上一章:深度篇——神经网络(二) ANN与DNN 和常用激活函数
下一章:深度篇——神经网络(四) 细说 调优神经网络
本小节,细说 网络拓扑与训练神经网络,下一小节细说 调优神经网络
二. ANN 与 DNN
3. 网络拓扑
(1). 单层网络

(2). 多层网络

多层网络至少有 1 个 hidden 层,也可以有多个 hidden 层。有 bias 值,可以让函数不必一定要经过原点。
(3). 无论是 ANN,还是 DNN,网络连接都是全连接。
output 层的激活函数与 hidden 层的激活函数可以相同,也可以不同,根据需求而定。output 层可以是单值输出,也可以是多值输出。
4. 训练神经网络
(1). 训练神经网络的两个阶段
①. 前向阶段
前向阶段即正向传播
正向传播根据数据集和激活函数,当前的 值,计算出 loss 损失函数
②. 后向阶段
后向阶段即反向传播
反向传播利用链式法则对 进行求导,代入数据集的值,求出梯度
③. 链式法则
若函数 在点
上可导,
则
④. 栗子
a. 栗一
有 ,且
。
解:令 ,则
正向传播:
反向传播:
图解:

b. 栗二 Sigmoid 函数
有
且
解:令
正向传播
反向传播
图解:

图解这里,没有 出现,是因为,
,对
的乘积和导数都没影响,所以,可以人为的忽略它。但是,它实际上,是存在的。
(2). 梯度下降法
根据反向传播求得的梯度 ,对
进行更新操作:
:为
时刻的 权重值
:为
时刻的权重值
:为学习率
:为
时刻的梯度
(3). 神经网络的具体流程
输入:训练集数据
输出:一组最优解
①. 随机一组 (这里的
是指 0 时刻
的值,和上面栗二 的
不同)
②. 根据当前 进行正向传播,求取
的损失函数
输出(保存)
反向传播求出梯度 ,更新
③. 反复迭代 ②,直到输出最优解
(4). 总结
训练神经网络其实和单层的梯度下降法的思想是一样的:
都是先初始化一组
利用当前的 进行正向传播求出
再根据梯度下降法求出梯度
对 进行更新操作
反复迭代,直至
输出一组最优解
只是,单层的梯度下降的导数关系相对简单点,容易求出梯度值 ;而神经网络的导数关系复杂,对于链式法则更依赖。用一句话总结神经网络的训练:正向求损失,反向求梯度,往复迭代,求出最优解
学到这里,已经掌握了ANN 和 DNN 的大体框架了,可以开始训练了。但是,训练是可以训练,可是,也许很难得到较好的 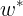 ,为了得到这个较好的 ,我们还需要对神经网络进行调优。这,也是我接下来为大家分析讲解的,有需要或有兴趣的,请点击下一小节观看。
,为了得到这个较好的 ,我们还需要对神经网络进行调优。这,也是我接下来为大家分析讲解的,有需要或有兴趣的,请点击下一小节观看。

上一章:深度篇——神经网络(二) ANN与DNN 和常用激活函数
下一章:深度篇——神经网络(四) 细说 调优神经网络
