1995年,苏联的弗拉基米尔·瓦普尼克(Vladimir N. Vapnik)在Machine Learning上发表了最初的SVM文章。传统的统计模式识别方法只有在样本趋向无穷大时,其性能才有理论的保证。统计学习理论(STL)研究有限样本情况下的机器学习问题。SVM的理论基础就是统计学习理论。
SVM以训练误差作为优化问题的约束条件,以置信范围值最小化作为优化目标,即SVM是一种基于结构风险最小化准则的学习方法,其推广能力明显优于一些传统的学习方法。
1.线性可分支持向量机
给定线性可分训练数据集D,分类学习的最基本想法就是基于训练集D在样本空间中找到一个划分超平面。但是这样的划分超平面可能有很多,所以SVM的任务就是去找到这么一个划分超平面,即对训练样本局部扰动的“容忍性”最好,由此划分超平面所产生的分类结果是最具有鲁棒性的,对未见样本的泛化能力最强。
在样本空间中,划分超平面可以通过如下的线性方程来描述:
wTx+b=0
显然,划分超平面可以被法向量w和位移b确定,我们将其记为(w,b)。那么空间中任意一点到划分超平面的距离可以写为:
r=|wTx+b|||w||
上面这个式子中
||w||
是表示w的范数,所谓范数就是一种计算方式,在欧式(欧几里得)空间
Rn
中,范数定义为:
||w||=w21+w22+...+w2n−−−−−−−−−−−−−−√
所以,有了这层知识,上面距离的表达式换算成三维空间中就是我们学过的最基础的点到平面的距离公式。
假设超平面可以正确分类,即对于每个样本
(xi,yi)
有:
{wTxi+b≥+1,yi=+1wTxi+b≤−1,yi=−1
距离分离超平面最近的样本,他们能使上述的等号成立,因此被称作为“支持向量”(support vector),而两个异类的支持向量到超平面距离之和我们称之为“间隔”(margin)。
γ=2||w||
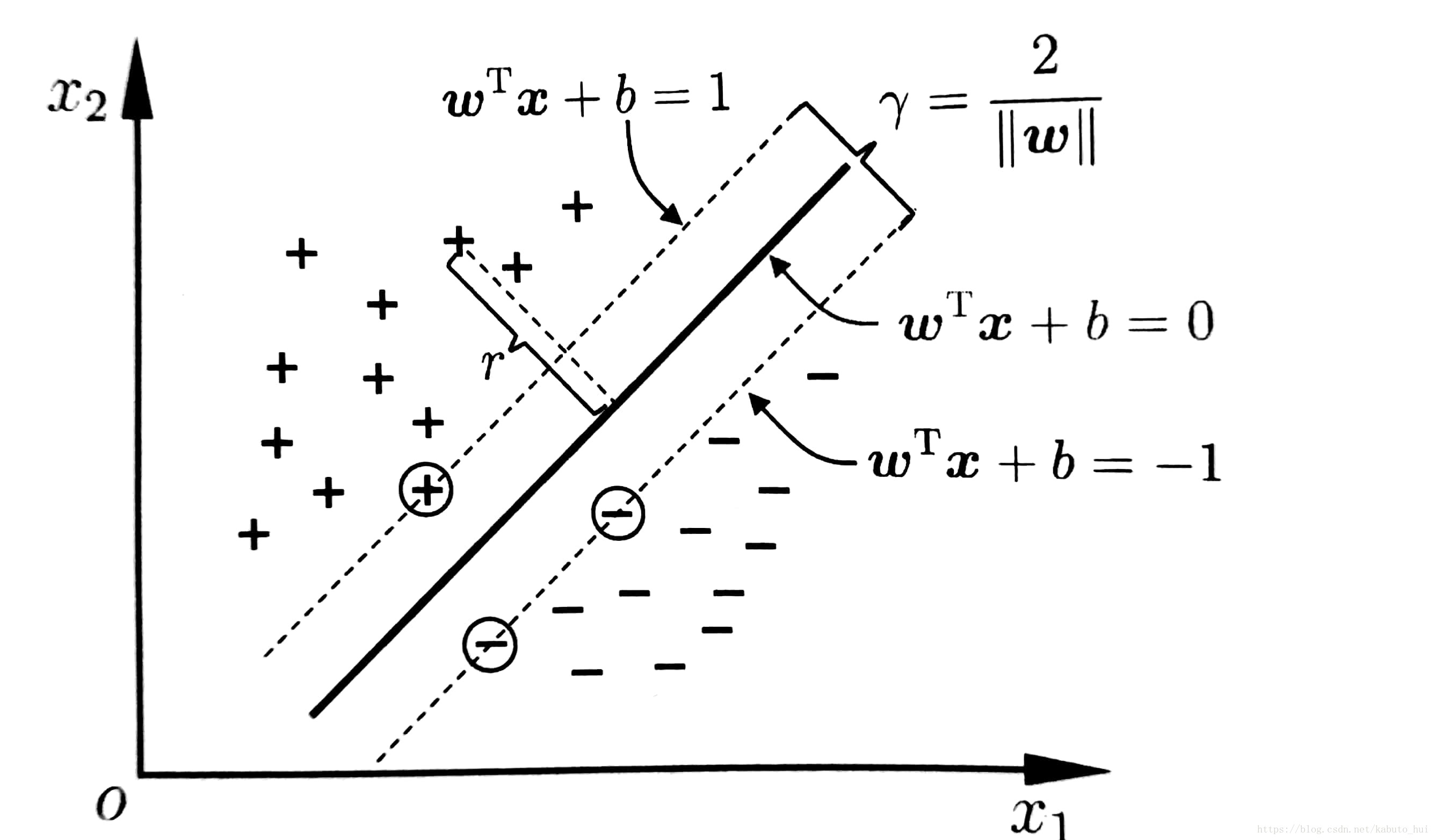
所以问题就可以转化为,找到满足上述约束条件的w与b,使得“间隔”最大。即:
maxw,b2||w||s.t. yi(wTxi+b)≥1, i=1,2,3...,m
于是可以转化为求其等价问题:
minw,b12||w||2s.t. yi(wTxi+b)≥1,i=1,2,3...,m
我们使用拉格朗日乘子法,给每一个约束条件都添加一个拉格朗日乘子
αi≥0
