文章地址:https://arxiv.org/pdf/1603.01360.pdf
文章标题:Neural Architectures for Named Entity Recognition(命名实体识别的神经结构)NNACL2016
代码地址:
- 1、LSTM-CRF:https://github.com/glample/tagger
- 2、Stack-LSTM:https://github.com/clab/stack-lstm-ner
Abstract
最先进的命名实体识别系统严重依赖手工制作的功能和领域特定的知识,以便有效地学习小型的、监督训练语料库。在这篇文章中,我们介绍了两种新的神经结构——一种基于双向LSTMs和条件随机域,另一种基于移位-减少解析器的基于转换的方法来构造和标记片段。我们的模型依赖于两个关于单词的信息来源:从监督语料库学习的基于字符的单词表示和从无注释语料库学习的非监督单词表示。我们的模型在四种语言的NER中获得了最先进的性能,而无需借助于任何特定于语言的知识或资源,如地名辞典。
一、Introduction
命名实体识别是一个具有挑战性的学习问题。一方面,在大多数语言和领域,只有非常少的监督训练数据可用。另一方面,对于可以作为名称的单词的种类几乎没有限制,因此从这个小的数据样本中进行归纳是困难的。因此,精心构建的正字法特征和特定语言的知识资源,如地名辞典,被广泛用于解决这一任务。不幸的是,在新语言和新领域中开发语言特定的资源和特性的成本很高,这使得NER很难适应。从无注释的语料库中进行无监督学习为从少量监督中获得更好的泛化提供了另一种策略。然而,即使是广泛依赖于无监督特性的系统(Collobert等人,2011;Turian等人,2010;林和吴,2009;Ando和Zhang, 2005b,除其他外)已经使用这些来补充,而不是取代手工设计的功能(例如,关于特定语言中的大写模式和字符类的知识)和专门的知识资源(例如,地名词典)。
在这篇论文中,我们提出了一种神经网络架构,它不需要使用特定语言的资源或特性,只需要少量的监督训练数据和未标记的语料库。我们的模型旨在捕捉两种直觉。首先,由于名称通常由多个标记组成,因此对每个标记的标记决策进行联合推理非常重要。我们在这里比较两个模型,(i)一个双向的LSTM与它上面的一个顺序条件随机层 (LSTM-CRF) 和(ii)一个新的模型,该模型使用基于转换的解析算法构造和标记输入语句块,状态由堆栈LSTMs (S-LSTM) 。第二,“成为一个名字”的标记级证据包括正字法证据(被标记为名字的单词长什么样?)和分布证据(被标记的单词在语料库中的位置?)为了捕获正字法敏感性,我们使用基于字符的单词表示模型(Ling等,2015b)来捕获分布敏感性,我们将这些表示与分布表示相结合(Mikolov等,2013b)。我们的单词表示将这两种方法结合起来,并使用随机失活训练来鼓励模型学会信任两种证据来源。
在英语、荷兰语、德语和西班牙语中进行的实验表明,我们能够使用荷兰语、德语和西班牙语的LSTM-CRF模型获得最先进的NER性能,并且非常接近最先进的英语,不需要任何手工设计的功能或地名表。基于转换的算法也同样超越了之前以几种语言发布的最佳结果,尽管它的性能不如LSTM-CRF模型。
二、LSTM-CRF Model
我们提供了LSTMs和CRFs的简要描述,并提出了一个混合的标记体系结构。这种架构与Collobert等人(2011)和Huang等人(2015)提出的架构类似。
2.1 LSTM
递归神经网络是一类对序列数据进行处理的神经网络。它们取一个向量序列(x1,x2,…,xn)作为输入,并返回另一个序列(h1,h2,…,hn),表示在输入的每一步中该序列的一些信息。虽然在理论上,RNNs可以学习长依赖关系,但在实践中,他们不能做到这一点,往往会偏向于他们在序列中最近的输入(Bengio et al., 1994)。长期短期记忆网络(LSTMs)被设计成通过合并一个记忆单元来解决这个问题,并被证明能够捕获长期依赖。他们使用几个门来控制输入给记忆单元的比例,以及从先前状态到遗忘的比例(Hochreiter和Schmidhuber, 1997)。我们使用以下实现:

