A、牛牛的DRB迷宫I
简单的数字三角形DP问题
#include <iostream> #include <algorithm> #include <string> #include <string.h> #include <vector> #include <map> #include <stack> #include <set> #include <queue> #include <math.h> #include <cstdio> #include <iomanip> #include <time.h> #define LL long long #define INF 0x3f3f3f3f #define ls nod<<1 #define rs (nod<<1)+1 using namespace std; const int maxn = 2e5 + 10; const LL mod = 1e9 + 7; char mp[55][55]; int n,m; int dp[55][55]; int main() { cin >> n >> m; for (int i = 1;i <= n;i++) { for (int j = 1;j <= m;j++) cin >> mp[i][j]; } dp[1][1] = 1; for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) { if (mp[i][j] == 'R') { dp[i][j + 1] = (dp[i][j + 1] + dp[i][j]) % mod; } else if (mp[i][j] == 'D') { dp[i + 1][j] = (dp[i + 1][j] + dp[i][j]) % mod; } else { dp[i + 1][j] = (dp[i + 1][j] + dp[i][j]) % mod; dp[i][j + 1] = (dp[i][j + 1] + dp[i][j]) % mod; } } } printf("%lld\n", dp[n][m] % mod); return 0; }
B、牛牛的DRB迷宫II
非常有意思的构造题目
我们就构造一个特殊的方阵,它的主对角线上都是B,主对角线下面一条都是R,上面一条都是D,那么假如其他的都是R,此时主对角线上能走到的是不是1 2 4 8
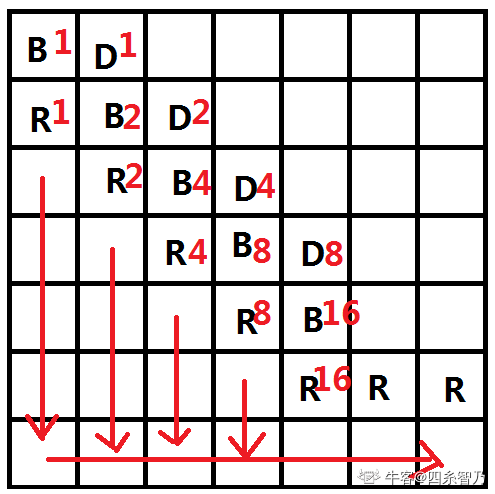
用二进制我们可以拼出所有的数字,所以这种的是肯定是可以构造出答案的。
斜对角线的R对应位置是二进制数,然后只要这一位有的话就可以直接把他变成B。并且让它可以直接走到底部。
最后我只需要统计到达底部的数目之和,也就是进行二进制运算了。非常巧妙
#include <iostream> #include <algorithm> #include <string> #include <string.h> #include <vector> #include <map> #include <stack> #include <set> #include <queue> #include <math.h> #include <cstdio> #include <iomanip> #include <time.h> #define LL long long #define INF 0x3f3f3f3f #define ls nod<<1 #define rs (nod<<1)+1 using namespace std; const int maxn = 2e5 + 10; const LL mod = 1e9 + 7; char s[55][55]; int vis[200]; int main() { LL k; cin >> k; k %= mod; if (k == 0) { cout << "2 2" << endl; cout << "RR" << endl; cout << "RR" << endl; } int cnt = 0; while (k) { cnt++; if (k & 1) vis[cnt] = 1; k >>= 1; } for (int i = 1;i <= cnt;i++) s[i][i] = 'B'; for (int i = 1;i <= cnt-1;i++) { s[i][i+1] = 'D'; s[i+1][i] = 'R'; } cnt++; for (int i = 1;i <= cnt;i++) { if (vis[i]) { s[i+1][i] = 'B'; for (int j = i+2;j <= cnt;j++) s[j][i] = 'D'; for (int j = 1;j <= cnt;j++) s[cnt][j] = 'R'; } } cout << cnt << " " << cnt << endl; for (int i = 1;i <= cnt;i++) { for (int j = 1;j <= cnt;j++) { if (s[i][j] == 0) s[i][j] = 'R'; cout << s[i][j]; } cout << endl; } return 0; }
F、牛牛的Link Power I
就
我们发现每个“1”对于它本身位置产生的影响贡献为0,而往后面依次产生了0,1,2,3,4,5...的贡献。
那当然,这个东西特殊,不用这么一般性的技巧。
对于每个位置的1",假设它的位置为pos,那么直接对a[pos+1]加上1的贡献。(相等于维护一个二次方差)
全部做完以后,做两次前缀和操作,对于每个位置的“1”直接查询数组中的值加起来即可。
