- 2022-09
abstract
- motivation:生成高质量的音频,且具有长时相关性。speech2speech
- speech量化成discrete tokens,然后恢复成音频。
intro
- 在没有condition的情况下(linguistic features, MIDI seq),即使强如wavenet,也只能生成噪声。
- 之前的方法:使用自监督语言模型方法预训练的模型得到semantic tokens。这些token捕捉了local dependencies(phn, 音乐中局部的旋律),长时特征(speech中的语言句法信息,钢琴曲中的harmony,rhythm)。——重建质量不高。
- contribution
- SoundStream提取声学特征,保证生成质量;w2v-BERT提取semantic tokens,保证长时一致行建模;
- prompt的存在,可以有很多系的实现,3s unseen speaker prompt,可以实现音色、韵律以及录制环境的复刻;给了piano prompt之后,可以生成旋律、节奏、乐器音色一致的音乐。
- 安全问题:为了防止生成滥用,训练一个很高精度的判别器,用于判别语音是否是audioLM生成的。
related work
-
neutral codec:AudioLM使用SoundStream neutral codec提取的tokens(降采样),作为序列建模的target,而且tokens可以被重建为语音。
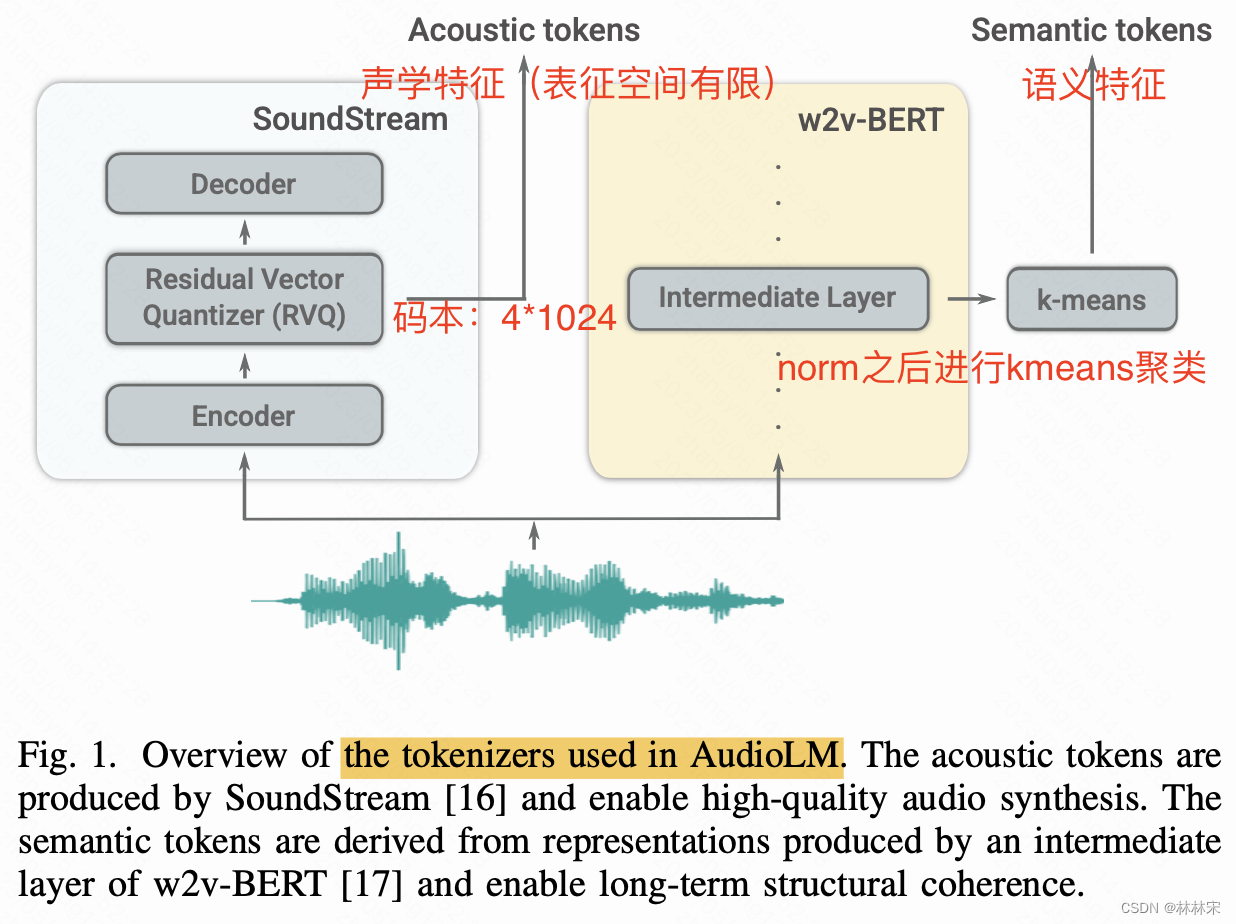
-
SoundStream:多级残差量化器(VQ量化),CNN下采样,输入音频表征为 { 1 , 2 , . . . , N } T a × Q \left \{ 1,2,...,N \right \}^{T_a\times Q} { 1,2,...,N}Ta×Q,其中 T a T_a Ta是下采样后的音频长度,N=1024,Q个量化器,本文使用的预训练Q=4,基于16k音频320倍下采样。soundstream的decoder使用重建损失+对抗损失训练。
-
w2v-BERT:基于masked language modeling loss和对比学习loss训练,使用预训练模型MLM结构的中间层,计算kmeans结果,取embedding在kmeans上映射的质心作为semantic tokens,下采样率640倍。(实验发现,kmeans聚类之前先对w2v-BERT进行norm,更有利于音素信息的表征)。其实和hubert结构提取的特征本质是一样的。
Hierarchical modeling of semantic and acoustic tokens
使用层级结构预测semantic tokens和aoucstic tokens,首先预测整个序列的semantic tokens,然后使用semantic tokens作为条件预测acoustic tokens。主要原因是(1) p ( z t ∣ z < t , y < t ) ~ p ( z t ∣ z < t ) p(z_t|z<t,y<t)~p(z_t|z<t) p(zt∣z<t,y<t)~p(zt∣z<t),给定past semantic tokens,当前的semantic tokens可以和acoustic tokens条件独立。(2)每个阶段的序列长度缩短(因为acoustic tokens的多级预测是横向拼接的,会导致计算长度很长N*Q),减少计算量。

- 第一阶段:预测semanstic tokens
- 第二阶段:预测coarse acoustic tokens(前两级),自回归预测
- 第三阶段:conditioned on coarse acoustic tokens,预测fine acoustic tokens。
- 二三阶段分开,可以减少序列的长度;此外,三阶段独立于二阶段,可以独立于音频长度对三阶段序列进行缩放,并且可以用更多的RVQ预测细节。