其中,δ表示元素的sigmoid函数,⊙表示元素的产出。
对于一个包含n个单词的给定句子(x1,x2,…,xn),每个单词都用d维向量表示,LSTM在每个单词t处计算句子左上下文的表示ht。自然,生成右上下文ht的表示也应该添加有用的信息。这可以使用第二个LSTM来实现,它以相反的方式读取相同的序列。我们将前者称为前向LSTM,后者称为后向LSTM。这是两个具有不同参数的不同网络。这种前向和后向LSTM对称为双向LSTM (Graves和Schmidhuber, 2005)。
使用该模型的单词表示是通过连接其左右上下文表示ht=[ht→;←ht]来获得的。这些表示有效地包括上下文中单词的表示,这对于许多标记应用程序非常有用。
2.2 CRF Tagging Models
一个非常简单但却非常有效的标记模型是使用ht作为特性,为每个输出yt做出独立的标记决策(Ling et al., 2015b)。尽管该模型在简单的问题(如POS标记)上取得了成功,但是当输出标签之间有很强的依赖性时,它的独立分类决策就会受到限制。NER就是这样一个任务,因为描述可解释的标记序列的“语法”施加了几个硬约束(例如,I-PER不能遵循B-LOC)这是不可能用独立假设来建模的。
因此,我们不是独立地对标记决策进行建模,而是联合使用条件随机字段对它们进行建模(Lafferty et al., 2001)。对于输入句:
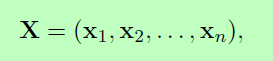
我们认为P是双向LSTM网络输出的分数矩阵。P的大小是n*k,k不同标签的数量,并且Pij表示一个句子中第i个单词的第j个标记的得分。对于一系列的预测:
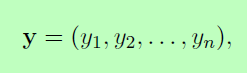
我们定义它的分数为:
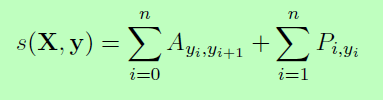
其中A是一个转换分数矩阵,Aij表示从标签i到标签j的转换分数。y0和yn是一个句子的开始和结束标签,我们将它们添加到可能的标签集合中。因此Ais是一个大小为k+2的方阵。
所有可能的标签序列上的softmax产生一个序列y的概率:
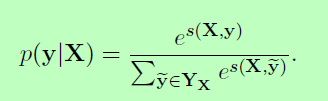
在训练过程中,我们最大化了正确标签序列的对数概率:
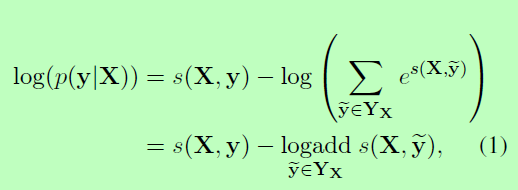
其中YX表示一个句子x的所有可能的标记序列(即使是那些没有验证IOB格式的序列)。从上面的公式可以明显看出,我们鼓励我们的网络生成一个有效的输出标记序列。在解码时,我们预测得到最大分值的输出序列为:
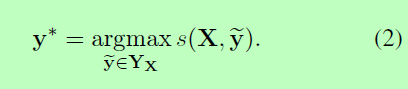
由于我们只是对输出之间的双图交互进行建模,因此两个输出都是公式1中的总和,并且最大后验序列y在公式2中可以使用动态规划计算。
2.3 Parameterization and Training

图一:网络的主要架构。词嵌入被给予一个双向LSTM。li表示单词i及其左上下文,ri表示单词i及其右上下文。将这两个向量连接起来,就得到了单词i在其上下文中的表示形式ci。
与每个标记的每个标记决策相关的分数(即,Piy’s)被定义为一个词的嵌入(使用双向lstm计算上下文)与Ling等人(2015b)的词性标注模型完全相同的点积,这些点积与双字母的兼容性评分(即,Ay,y’s)。此体系结构如图1所示。圆表示观察到的变量,方块是它们的双亲的确定性函数,双圆是随机变量。
