藏状态由其历史状态和其邻居发送的消息确定。这样,每个节点可以聚合来自其邻居的信息,并同时将其消息传递到其邻居。此过程如图3所示。
-
在T迭代之后,每个节点的消息已通过图传播,并且我们可以获得图中所有节点的最终隐藏状态,即 { h 1 T , h 2 T , . . . , h ∣ V ∣ T } \left \{h_{1}^{T},h_{2}^{T},...,h_{|V|}^{T}\right \} { h1T,h2T,...,h∣V∣T}。节点级特征计算由
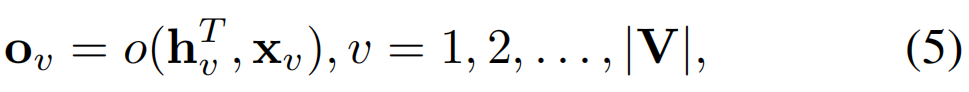
其中 o o o是由完全连接的层实现的输出网络。 -
最后,将这些特征连接起来以产生最终的知识表示 f g f^g fg。
3.4 United Representation Learning
主要任务:
- 介绍嵌入知识表示以增强图像表示学习的门控机制。
Image feature extraction.
应用双线性模型提取图像特征。
具体步骤:
- 给定图像,利用全卷积网络(FCN)提取大小为W0×H0×d的特征图,并使用紧凑的双线性算子生成特征图 f I f^I fI。不执行sum pooling,因此 f I f^I fI的大小为 W ′ × H ′ × d W^{'}\times H^{'}\times d W′×H′×d。
- 为了与现有作品进行公平比较,使用VGG16-Net的卷积层实现FCN,并遵循默认设置,设置c为8192。
- 引入了一种门控机制,该机制可以选择性地允许信息性特征通过,同时在知识的引导下压制非信息性特征,可以将其表达为:

注释:
- f i , j I f_{i,j}^{I} fi,jI是位置(i,j)处的特征向量。
- σ ( g ( f i , j I , f g ) ) \sigma \left ( g\left ( f_{i,j}^{I},f^{g}\right )\right ) σ(g(fi,jI,fg))充当决定哪个位置更重要的门控机制。
- g g g是一个神经网络,将 f i , j I f_{i,j}^{I} fi,jI, f g f^g fg输入串联起来,并输出c维实值向量。它由两个堆叠的完全连接的层实现,其中第一层是10752(8192 + 512×5)至4096,然后是双曲正切函数,而第二层是4096至8192。
- 然后将特征向量 f f f馈入一个简单的全连接层以计算给定图像的得分向量 s s s。
总结:
在细粒度图像分类的背景下,至关重要的是要注意区分区域以捕获不同下属类别之间的细微差别。知识表示对类别-属性相关性进行编码,并且可以捕获区分属性。
(四)Experiments
4.1 Experiment Settings
Datasets.
- 该数据集涵盖了200种鸟类,其中包含5,994张用于训练的图像和5,794张用于测试的图像。
- 除类别标签外,每个图像还带有1个边界框,15个零件关键点和312个属性。
- 数据集极富挑战性,因为相似物种的鸟类可能具有非常相似的视觉外观,而同一物种内的鸟类由于尺度,视点,遮挡和背景的复杂变化而发生剧烈变化。
在两个设置中评估:
- “图像中的鸟”:在训练和测试阶段将整个图像馈入模型;
- “鸟类中的bbox”:边界框上的图像区域在训练和测试阶段输入模型。

图4:Caltech-UCSD鸟类数据集的样本。由于大的类内方差和小的类间方差,对它们进行分类非常困难。
Implementation details.
- 对于GGNN,利用紧凑型双线性模型来产生分数以初始化隐藏状态。
- 为了进行公平的比较,该模型使用VGG16-Net实施,并在Caltech-UCSD鸟类数据集的训练部分进行了训练
- 隐藏状态的维设置为10,输出特征的维设置为5。迭代时间T设置为5。
- KERL框架使用交叉熵损失进行联合训练。
- 框架的所有组件均由SGD进行训练,而GGNN则由ADAM的训练。
4.2 Comparison with State-of-the-Art Methods

