NAACL 2019 《An Integrated Approach for Keyphrase Generation via Exploring the Power of Retrieval and Extraction》
本文作者提出了一种用于关键短语生成的多任务混合学习框架,不同于已有的单纯依赖于抽取式或是生成式模型,该框架实现了两种类型模型的混合训练,通过使用抽取出的关键短语来修改生成过程中copy的概率分布,从而使生成式模型可以更好从文档中识别出重要的部分进行复制。
此外为了进一步的提高效果,作者这里还采用检索语料库中和所处理文档相似的文档的方式,进而产生更多精准的关键短语来帮助生成过程。最后作者提出了一种基于神经网络的合并模块,来进一步的处理上述三种方式得到的关键短语,使得最后得到的关键短语质量更高。
传统的抽取式方法根据重要性分数直接从文档中进行短语的抽取,通常效果不错,但是无法得到没有在文档中出现过的短语。而使用了copy机制的生成式方法既可以得到文档中已有的短语,同时还可以生成未曾在所处理文档中出现的短语。但是copy机制可能会导致一个问题,那就是从文中复制的部分太多,导致难以区分结果中短语的相对重要性。
因此作者指出,抽取式得到的重要性分数可以为生成式模型提供指导,使得它知道更应该关注文档中的哪些短语,从而起到一种修正copy概率分布的作用。另外,所处理文档和语料库中相似的文档由于表述的相近性,它们通常都会包含相同或相近的关键短语。因此,如果我们可以从相似文档中检索出相似的短语,那么它们可以作为生成模型解码时的一种辅助信息,帮助decoder生成更精准、更多样化的结果。
本文所提出的框架如下所示
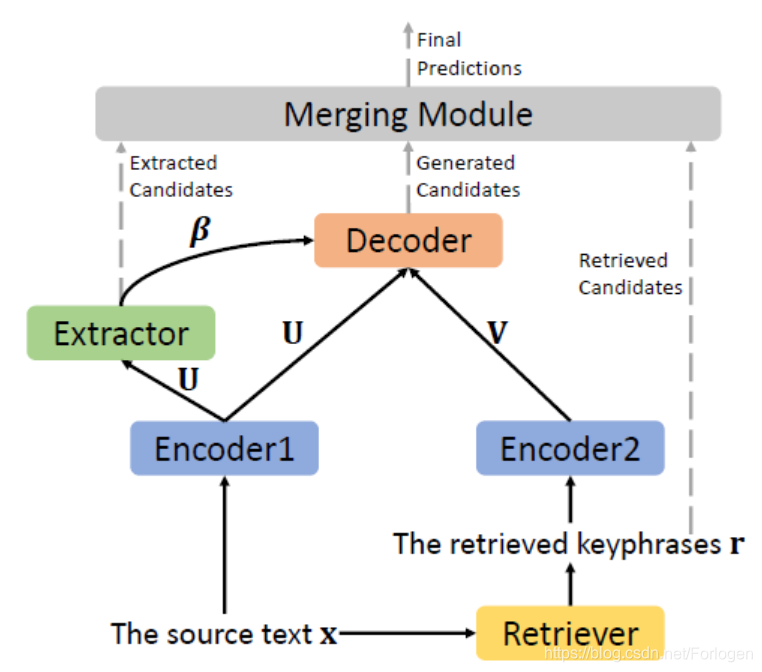
从图中可以看出,整个框架重要包含四个部分:
- Retriever:负责从语料库中的相似文档中检索出相似的候选关键短语
- Extractor:负责为所处理的文档中的短语根据重要性进行打分,抽取出候选关键短语,并将得到的重要性分数用于Generator的Decoder部分
- Generator:负责根据所处理文档的表示来生成新的候选关键短语
- Merging Module:负责归并三个来源得到的关键短语,从而产生最终的预测结果
Retriever
语料库中的数据以<document,keyphrase>的形式存在,Retriever根据Jaccard similarities从中选出TOP-K的文档,然后将它们的keyphrase作为候选关键短语 。Retriever得到的结果一方面作为merging module的一个输入,另一方面将其输入到encoder - 2得到相应的表示 ,然后将其作为 解码时的辅助信息。
Extractor and Generator
这两部分共享Encoder - 1得到的关于 的表示 ,其中Extractor根据 为 中的短语进行打分,得到重要性分数序列 。Generator根据 生成候选关键短语 ,其中 。