因此,该模型的参数为二元图相容性评分A的矩阵,以及产生矩阵P的参数,即双向LSTM的参数、线性特征权值和词嵌入。如第2.2部分所示,设xi表示一个句子中每个单词的词嵌入顺序,yi表示它们的关联标记。我们将在第4节中讨论如何对嵌入xi进行建模。单词嵌入序列作为双向LSTM的输入,它返回每个单词的左右上下文的表示,如2.1中所述。
这些表示被连接起来(ci)并线性投影到一个层上,该层的大小等于不同标记的数量。我们没有使用这一层的softmax输出,而是使用前面描述的CRF来考虑相邻标记,从而生成每个单词yi的最终预测。另外,我们观察到在ci和CRF层之间添加一个隐含层会略微改善我们的结果。这个模型的所有结果都包含了这个额外的层。这些参数经过训练,在给定观察到的单词的情况下,最大限度地提高一个标注语料库中NER标记的观察序列的公式1。
2.4 Tagging Schemes(标签计划)
命名实体识别的任务是为句子中的每个单词分配一个命名实体标签。单个命名实体可以在一个句子中跨越多个标记。句子通常以IOB格式表示(内部、外部、开头),其中每个标记都标记为B-label(如果标记是指定实体的开头),I-label(如果标记在指定实体中,但不是指定实体中的第一个标记),否则标记为O。然而,我们决定使用IOBES标签计划,约伯的变种常用的命名实体识别,编码单信息实体(S)和明确的结束标志着命名实体(E)。使用这种方案,标记一个单词是我标榜高信任度缩小了随后的词我标榜的选择或E-label,然而,约伯的计划仅仅是能够确定后续的词不能内部的另一个标签。Ratinov和Roth(2009)以及Dai等人(2015)表明,使用更有表现力的标签方案,如IOBES,可以略微提高模型性能。然而,我们没有观察到IOB标记方案的显著改进。
三、Transition-Based Chunking Model(跃迁过程分块模型)
作为上一节讨论的LSTM-CRF的替代方案,我们将探索一种新的体系结构,它使用类似于基于转换的依赖项解析的算法对输入序列进行块处理和标记。这个模型直接构造了多标记名称的表示(例如,Mark Watney这个名称被组合成一个单一的表示)。
此模型依赖于堆栈数据结构以增量方式构造输入块。为了获得这个用于预测后续操作的堆栈的表示,我们使用了Dyer等人(2015)提出的堆栈-LSTM,其中LSTM被一个“堆栈指针”扩充。虽然按顺序的LSTMs从左到右建模序列,但堆栈LSTMs允许嵌入一组对象,这些对象既可以添加(使用push操作),也可以删除(使用pop操作)。这使得Stack-Lstm可以像一个栈一样工作,维护其内容的“摘要嵌入”。为了简单起见,我们将这个模型称为Stack-LSTM或S-LSTM模型。
最后,我们建议有兴趣的读者参考原始的论文(Dyer et al., 2015),以获得关于堆栈LSTM模型的详细信息,因为在本文中,我们只是通过在下一节中介绍的基于转换的新算法来使用相同的体系结构。
3.1 Chunking Algorithm(分块算法)

图二:Stack-LSTM模型的转换,指示应用的操作和结果状态。粗体符号表示词与关系的嵌入,文字符号表示相应的词与关系。
我们设计了一个转换清单,如图2所示,它受到基于转换的解析器的启发,特别是Nivre(2004)的arc标准解析器。在这个算法中,我们使用了两个堆栈(分别表示已完成的块和空白的指定输出和堆栈)和一个包含尚未处理的单词的缓冲区。过渡库存包含以下转变:转变过渡移动堆栈缓冲区的一句话,直接从缓冲过渡动作一个词到输出栈而减少(y)过渡弹出所有项目从堆栈的顶部创建一个“块”,标签与标签y,并把这一块的表示到输出栈。当堆栈和缓冲区都为空时,算法完成。该算法如图2所示,它显示了处理Mark Watney visit Mars这句话所需的操作顺序。