表1:KERL框架与Caltech-UCSD鸟类数据集上现有技术水平的比较。 BA和PA分别表示边界框注释和零件注释,HR表示突出显示的区域。√表示在训练或测试过程中使用了相应的注释。
前提:
将KERL框架与16种最先进的方法进行比较,其中一些仅使用图像级标签,另一些还使用边界框/零件批注。因此,为进行公正和直接的比较。在两种设置(即“图像中的鸟”和“ bbox中的鸟”)中对方法进行了评估。
表释:
“ bbox中的鸟”:
- 以前的性能良好的方法是PN- CNN和SPDA-CNN的准确度分别达到85.4%和85.1%,但它们需要对地面真相零件注释进行有力的监督。
- B-CNN的准确性也高达85.1%,但它依赖于非常高维的特征表示(250k维)。
- 相比之下,KERL框架不需要地面实况零件注释,并使用了较低维度的特征表示形式(即8,192个维度),但其准确度达到了86.6%,优于所有以前的最新方法。
“图像中的鸟”:
- 大多数现有方法都明确地搜索区分区域并聚集这些区域的深层特征以进行分类。例如,RA-CNN反复发现三个尺度上的图像区域,并达到85.3%的精度。
- 此外,CVL将每张图像的详细人工注释文本描述与视觉特征相结合,以将准确性进一步提高到85.6%。
- 与它们不同的是,KERL框架学习知识表示,该知识表示对类别-属性相关性进行编码,并将该表示形式用于特征学习。
- 我们的方法可以学习更多与判别属性相关的特性,从而提高性能,即准确度达到86.3%。
- AGAL还采用了部分级属性进行细分类,但在两种设置下其准确度分别为85.5%和85.4%,远低于我们的精度。这些比较很好地证明了KERL框架方法相对于现有算法的有效性。
如第4.4节所述,KERL框架可以学习突出显示与区分属性相关的区域的特征图。因此,论文还汇总了突出显示区域的特征以提高性能。
具体步骤:
- 将跨通道的特征值求和以在每个位置获得一个分数,并绘制一个以每个位置为中心的大小为6×6的区域。
- 采用非最大抑制来排除严重重叠的区域,并选择前三个区域。
- 裁剪图像中三个对应的大小为96×96(原始图像与特征图之间的16x映射)的区域,将其调整为224×224的大小,并馈入VGG16网络以分别提取特征。
- 将这些要素连接起来并馈入一个完全连接的层以计算得分向量,然后将其与KERL的结果进一步平均以得到最终结果。两种设置下的准确度分别提高到86.8%和87.0%。
4.3 Contribution of Knowledge Embedding
KERL框架采用CB-CNN作为基准。CB-CNN在“ bbox中的鸟”和“图像中的鸟”设置中实现了84.6%和85.0%的精度。通过嵌入知识表示,KERL框架将准确度提高到86.6%和86.3%,分别将CB-CNN的准确度提高了2.0%和1.3%。
为了进一步阐明知识嵌入 的特征选择的贡献,我们实现了另外两种基线方法:自我指导的特征学习和特征串联。
Comparison with self-guided feature learning.
验证将知识嵌入到特征学习中的好处:
实验一:删除了GGNN,仅将图像特征馈送到门控神经网络,而其他组件则保持不变。比较结果显示在表2中。它仅比基线CB-CNN表现出较小的改进,因为它不会产生额外的信息,而只会增加模型的复杂性。不出所料,它的性能比我们的差很多。

