深度神经网络--预训练模型
NLP综述:NLP综述(思维导图)
一个画图的工具:https://app.diagrams.net/
参考博客:深度学习中的注意力机制
参考博客:深度学习枕边书
question
反向传播时需采用蒙特卡洛进行梯度估计
Transformer
Encoder-Decoder框架
文本领域常用的Encoder-Decoder框架
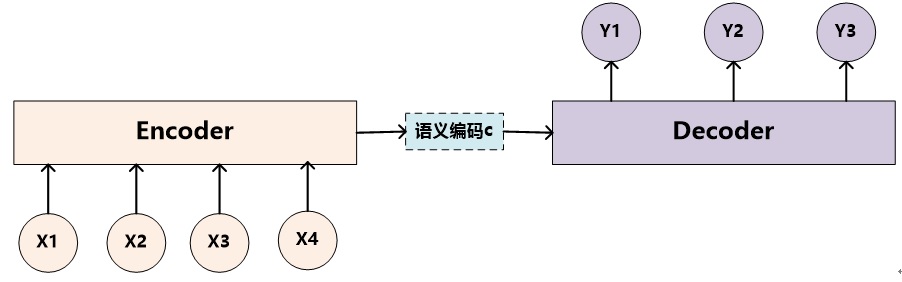
增加了注意力模型的Encoder-Decoder光加

注意力机制函数结果

代表输入句子Source的长度,
代表在Target输出第i个单词时Source输入句子中第j个单词的注意力分配系数,
则是Source输入句子中第j个单词的语义编码。
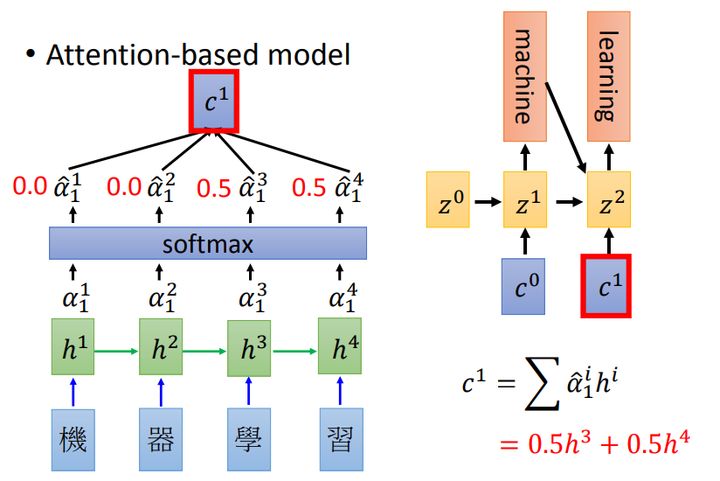
注意力分配概率分布值通用计算过程

对于采用RNN的Decoder来说,在时刻i,如果要生成单词,我们是可以知道Target在生成
之前的时刻i-1时,隐层节点i-1时刻的输出值
的,而我们的目的是要计算生成
时输入句子中的单词“Tom”、“Chase”、“Jerry”对
来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态
去一一和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(
,
)来获得目标单词
和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
一般在自然语言处理应用里会把Attention模型看作是输出Target句子中某个单词和输入Source句子每个单词的对齐模型,这是非常有道理的。
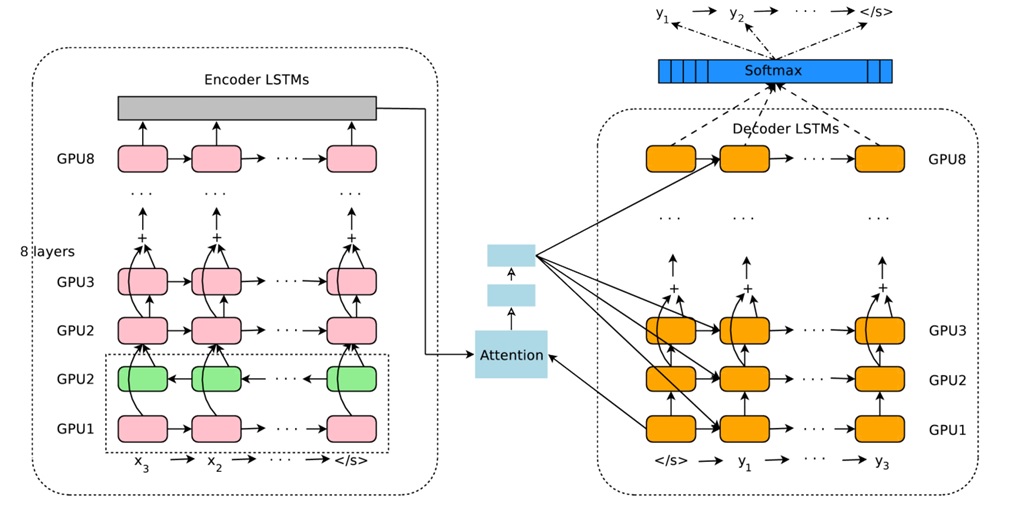
上图为Google于2016年部署到线上的基于神经网络的机器翻译系统,相对传统模型翻译效果有大幅提升,翻译错误率降低了60%,其架构就是上文所述的加上Attention机制的Encoder-Decoder框架,主要区别无非是其Encoder和Decoder使用了8层叠加的LSTM模型。
Attention
Attention的思想如同它的名字一样,就是“注意力”,在预测结果时把注意力放在不同的特征上。(Source -> Target)

