谨防训练数据和实际问题不匹配
在谈论改善模型之前,首先一点是要考虑数据问题。
在深度学习过程中,很容易出现的一点是,我们训练的数据和实际问题并不匹配。这很糟糕,会导致训练模型效果很好,但实际应用很糟糕的现象。比如说对于下图而言,我们想要识别视频中的具体车辆是什么型号的车辆。右侧是训练数据。训练数据的汽车都是侧面照相的结果,而实际检测的汽车都是正面和后面的。训练的模型在实际应用过程中就会很糟糕。

在数据OK的情况下,我们按照吴恩达老师的建议来改善模型。

如果训练误差过高
如果误差过高,我们首先可以考虑把我们现有的神经网络深度加深,以及添加更多的神经元,或许能够改善学习效果。我们也可以考虑迭代更多的epoch,我们也可以对学习率做出调整,往往更小的学习率能有更好的效果。如果这些策略都不行,那我们可能需要考虑换一个深度学习方法了。
如果验证集误差较高
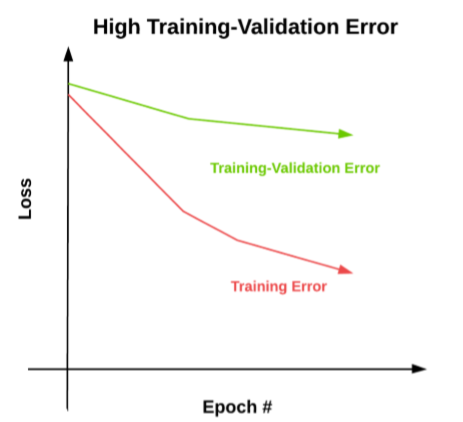
如果验证集误差比较高,我们可以考虑多增加一些正则化项。L2正则化,Dropout等等。我们是否使用了数据增强?通常使用数据增强可以一定程度改善学习效果,增加泛化能力。
也有可能是你的模型训练数据不够,没能够学习到潜在的模式,导致出现了比较严重的过拟合现象。如果可以的话,采集更多的数据,增加训练数据永远都不会是一件糟糕的事情。如果上面的策略都不行,那么可能只剩一条路可以走了:换一个网络模型。
如果测试集误差较高
当这个情况发生的时候,很有可能是训练集和验证集发生了过拟合。我们可能需要给验证集更多的数据,来测试发现什么时候发生了过拟合现象。