Comparison with feature concatenation.
实验二:通过简单地将图像和图形特征向量连接在一起,然后再进行完全连接的层进行分类,从而合并了知识。如表2所示,在两种设置下直接结合图像和图形特征可以实现85.4%和85.5%的准确度,这比原始CB-CNN稍好,但仍然有很多缺点。这表明知识整合方法可以更好地利用知识来促进细粒度的图像分类。
4.4 Representation Visualization
在sum pooling之前将特征图可视化,汇总每个位置的通道上的特征值,并将其标准化为[0,1]。在每一行中,展示从特定类别中获取的几个样本的学习到的特征图以及一个子图,该子图显示了该类别与其属性的相关性。相关属性以橙色圆圈突出显示。
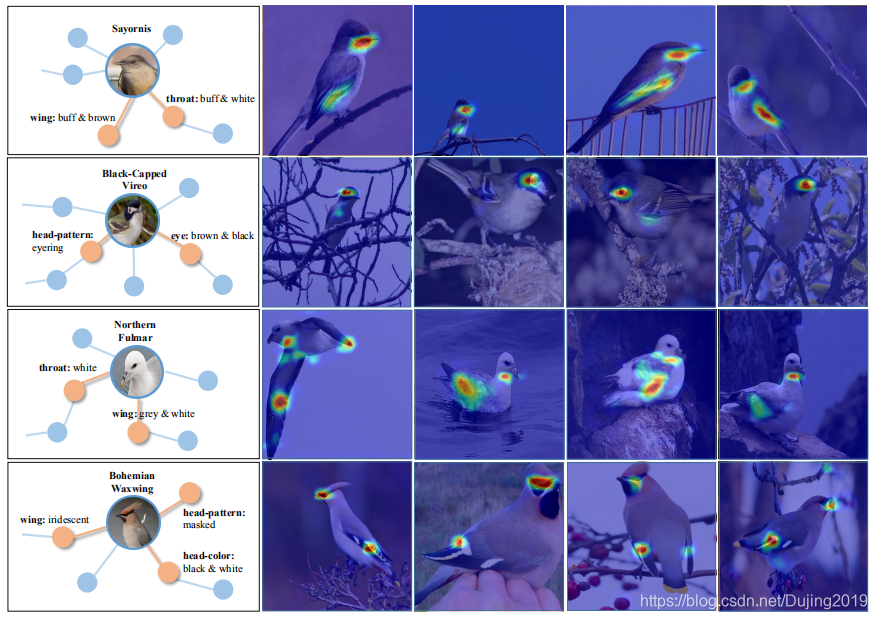
图5:由KERL框架学习的功能图的可视化。
图解:
- 以“ Sayornis”类别为例,KERL框架始终突出显示所有样品的喉咙和翅膀,对应于两个关键属性,即“喉咙:浅黄色和白色”和“翅膀:浅黄色和棕色”(在图5中用橙色圆圈突出显示)。
- 这表明KERL框架可以学习属性感知功能,可以更好地捕获不同下属类别之间的细微差异。同一类别样本的突出显示区域指的是相同的语义部分,并且这些部分与使该类别与其他类别区分开的属性完全一致。
为了清楚地证明正是知识的嵌入带来了这种吸引人的特征。进一步可视化了图6中的CB-CNN模型生成的特征图。与图5中前两个类别相同的样本,用于直接比较。

图6:由基线CB-CNN模型生成的特征图的可视化。
可以观察到,一些突出的区域位于背景中,而有些则散布在鸟类的整个身体上。
(五) Conclusion
- 提出了一种新颖的知识嵌入表示学习(KERL)框架,以将知识图作为图像特征学习的额外指导。
- KERL框架由GGNN组成学习图形表示法,以及将这个表示法集成到图像特征学习中以学习属性感知特征的门控神经网络。
- 框架可以通过具有洞察力的配置来学习特征图,突出显示的区域始终与图中的相关属性相关联,这可以很好地说明KERL框架的性能改进。
- 这是早期尝试嵌入高级知识以改善细粒度图像分类的方法。