目前在NLP研究中,key和value常常都是同一个,即 key=value
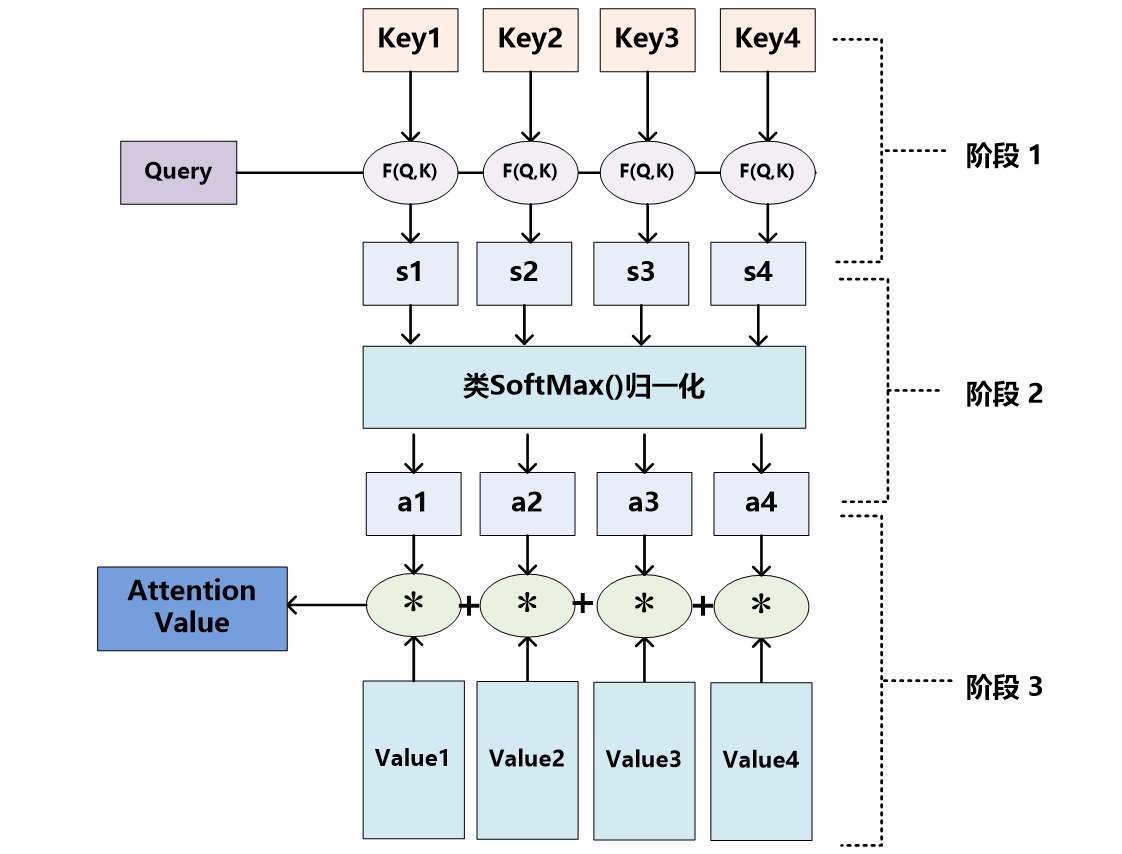
可以这样看待Attention机制:将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理.
在计算Q和K的相似性或者相关性时, 最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络MLP来求值,即如下方式:

Self Attention模型
如果是Self Attention机制,一个很自然的问题是:通过Self Attention到底学到了哪些规律或者抽取出了哪些特征呢?或者说引入Self Attention有什么增益或者好处呢?我们仍然以机器翻译中的Self Attention来说明,下图可视化地表示Self Attention在同一个英语句子内单词间产生的联系。
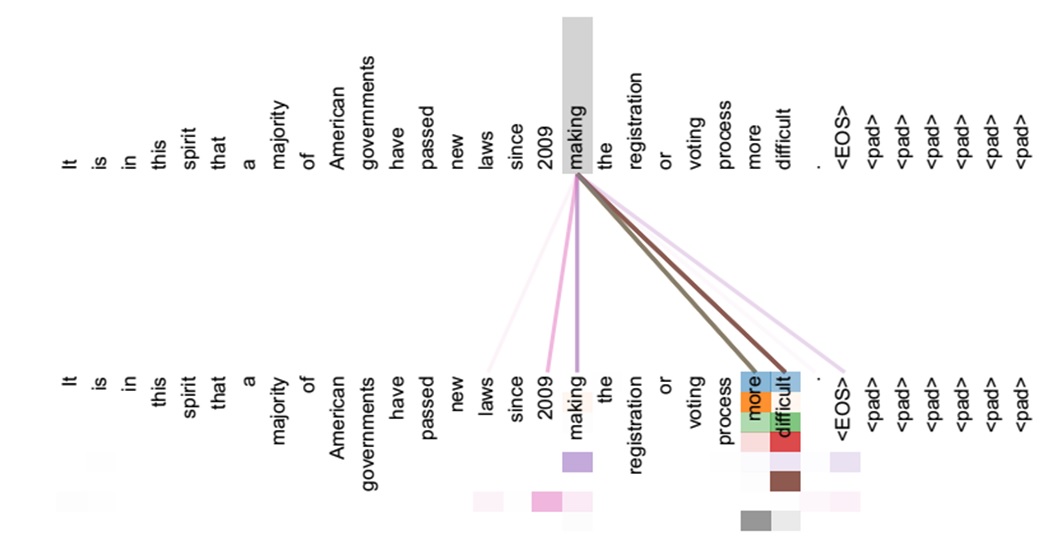
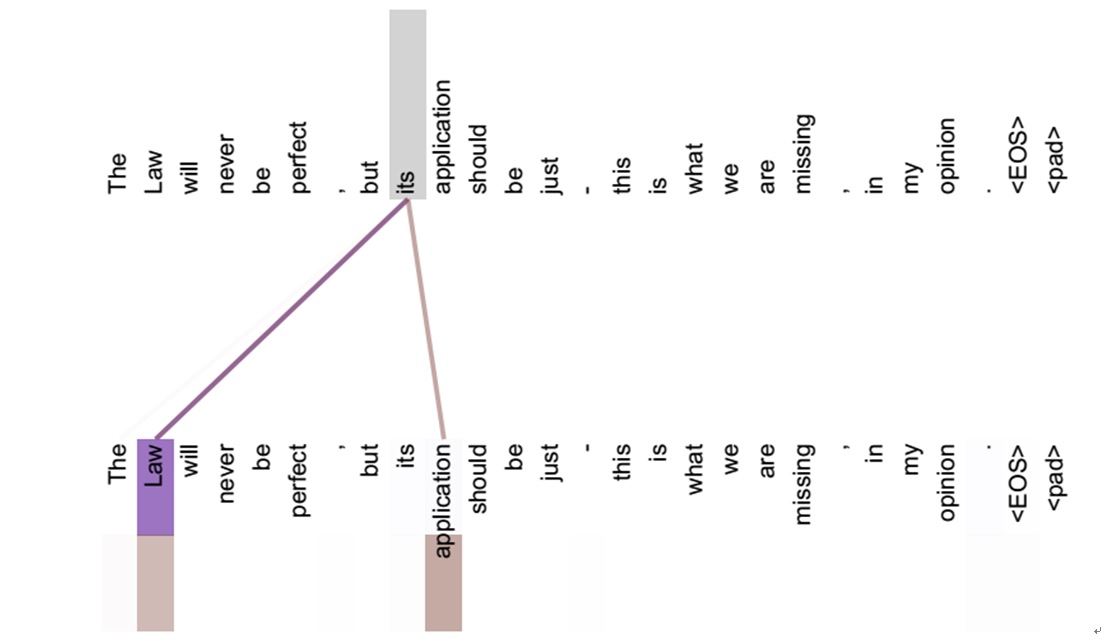
Self Attention可以捕获同一个句子中单词之间的一些句法特征(比如左图展示的有一定距离的短语结构)或者语义特征(比如右图展示的its的指代对象Law)。很明显,引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self Attention对于增加计算的并行性也有直接帮助作用。这是为何Self Attention逐渐被广泛使用的主要原因。Encoder-Decoder加Attention架构由于其卓越的实际效果,目前在深度学习领域里得到了广泛的使用,了解并熟练使用这一架构对于解决实际问题会有极大帮助。
Multi-head Attention
多头attention(Multi-head attention)结构如下图,Query,Key,Value首先进过一个线性变换,然后输入到放缩点积attention,注意这里要做h次,其实也就是所谓的多头,每一次算一个头。而且每次Q,K,V进行线性变换的参数W是不一样的。然后将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。可以看到,google提出来的多头attention的不同之处在于进行了h次计算而不仅仅算一次,论文中说到这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息,后面还会根据attention可视化来验证。