#include <iostream> #include <algorithm> #include <string> #include <string.h> #include <vector> #include <map> #include <stack> #include <set> #include <queue> #include <math.h> #include <cstdio> #include <iomanip> #include <time.h> #define LL long long #define INF 0x3f3f3f3f #define ls nod<<1 #define rs (nod<<1)+1 using namespace std; const int maxn = 1e5 + 10; const LL mod = 1e9 + 7; char s[maxn]; int n; LL sum[maxn],ans; void pre_sum() { for (int i = 1;i <= n;i++) { sum[i] += sum[i-1]; if (sum[i] >= mod) sum[i] -= mod; } } int main() { scanf("%d",&n); scanf("%s",s+1); for (int i = 1;i <= n;i++) { if (s[i] == '1') sum[i+1]++; } pre_sum(); pre_sum(); for (int i = 1;i <= n;i++) { if (s[i] == '1') { ans += sum[i]; if (ans >= mod) ans -= mod; } } printf("%lld\n",ans); return 0; }
G、牛牛的Link Power II
对于每一个 ‘1’ 的位置,我们考虑它对前面的贡献和它对后面的贡献
由于要维护的是“前缀和的前缀和”所以可以升一阶,直接维护前缀和,这样单点修改就变成了区间修改,然后区间查询即可。
#include <iostream> #include <algorithm> #include <string> #include <string.h> #include <vector> #include <map> #include <stack> #include <set> #include <queue> #include <math.h> #include <cstdio> #include <iomanip> #include <time.h> #define LL long long #define INF 0x3f3f3f3f #define ls nod<<1 #define rs (nod<<1)+1 using namespace std; const int maxn = 1e5 + 10; const LL mod = 1e9 + 7; char s[maxn]; struct segment_tree { LL val; LL lazy; }; struct Segment { segment_tree tree[maxn*4]; void build(int l, int r, int nod) { if (l == r) { tree[nod].lazy = 0; tree[nod].val = 0; return; } int mid = (l + r) >> 1; build(l, mid, ls); build(mid + 1, r, rs); tree[nod].val = tree[ls].val + tree[rs].val; } void pushdown(int l, int r, int nod) { if (tree[nod].lazy) { int mid = (l + r) >> 1; tree[ls].lazy += tree[nod].lazy; tree[rs].lazy += tree[nod].lazy; tree[ls].val += (mid - l + 1) * tree[nod].lazy; tree[rs].val += (r - mid) * tree[nod].lazy; tree[nod].lazy = 0; } } void modify(int l, int r, int ql, int qr, int v, int nod) { if (ql <= l && qr >= r) { tree[nod].lazy += v; tree[nod].val += (r - l + 1) * v; return; } pushdown(l, r, nod); int mid = (l + r) >> 1; if (ql <= mid) modify(l,mid,ql,qr,v,ls); if (qr > mid) modify(mid+1,r,ql,qr,v,rs); tree[nod].val = tree[ls].val + tree[rs].val; } LL query(int l, int r, int ql, int qr, int nod) { if (ql <= l && qr >= r) return tree[nod].val; pushdown(l,r,nod); int mid = (l + r) >> 1; LL cnt = 0; if (ql <= mid) cnt += query(l,mid,ql,qr,ls); if (qr > mid) cnt += query(mid+1,r,ql,qr,rs); return cnt; } }suf,pre; int main() { int n,m; scanf("%d",&n); scanf("%s",s+1); LL ans = 0; pre.build(1,n,1); suf.build(1,n,1); for (int i = 1;i <= n;i++) { if (s[i] == '1') { ans = (ans + pre.query(1,n,1,i,1) + suf.query(1,n,i,n,1)) % mod; if (i!