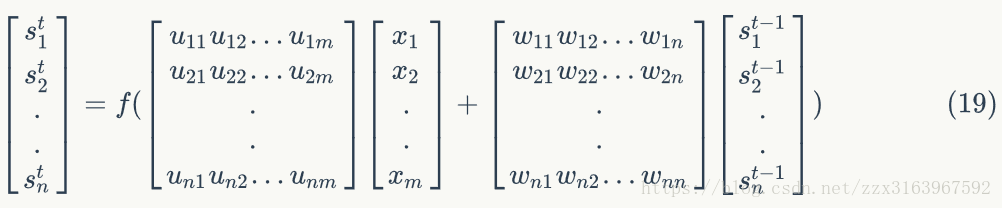为了更好的学习神经网络,建议学习零基础入门深度学习https://www.zybuluo.com/hanbingtao/note/448086
以下为我自己学习后为方便记忆的总结,可能从在一些偏差。
神经网络的训练:
bp算法是神经网络训练算法的基础,bptt算法也主要是来源于bp算法。
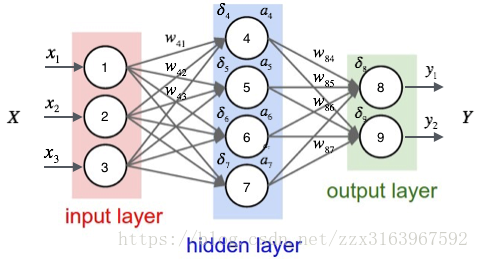
以下是全连接的网络。
在神经网络全连接的方式中,这是一个较为简单的网络,也是基础的网络
他的计算方式如下的(3)(4)。
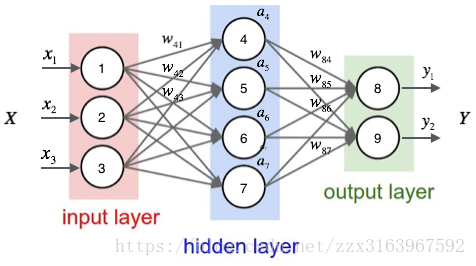

这里主要是要记住全连接神经网络在激活函数之前的运算为+(加和运算)。将各链接的加和运算输入激活函数输出各自神经的输出。

(5)(6)两式是输出层的计算方式

a4,a5,a6,a7,隐含层的计算方式
对于bp算法,下图是很重要的,主要是方便理解每一个神经元的误差项(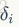
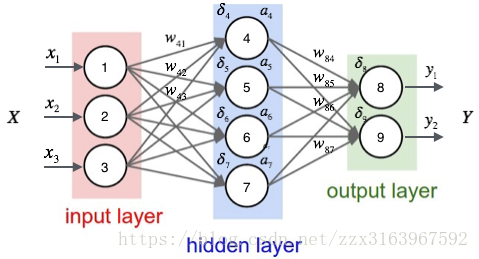
误差项是用来干什么的
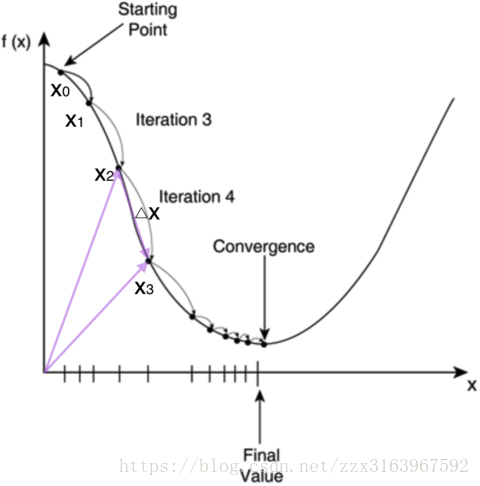
上图是梯度下降算法优化的示意图。
大致说明了梯度下降是去求 f(x)在最优解(上图为最小值)时 x 的值得过程
用于对神经网络的bp运算,主要是用来对权重值(w)的优化,而在全连接的过程中权重(w)始终参与运算的全过程,这就使得输出值y=f(w)是w的函数,而label是y的标签(就是y真实值),这相当于知道y的最优值去求解w,而目标函数为了符合优化的特点,我们希望是y与label越向近越好,因此用误差平方和来做目标函数,公式如下:

用梯度下降的方式来训练的公式如下:
这里
现在来求
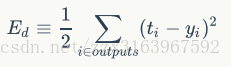
而我们要求的其实是

xji是节点i传递给节点j的输入值有时记为aji,
对于不同的节点有不同的计算方式,对于全连接来说,主要是分为隐藏层,和输出层,对于rnn来说,隐藏层的计算方式,就是多加了一个时间节点上反向传播,对于lstm不同的门,有不同的计算方式,但根本还是bp方法。
这里分为 输出层 和 隐含层
对于输出层:



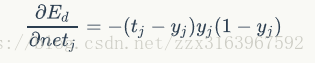

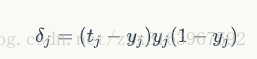
最后的梯度下降公式为:

对于隐藏层来说:


这是重点:需要记忆的部分
以上是公式的推导,其实我们主要是了解公式
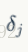
还是先看图:
对于输出节点,计算需要记下例子:
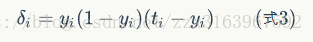

用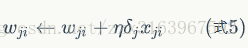

对于隐含层节点,计算需要记下例子:

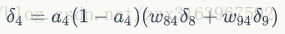
用
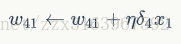
以上可以看出反向传播其实是一个递推过程,这样写代码时,其实并不是非常的复杂。
bptt算法:
这里是要记忆的部分,推导过程,理解就可以。
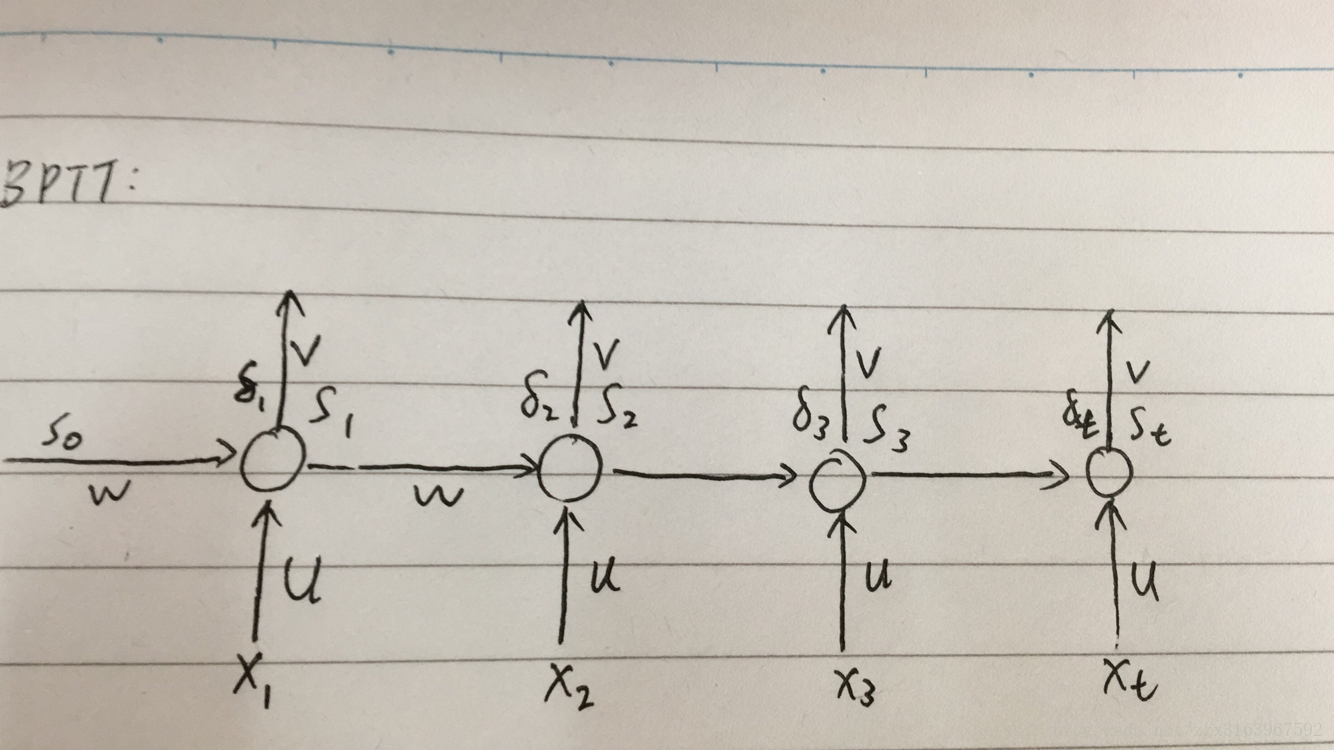
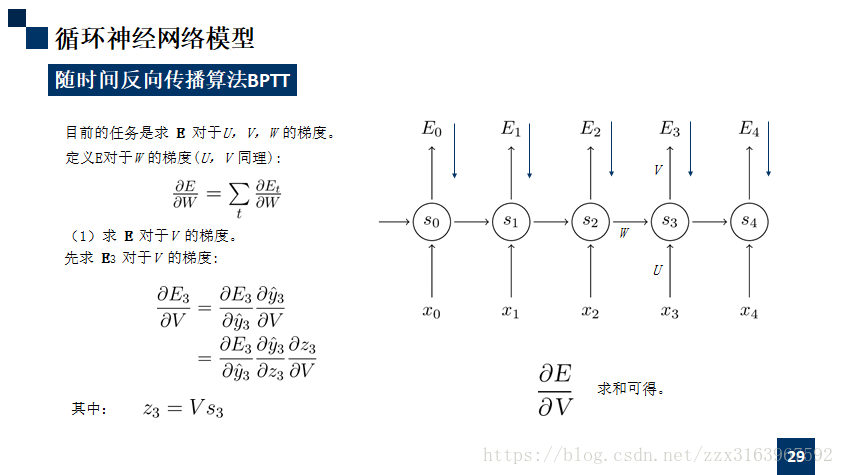
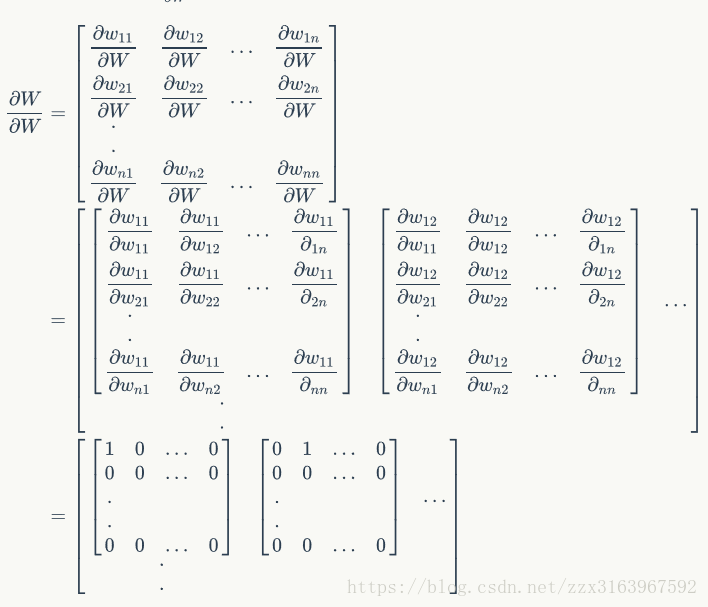
注意ppt中的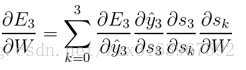
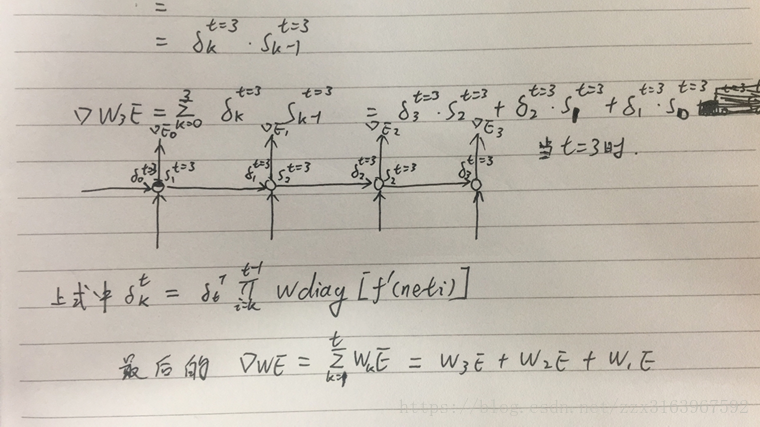
再用公式