通过定义每个时间步上操作的概率分布(给定堆栈、缓冲区和输出的当前内容以及所采取的操作的历史),将模型参数化。在Dyer等人(2015)之后,我们使用堆栈LSTMs来计算每个这些的固定维嵌入,并将它们串联起来以获得完整的算法状态。此表示形式用于定义在每个时间步骤中可能采取的操作的分布。在给定输入语句的情况下,对模型进行训练以最大化参考动作序列的条件概率(从标记的训练语料库中提取)。为了在测试时标记一个新的输入序列,我们贪婪地选择最大概率动作,直到算法达到终止状态。虽然这不能保证找到全局最优,但在实践中是有效的。由于每个标记要么直接移动到输出(1个操作),要么先移动到堆栈,然后再移动到输出(2个操作),因此长度为n的序列的操作总数最多为2n。
值得注意的是,这个算法模型的性质使得它与所使用的标记方案无关,因为它直接预测被标记的块。
3.2 Representing Labeled Chunks(代表标记块)
在执行REDUCE(y)操作时,算法将一系列标记(连同它们的向量嵌入)作为单个已完成的块从堆栈转移到输出缓冲区。为了计算这个序列的嵌入,我们在其组成标记的嵌入上运行一个双向LSTM,并使用一个表示要标识的块的类型的标记(即该函数表示为g(u,…,v,ry),其中ry是一个标签类型的学习嵌入。因此,输出缓冲区包含生成的每个标记块的单个向量表示,而不考虑其长度。
四、InputWord Embeddings
我们的两个模型的输入层都是单个单词的向量表示。从有限的NER训练数据中学习单词类型的独立表示是一个困难的问题:有太多的参数需要可靠地估计。由于许多语言都有正字法或形态学证据表明某物是名称(或不是名称),所以我们需要对单词拼写敏感的表示。因此,我们使用了一个模型,该模型通过组成单词的字符表示来构造单词的表示(4.1)。我们的第二直觉是,名字,可能个别地是相当不同的,在大语料库的规则的上下文出现。因此,我们使用从对词序敏感的大型语料库中获得的嵌入(4.2)。最后,为了防止模型过于依赖于一种表现形式或另一种表现形式,我们使用了dropout训练,并发现这对良好的泛化性能至关重要(4.3)。
4.1 Character-based models of words

图四:将“Mars”这个词的字符嵌入到一个双向LSTMs中。我们将它们的最后输出连接到查找表的嵌入中,以获得该单词的表示形式。
我们的工作与以前大多数方法的一个重要区别是,我们在训练中学习字符级特征,而不是手工设计单词的前缀和后缀信息。学习字符级嵌入具有学习特定于当前任务和领域的表示形式的优势。它们已被发现对于形态丰富的语言和处理词性标记和语言建模(Ling等,2015b)或依赖解析(Ballesteros等,2015)等任务的外露词汇问题非常有用。
图4描述了我们的体系结构,它根据单词的字符为单词生成嵌入词。 。在测试期间,在查找表中没有嵌入的单词被映射到灌入嵌入。为了训练灌篮嵌入,我们用概率为0:5的灌篮嵌入替换单例。在我们所有的实验中,前向和后向字符LSTMs的隐藏维数各为25,这使得我们基于字符的单词表示具有50维。
像RNNs和LSTMs这样的递归模型能够对很长的序列进行编码,但是它们的表现形式偏向于它们最近的输入。因此,我们期望前向LSTM的最终表示是单词后缀的准确表示,后向LSTM的最终状态是其前缀的更好表示。替代的方法——最显著的是像卷积网络——已经被提出用来从字符中学习单词的表示(Zhang et al., 2015;Kim等人,2015)。然而,convnets旨在发现其输入的位置不变特性。虽然这是适合很多问题,例如,图像识别(一只猫可以出现在任何图片),我们认为是位置相关的重要信息(例如,前缀和后缀不同的信息编码比茎),使得建模LSTMs一个先验更好的函数类单词和他们的角色之间的关系。
4.2 Pretrained embeddings