,所以其拉格朗日函数可以写为:
L(w,b,α)=12||w||2+∑i=1mαi(1−yi(wTx+b))
分别让L对w,b求偏导数并使其等于0可以得到:
w=∑i=1mαiyixi0=∑i=1mαiyi
把上述两式带回拉格朗日函数中可以得到最终的一个对偶问题:
minα12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαis.t.∑i=1Nαiyi=0αi≥0,i=1,2,…,N
最后求得最优解
α∗
。
再根据
α∗
可以求出w与b:
w∗=∑i=1mα∗iyixib∗=yj−wTx=yj−∑i=1mα∗iyi(xi⋅xj)
特别说明:
在计算
α
时,我们可以写出其KKT条件如下:
⎧⎩⎨αi≥0yif(xi)−1≥0αi(yif(xi)−1)=0
当
(xi,yi)
不是支持向量的时候,一定有
yif(xi)−1≥0
成立,那么根据第三个条件可以得出
αi=0
。所以这也解释了
支持向量机的最终模型仅与支持向量有关。
2.线性不可分支持向量机
若o若数据线性不可分,则增加松弛因子
ξi≥0
,使函数间隔加上松弛变量大于等于1。这样,约束条件变成:
yi(w⋅xi+b)≥1−ξi
目标函数则变为:
minw,b12∥w∥2+C∑i=1mξi
所以原来的优化问题就变为:
minw,b,ξ12∥w∥2+C∑i=1mξis.t.yi(w⋅xi+b)≥1−ξi,i=1,2,⋯mξi≥0,i=1,2,⋯m
此时,拉格朗日函数为:
L(w,b,ξ,α,μ)≡12∥w∥2+C∑i=1mξi−∑i=1mαi(yi(w⋅xi+b)−1+ξi)−∑i=1mμiξi
对w,b,ξ求偏导:
∂L∂w=0⇒w=∑i=1mαiyixi∂L∂b=0⇒∑i=0mαiyi=0C−αi−μi=0
带入L中得到:
minw,b,ξL(w,b,ξ,α,μ)=−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1Nαi
对上式关于
α
求极大,并求其对偶问题:
minα12∑i=1m∑j=1mαiαjyiyj(xi⋅xj)−∑i=1mαis.t.∑i=1mαiyi=00≤αi≤C,i=1,2,…,m
求得最优解α*,计算w与b:
w∗=∑i=1mα∗iyixib∗=yj−∑i=1mα∗iyi(xi⋅xj)
注意:计算b*时,需要满足0<αj