下面是推到过程:
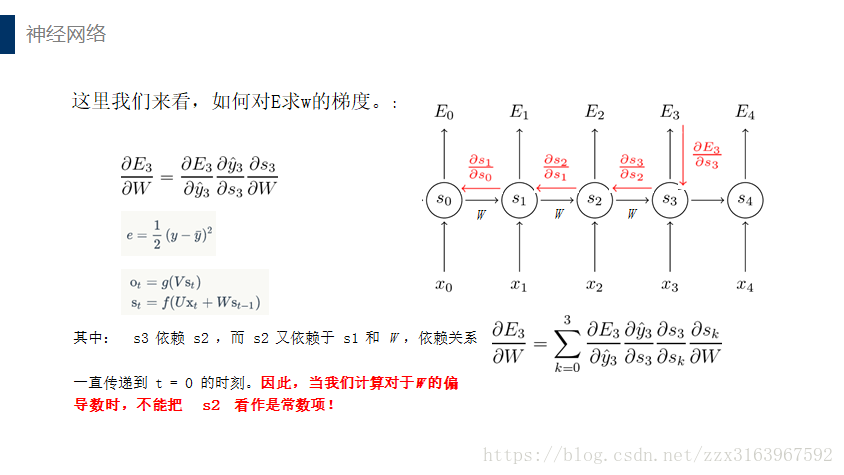
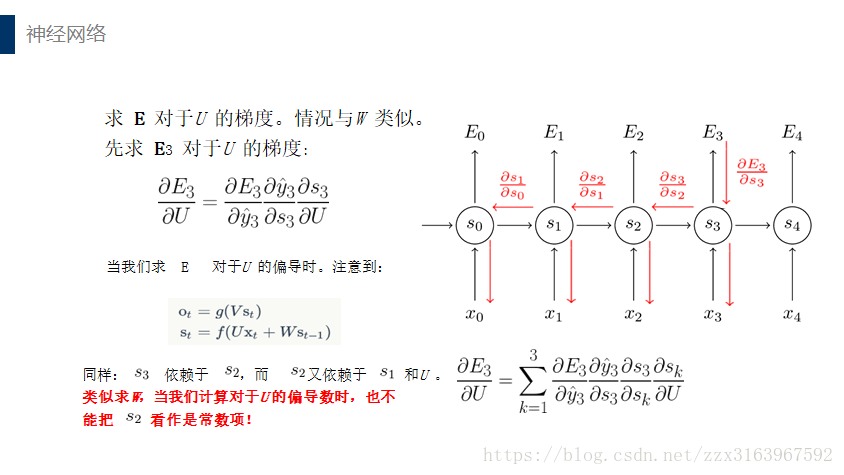
计算w和u时,用bptt算法,最后一个时刻的误差项,是如全连接一样的算法来计算的
而中间个时刻的误差项是以下公式推导出来的:

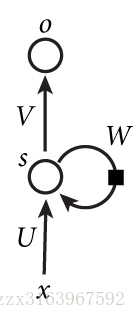
但是由于如上图(右)所示,w在正向传播时是同一个矩阵,所以在最后去用梯度下降算法计算w时,用的是各个时刻(t)的梯度的总和,计算公式如下:
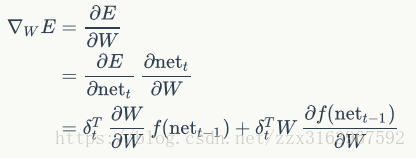

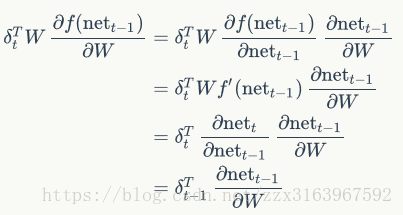
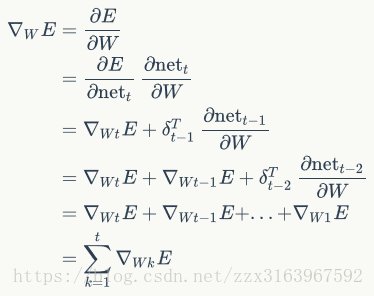
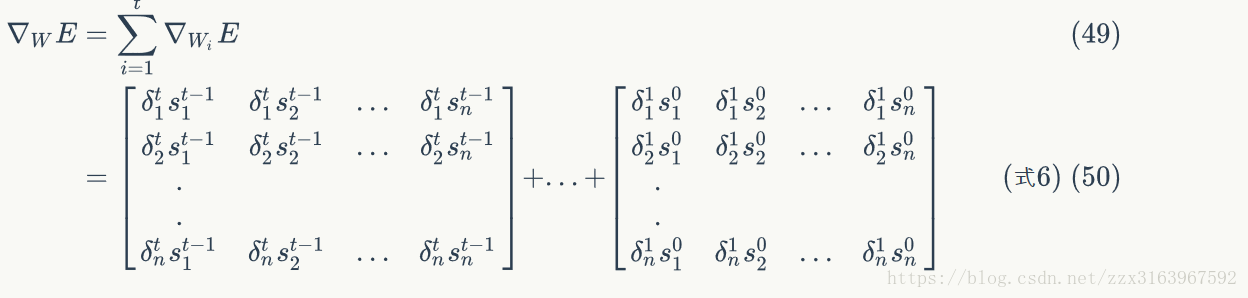
以上是
下面这是式子说明w的链接方式,就是说,w在各个时间之间的连接时和全连接一样的链接方式。这样才有w21,w12.