如Collobert等人(2011)所述,我们使用预先训练好的词嵌入来初始化查找表。我们观察到,与随机初始化的词相比,使用预先训练的词嵌入有显著的改进。嵌入件使用skip-n-gram (Ling等,2015a)进行预训练,这是word2vec (Mikolov等,2013a)的一个变体,用于解释词序。这些嵌入在培训期间进行了微调。
针对西班牙语、荷兰语、德语和英语的Word embeddings培训分别使用西班牙语Gigaword版本3、莱比锡语料库集、来自2010年机器翻译研讨会的德语单语培训数据和英语Gigaword版本4(去掉了《洛杉矶时报》和《纽约时报》的部分内容)。我们为英语使用100的嵌入维数,为其他语言使用64的嵌入维数,最小词频截止为4,窗口大小为8。
4.3 Dropout training
最初的实验表明,字符级嵌入与预先训练的单词表示一起使用时,并不能提高我们的整体性能。为了鼓励模型依赖于这两种表示,我们使用了dropout训练(Hinton et al., 2012),在图1中的双向LSTM输入之前,将dropout掩码应用到最后的嵌入层。使用dropout后,我们发现我们的模型性能有了显著的改善(见表5)。
五、Experiments
本节介绍了我们用来训练模型的方法,我们在各种任务中获得的结果,以及我们的网络配置对模型性能的影响。
5.1 Training
对于提出的两个模型,我们使用反向传播算法来训练我们的网络,每次更新一个训练实例的参数,使用学习率为0:01、梯度裁剪为5:0的随机梯度下降(SGD)。提出了几种提高SGD性能的方法,如Adadelta (Zeiler, 2012)或Adam (Kingma和Ba, 2014)。虽然我们观察到使用这些方法可以更快地收敛,但是它们都没有使用梯度裁剪的SGD表现得好。
我们的LSTM-CRF模型为正向和反向lstm使用一个单层,其维度设置为100。调优这个维度不会显著影响模型性能。我们把随机失活率设为0:5。使用较高的心率会对我们的结果产生负面影响,而较低的心率会导致较长的训练时间。
Stak-Lstm模型为每个堆栈使用两个各为100维的层。复合函数中使用的动作的嵌入各有16个维度,输出嵌入的维度为20。我们尝试了不同的辍学率,并使用每种语言的最佳辍学率来报告分数。这是一个贪心模型,它应用局部最优的动作,直到整个句子被处理,进一步的改进可能通过beam search (Zhang and Clark, 2011)或training with exploration (Ballesteros et al., 2016)获得。
5.2 Data Sets
我们在不同的数据集上测试我们的模型,以进行命名实体识别。为了证明我们的模型泛化到不同语言的能力,我们展示了在CoNLL-2002和CoNLL-2003数据集上的结果(Tjong Kim Sang, 2002;Tjong Kim Sang和De Meulder, 2003),其中包含英语、西班牙语、德语和荷兰语的独立命名实体标签。所有数据集包含四种不同类型的命名实体:位置、人员、组织和其他不属于前三种类型的实体。虽然POS标签对所有数据集都是可用的,但是我们没有在我们的模型中包含它们。我们没有执行任何数据集预处理,除了用英文NER数据集中的0替换每个数字。
5.3 Results

表一:英语水平测试结果(CoNLL-2003测试集)。*表示使用外部标记数据训练的模型
表1展示了我们与其他英语命名实体识别模型的比较。为了使我们的模型和其他模型之间的比较公平,我们报告了其他模型的得分,这些模型使用和不使用外部标记数据,如地名表和知识库。我们的模型不使用地名表或任何外部标记的资源。在这项任务中,罗等人(2015)的得分最高。他们通过联合建模NER和实体连接任务获得了91.2的F1 (Hoffart et al., 2011)。他们的模型使用了很多手工设计的功能,包括拼写功能、WordNet集群、Brown集群、POS标签、chunk标签,以及词干提取和外部知识库(如Freebase和Wikipedia)。我们的LSTM-CRF模型优于所有其他系统,包括使用外部标记数据(如地名表)的系统。除了Chiu和Nichols(2015)提出的模型外,我们的Stack-LSTM模型也优于所有不包含外部特征的先前模型。