= n) pre.modify(1,n,i+1,n,1,1); // 前面对后面的贡献 if (i!= 1) suf.modify(1,n,1,i-1,1,1); // 后面对前面对贡献 } } printf("%lld\n",ans); scanf("%d",&m); while (m--) { int opt,x; scanf("%d%d",&opt,&x); LL pres = pre.query(1,n,1,x,1); //前面对x的贡献 LL sufs = suf.query(1,n,x,n,1); // 后面对x的贡献 if (opt == 1) { ans = (ans + pres + sufs) % mod; if (x+1 <= n) pre.modify(1,n,x+1,n,1,1); // if (x-1 >= 1) suf.modify(1,n,1,x-1,1,1); } else { ans = ((ans - pres - sufs) % mod + mod ) % mod; if (x+1 <= n) pre.modify(1,n,x+1,n,-1,1); if (x-1 >= 1) suf.modify(1,n,1,x-1,-1,1); } printf("%lld\n",ans); } return 0; }
H、牛牛的k合因子数
x 的所有因数 - x的所有质因数 - 1 (因数是1) 那么剩下的是因数是合数的个数了
处理质因数可以用线性筛,处理所有的因数可以用 欧拉函数的变形
#include <iostream> #include <algorithm> #include <string> #include <string.h> #include <vector> #include <map> #include <stack> #include <set> #include <queue> #include <math.h> #include <cstdio> #include <iomanip> #include <time.h> #define LL long long #define INF 0x3f3f3f3f #define ls nod<<1 #define rs (nod<<1)+1 using namespace std; const int maxn = 2e5 + 10; const LL mod = 1e9 + 7; int cnt[maxn]; int visit[maxn]; int n, m; int cntn[maxn]; int ans[maxn]; int Getn(int x){ int ret = 1; for(LL i = 2; i * i <= x; i++){ if(x % i == 0){ LL a = 0; while(x % i == 0){ x /= i; a++; } ret = ret * (a + 1); } } if(x > 1){ ret *= 2; } return ret; } void Prime(){ memset(visit, 0, sizeof(visit)); for(int i = 2; i <= n; i++){ if (!visit[i]) { for(int j = 2 * i; j <= n; j += i){ visit[j] = 1; cnt[j]++; } } } } int main() { scanf("%d %d", &n, &m); memset(cnt, 0, sizeof(cnt)); memset(ans, 0, sizeof(ans)); for(int i = 1; i <= n; i++){ cntn[i] = Getn(i); } Prime(); for(int i = 1; i <= n; i++){ if(cntn[i] > 2){ cnt[i] = cntn[i] - cnt[i] - 1; } } for(int i = 1; i <= n; i++){ ans[cnt[i]]++; } while(m--){ int k; scanf("%d", &k); printf("%d\n", ans[k]); } return 0; }
I、牛牛的汉诺塔
因为n的范围变大了,所以无法再跟原来一样采用递归求解
正解是记忆化搜索,但是也可以打表找规律来做
记忆化搜索代码:
#include <iostream> #include <algorithm> #include <string> #include <string.h> #include <vector> #include <map> #include <stack> #include <set> #include <queue> #include <math.h> #include <cstdio> #include <iomanip> #include <time.h> #define LL long long #define INF 0x3f3f3f3f #define ls nod<<1 #define rs (nod<<1)+1 using namespace std; const int maxn = 1e5 + 10; const LL mod = 1e9 + 7; struct node { LL data[6]; node() { memset(data,0, sizeof(data)); } }; node operator + (node a,node b) { node c; for (int i = 0;i < 6;i++) { c.data[i] = a.data[i] + b.data[i]; } return c; } void mov(int x,int y,node &temp) { if(x==0&&y==1)++temp.data[0]; if(x==0&&y==2)++temp.data[1]; if(x==1&&y==0)++temp.data[2]; if(x==1&&y==2)++temp.data[3]; if(x==2&&y==0)++temp.data[4]; if(x==2&&y==1)++temp.data[5]; } node dp[3][3][3][105]; bool vis[3][3][3][105]; node hanoi(int a,int b,int c,int n) { if (vis[a][b][c][n]) return dp[a][b][c][n]; if (n == 1) { mov(a,c,dp[a][b][c][n]); vis[a][b][c][n] = true; return dp[a][b][c][n]; } node temp; temp = temp + hanoi(a,c,b,n-1); mov(a,c,temp); temp = temp + hanoi(b,a,c,n-1); vis[a][b][c][n] = true; return dp[a][b][c][n] = temp; } int main() { int n; scanf("%d",&n); node ans = hanoi(0,1,2,n); printf("A->B:%lld\n",ans.data[0]); printf("A->C:%lld\n",ans.data[1]); printf("B->A:%lld\n",ans.data[2]); printf("B->C:%lld\n",ans.data[3]); printf("C->A:%lld\n",ans.data[4]); printf("C->B:%lld\n",ans.data[5]); printf("SUM:%lld\n",(1LL<<n)-1); return 0; }
J、牛牛的宝可梦Go
首先我们用 floyd 求出各个点之间的最短距离,然后我们对宝可梦出现的时间进行排序
dp[i] 代表 到达 i 点获得的最大战斗力
因为之前对宝可梦出现对时间已经进行了排序,所以很容易想到去枚举之前的点(因为肯定是从时间小的转移到时间大的)

但是很可惜 k 的范围是 1e5 ,所以这种O(k^2) 的算法是超时了的
那么我们如何去优化呢?
由于地图的大小只有200,所以200步以后可以转移到任意位置
我们不妨改成枚举步长 这样复杂度就可以降为O(200*k)
#include <iostream> #include <algorithm> #include <string> #include <string.h> #include <vector> #include <map> #include <stack> #include <set> #include <queue> #include <math.h> #include <cstdio> #include <iomanip> #include <time.h> #define LL long long #define INF 0x3f3f3f3f #define ls nod<<1 #define rs (nod<<1)+1 using namespace std; const int maxn = 1e5 + 10; const LL mod = 1e9 + 7; struct Node { LL t,p,w; }a[maxn]; bool cmp(Node a, Node b ){ return a.t<b.t; } LL dp[maxn]; LL dis[210][210]; int main() { int n,m; scanf("%d%d",&n,&m); memset(dis,INF, sizeof(dis)); for (int i = 1;i <= n;i++) dis[i][i] = 0; for (int i = 1;i <= m;i++) { int u,v; scanf("%d%d",&u,&v); dis[u][v] = dis[v][u] = 1; } LL k; scanf("%lld",&k); for (int i = 1;i <= k;i++) { scanf("%lld%lld%lld",&a[i].t,&a[i].p,&a[i].w); } sort(a+1,a+1+k,cmp); a[0].t = 0,a[0].p = 1,a[0].w = 0; for (int l = 1;l <= n;l++) { for (int i = 1;i <= n;i++) { for (int j = 1;j <= n;j++) dis[i][j] = min(dis[i][j],dis[i][l]+dis[l][j]); } } LL ans = 0; for (int i = 1;i <= k;i++) dp[i] = -INF; for (int i = 1;i <= k;i++) { for (int j = 1;j <= 200 && j <= i;j++) { if (a[i].t-a[i-j].t >= dis[a[i].p][a[i-j].p] ) { dp[i]=max(dp[i],dp[i-j]+a[i].w); } ans = max(ans,dp[i]); } } printf("%lld\n",ans); return 0; }