对于self attention中的q, v, k来自于embedding, 但不是embedding, 而是分别接了三个dense层得到了q, v, k。多头注意力机制中的QW, KW, VW矩阵是映射层, 通过使用三个映射层, 多头注意力机制中的三个映射层矩阵不同, 对模型的本身的特征抽取的多样性具有一定的帮助。 因为在每个Attention中,采用不同的Query / Key / Value权重矩阵,每个矩阵都是随机初始化生成的。然后通过训练,将词嵌入投影到不同的“representation subspaces(表示子空间)”中。
Attention分类
RNN-based model
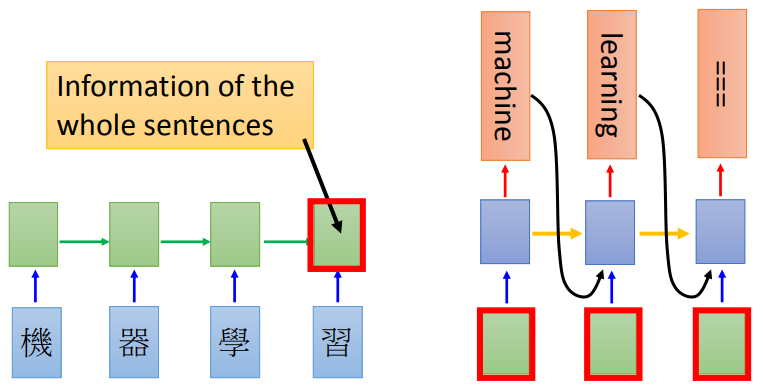
soft attention(attention与rnn结合的model)

其中 是编码器每个step的输出,
是解码器每个step的输出.
Attention分类
soft attention:传统attention,可被嵌入到模型中去进行训练并传播梯度
hard attention:不计算所有输出,依据概率对encoder的输出采样,在反向传播时需采用蒙特卡洛进行梯度估计
global attention:传统attention,对所有encoder输出进行计算
local attention:介于soft和hard之间,会预测一个位置并选取一个窗口进行计算
self attention:传统attention是计算Q和K之间的依赖关系,而self attention则分别计算Q和K自身的依赖关系。