爬虫中使用多线程爬虫是一种很常见的方式,可以提高爬取的效率,特别是生产者消费者模型也经常可以见到,今天刚好学习了这种模式,爬取下王者荣耀的高清壁纸,作为练习
import requests
from urllib import parse,request
import os
import threading
from queue import Queue
# 下载高清王者荣耀皮肤壁纸
# 1.拿到王者荣耀高清皮肤的访问的url
url = "https://pvp.qq.com/web201605/wallpaper.shtml"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
}
# res = requests.get(url,headers=headers,verify=False)
# print(res.content.decode("gbk"))
# 2.分析返回的网页源代码发现图片的相关元素链接未在网页的源代码中,那就只能是使用了ajax技术,这个时候,可以点击翻页,查找调用的js请求
# 得到js的请求url和参数:
# url_ajax = "https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1587124601385"
# res = requests.get(url=url_ajax.format(),headers=headers,verify=False)
# 3.得到响应结果,然后把响应结果转换为字典格式,最后获取到字典中的List列表(列表中包含图片的地址信息和英雄名称)
# result = res.json()["List"]
# 直接使用生产者和消费者模式,来爬取王者荣耀的所有英雄高清皮肤
# 生产者拿到从页面队列中拿到页面的url,用来生产图片的url,然后放入图片队列
class Productor(threading.Thread):
def __init__(self,image_queue, page_queue,*args,**kwargs):
super(Productor, self).__init__(*args,**kwargs)
self.image_queue = image_queue
self.page_queue = page_queue
def run(self) -> None:
while not self.page_queue.empty():
page_url = self.page_queue.get(timeout=10)
res = requests.get(page_url,headers=headers,verify=False)
datas = res.json()["List"]
for data in datas:
hero_name = parse.unquote(data["sProdName"]).strip().replace("1:1","")
dirpath = os.path.join("./荣耀皮肤", hero_name)
if not os.path.exists(dirpath):
os.mkdir(dirpath)
image_urls = get_images_urls(data)
for index,image_url in enumerate(image_urls):
image_url = parse.unquote(image_url)
self.image_queue.put({
"image_url":image_url,"dir_path":os.path.join(dirpath,"image_%d.png"%index)})
