背景
对于抽取式摘要生成来说,模型最终的任务是为文档中的句子分配对应的标签,从而来表示某个句子是否会出现在最后的摘要中。因此,抽取式任务本质上可以看做是:
- 句子排序任务:为文档中的句子按照某种重要性度量进行打分,然后降序排列来选择分数较高的句子组成最后的结果
- 序列标注任务:稍不同于句子排序任务,它只关心某个句子是/否会出现在结果中,每个句子对应的标签只有0和1
先前的方法大多依赖于层次化的LSTM来获取句子的表示,然后使用另一层LSTM来预测对应的标签。随着Transformer和预训练模型的出现,事实已经证明了Transformer在特征提取能力方面要强于LSTM。因此,本文采用了层次化的Transformer来实现对句子的打分,最后在抽取式摘要生成任务中取得了较好的效果。
模型
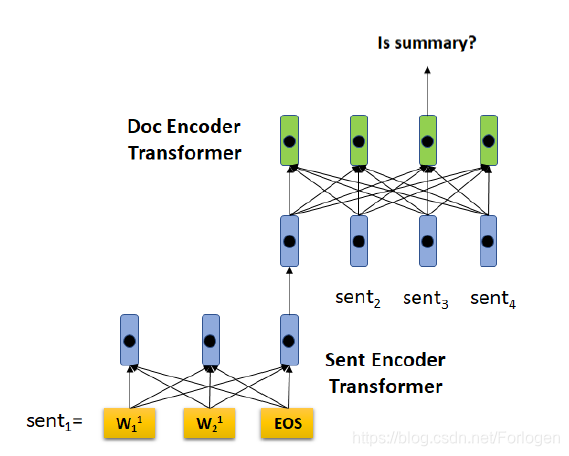
HIBERT的模型架构如下所示:

模型整体上仍然是Seq2Seq架构方式,只不过在Encoder端是一个层次化的方式,首先通过Sent Encoder Transformer获取每个句子的表示,然后通过Doc Encoder Tranformer来进行句子级的MASK预测任务。
假设所处理的文档为 ,其中每个句子 。按照BERT中的处理方式,这里同样在每个句子的末尾添加[EOS],在Sent Encoder Transformer中最后使用[EOS]的表示作为当前句子的表示。
-
Sent Encoder Transformer:它将表示句子的词的序列映射到一个连续的隐空间中,从而获取到句子的初始表示
其中 表示第 个句子中第 个词的嵌入向量, 表示第 个词在句子中的位置向量。经过多层的Transformer后得到[EOS]的表示向量,同时为了充分的利用位置信息,这里同样使用了句子在文档中的位置向量,两者的拼接结果作为下一阶段的输入。
-
Doc Encoder Transformer:经过上一阶段,文档就可以表示为 ,最后可以得到文档级的表示 。
HIBERT这里并不是对BERT本身的fine-tune,而是一种原理类似于BERT的层次表示模型。因此,HIBERT同样采用无监督的方式在大型语料库上进行预训练,预训练模型可以在具体任务的数据集上进行fine-tune,从而更好适配不同的下游任务。
训练
在预训练阶段同样采用了BERT中MASK的训练方式,只不过MASK的层级为句子,其他的部分是一样:
- 随机选择文档中15% 的句子进行mask,然后根据文档中其他的句子表示向量来预测mask的部分
- 80% 使用[MASK]进行填充
- 10% 使用从文档中随机选择的句子进行填充
- 10% 不改变选择的句子
从上面的模型图中可以看出,在预测mask的句子时同样是进行逐词预测,直到遇到[EOS]为止。
预测过程仍然是计算条件概率,即根据mask处理后的文档和当前已预测得到的词来预测下一个输出,直到遇到[EOS]。
当模型预训练结束后,模型接收文档后对文档中的句子进行标注,最后选择标注为1的句子组成最后的摘要,即关键句。
实验部分可见原文。