-
Encoder:这里使用的Bi-GRU,首先得到单的词 的上下文表示
接着拼接两个方向的表示得到 和 ,最后便可以得到表示 和 。 -
Extractor:这里可以看作是sequence identifier,通过判别文档中的短语的重要性来进行打分,其中重要性分数的计算为:
其中 , 分别代表content、salience和novelty的权重矩阵。 -
Decoder:输入包括 ,这里使用的是GRU+Attention+copy,不同之处在于:这里没有使用之前普遍使用的将internal attention score作为copy的概率,而是使用了rescaled internal attention score来decoder更加关注文档中重要的词。
training
损失项主要包含以下两个:
-
Extraction Loss:这里使用交叉熵,损失函数为
-
Generation Loss:这里使用MLE,损失函数为:
Merging module
最后Merging module根据三个输入的相应分数进行排序得到最终的结果,其中Extractor中候选短语对应的是重要性分数,Generator对应的是decode过程中的注意力分数,Retrieveer对应的是根据Jaccard 相似度计算得到的分数。
为了对输入进行打分,这里引入了一个基于BiGRU的模型来获得输入的表示,然后使用一个辅助的打分器对获得的表示进行打分。打分的依据是将其和真实的关键短语进行比较,判断输入和真实关键短语的接近程度。
整个算法的伪代码如下:

实验
数据集为KP20k、Inspec、Krapivin、NUS、SemEval,评价指标为macro-averaged recall(R)和F-measure( )。
训练模式有四种:
- KG-KE:只联合训练extraction和generation部分
- KG-KR:联合训练generation和retrieve部分
- KG-KE-KR:联合训练extraction、generation和retrieve三部分
- KG-KE-KR-M:联合训练extraction、generation、retrieve和merging四部分
在多个数据集上和基准模型对比的结果如下:
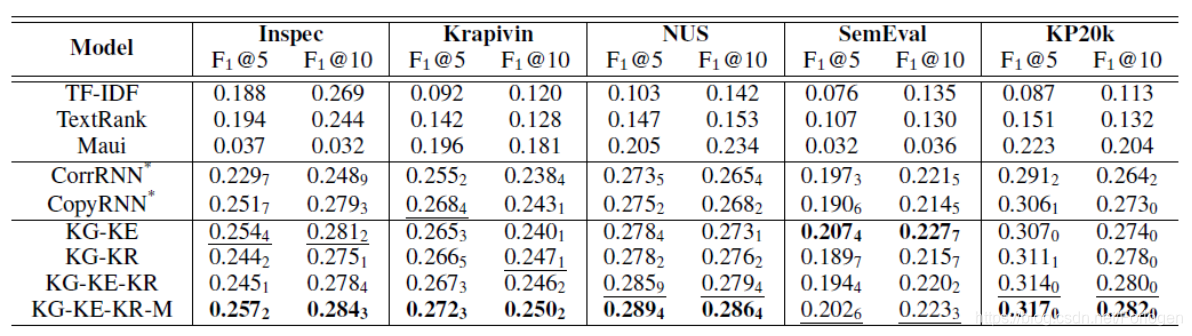
从结果中可以看出新框架的效果优于之前的模型,证明了引入的新模块确实可以起到一定的效果。
在对于absent keyphrase的实验结果中可以看出,新的框架可以更好的生成未在文档中出现的关键短语。
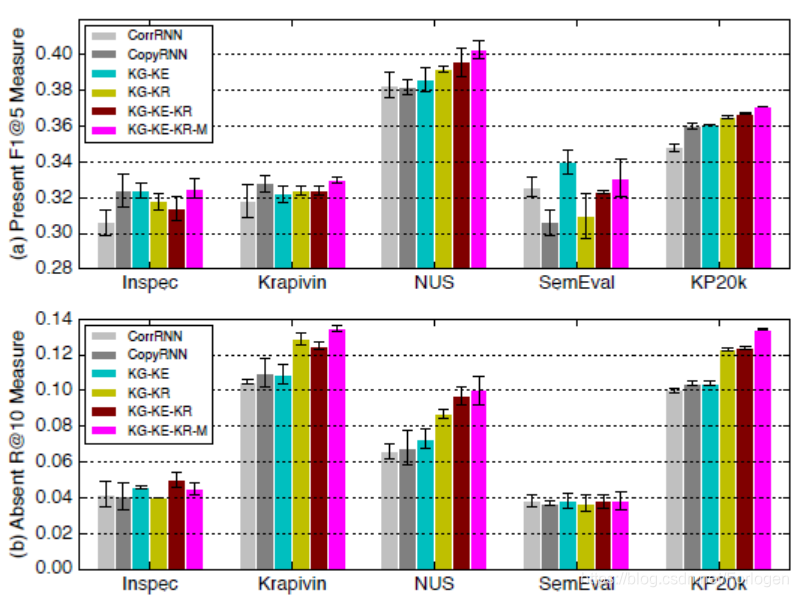
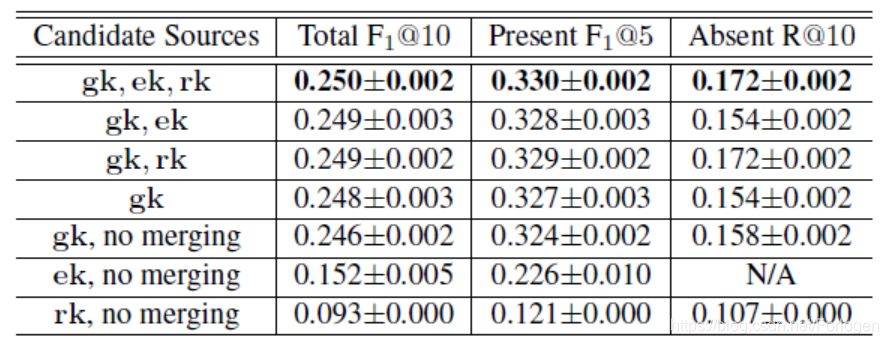
消融实验也证明了每一部分的有效性
最后从结果的可视化中可以看出,新框架生成的关键短语更加精准和多样化。