# 消费图片队列中的url
class Consume(threading.Thread):
def __init__(self, image_queue, *args, **kwargs):
super(Consume, self).__init__(*args, **kwargs)
self.image_queue = image_queue
def run(self) -> None:
# 如果不加True,每个线程执行一次就会退出,因为线程代码已经执行完成了
while True:
try:
image_dict = self.image_queue.get(timeout=10)
image_url = image_dict["image_url"]
dir_path = image_dict["dir_path"]
try:
request.urlretrieve(image_url, dir_path)
except Exception as e:
print("下载失败失败信息为:{},失败url为:{}".format(image_url,image_url))
except:
print("下载结束了")
break
# 获取单个英雄的图片的url
def get_images_urls(data):
images_urls = []
for i in range(1, 9):
# 打印获取到的图片地址信息,发现地址信息都被编码了,此时想到了使用urllib中parse模块解析
image_url = parse.unquote(data["sProdImgNo_%d" %i]).replace("200","0")
images_urls.append(image_url)
return images_urls
def main():
# 生产页面url,放入队列
image_queue = Queue(1000)
page_queue = Queue(18)
for i in range(1,11):
url_ajax = "https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1587124601385".format(i)
page_queue.put(url_ajax)
# 开启两个线程用于生产image_url
for i in range(2):
pro = Productor(image_queue,page_queue)
pro.start()
# 开启五个线程用于消费image_url
for j in range(5):
con = Consume(image_queue)
con.start()
if __name__ == '__main__':
main()
爬取到的结果如下
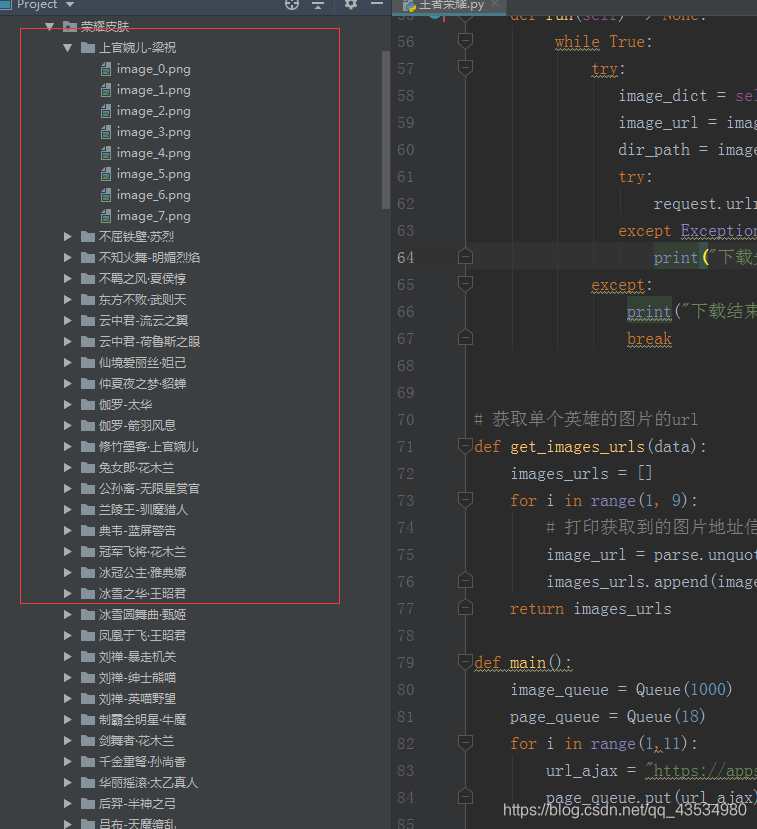

遇到的问题:
1.爬取道德url是已经进行编码的: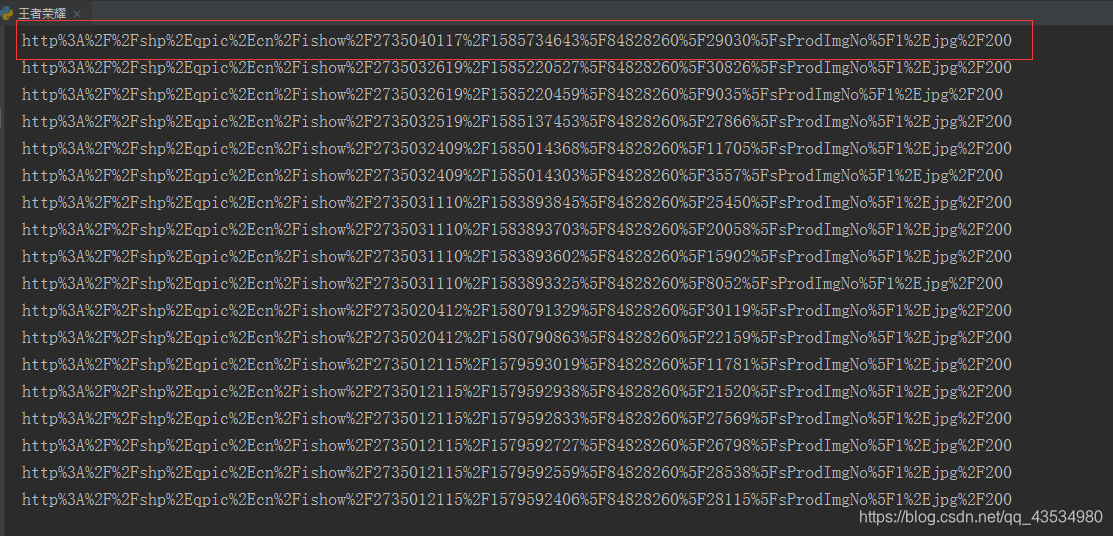
解决方式:打印获取到的图片地址信息,发现地址信息都被编码了,此时想到了使用urllib中parse模块解析image_url = parse.unquote(data[“sProdImgNo_%d” %i])
2.爬的时候报错如下:
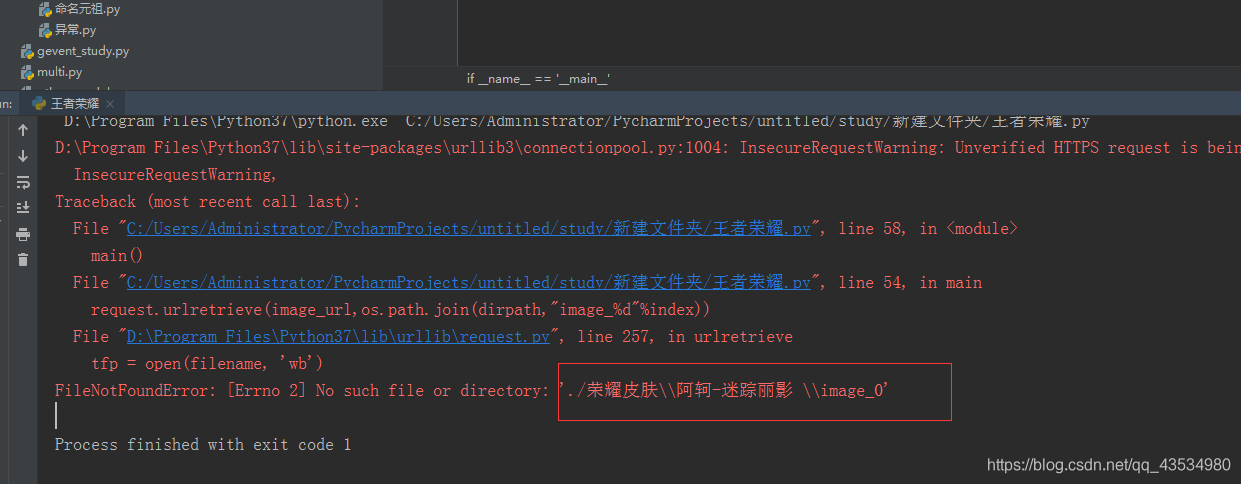
原因分析:在Windows下新建文件夹时,发现不能有一些特殊字符
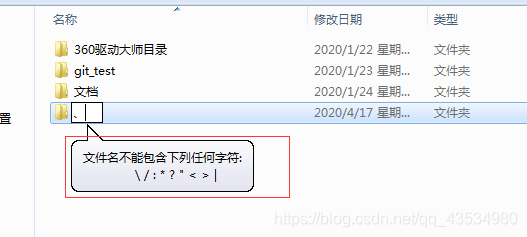
解决方式:使用replace方法进行替换,strip()方法去除前后空格
hero_name = parse.unquote(data[“sProdName”]).strip().replace(“1:1”,"")