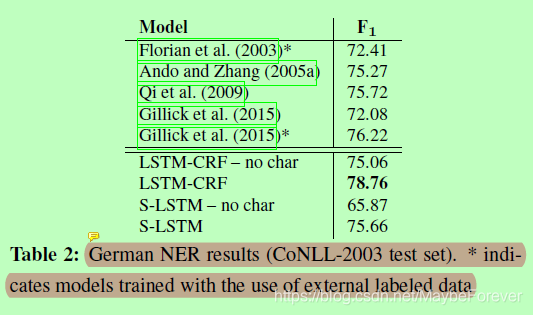
表二:德国NER结果(CoNLL-2003测试集)。*表示使用外部标记数据训练的模型

表三:荷兰NER (CoNLL-2002测试集)。*表示使用外部标记数据训练的模型

表四:西班牙语NER (CoNLL-2002测试集)。*表示使用外部标记数据训练的模型
表2、3和4分别展示了我们对德语、荷兰语和西班牙语的NER与其他模型的比较结果。在这三种语言中,LSTM-CRF模型的性能显著优于所有以前的方法,包括使用外部标记数据的方法。唯一的例外是荷兰,Gillick等人(2015)的模型可以更好地利用来自其他NER数据集的信息。与不使用外部数据的系统相比,Stack-LSTM还始终如一地显示最优(或接近)结果。
从表中可以看出,Stack-LSTM模型更依赖于基于字符的表示来实现竞争性能;我们假设LSTM-CRF模型需要较少的正投影信息,因为它能从双向Lstm中获得更多的上下文信息;但是,Stack-LSTM模型逐个消耗单词,并且在分解单词时仅依赖单词表示。
5.4 Network architectures

表五:使用不同的配置,用我们的模型得到结果。“预训练”指的是包含预训练词嵌入的模型,“char”指的是包含基于字符的单词建模的模型,“dropout”指的是包含dropout率的模型。
我们的模型有几个组件,我们可以调整它们来了解它们对整体性能的影响。我们探讨了CRF、字符级表示、词嵌入和删除的预训练对LSTMCRF模型的影响。我们观察到,预习我们的词嵌入给我们在F1 +7:31的整体表现带来了最大的改善。CRF层增加了+1:79,使用dropout增加了+1:17,最后学习character-level word embeddings增加了约+0:74。对于Stack-LSTM,我们进行了类似的一组实验。不同架构的结果如表5所示。
六、Related Work
在CoNLL-2002的共享任务中,Carreras等人(2002)通过合并几个固定深度的小型决策树,在荷兰语和西班牙语上获得了最好的结果。第二年,在CoNLL- 2003的共享任务中,Florian et al.(2003)通过综合四种不同分类器的输出,获得了德语的最好成绩。Qi等人(2009)后来通过在大量未标记的语料库上进行无监督学习,用神经网络改进了这一点。
先前已经为NER提出了几个其他的神经结构。例如,Collobert et al.(2011)在一系列嵌入词上使用CNN,并在顶部使用CRF层。这可以被认为是我们的第一个没有字符级嵌入的模型,双向LSTM被一个CNN所取代。最近,Huang等人(2015)提出了一个类似于我们的LSTM-CRF的模型,但是使用了手工拼写功能。Zhou和Xu(2015)也使用了类似的模型,并将其应用于语义角色标记任务。Lin和Wu(2009)使用了带有L2正则化的线性链CRF,他们添加了从web数据中提取的短语簇特征和拼写特征。Passos等人(2014)也使用了带有拼写特征和地名表的线性链CRF。
像我们这样的语言无关的NER模型在过去也被提出过。Cucerzan和Yarowsky (1999;2002)提出了一种用于命名实体识别的半监督自举算法,该算法通过共同训练字符级(内部词)和标记级(上下文)特征来实现。Eisenstein et al.(2011)使用贝叶斯非参数化方法在几乎无监督的情况下建立了一个命名实体的数据库。Ratinov和Roth(2009)定量比较了几种NER方法,并使用正则化的平均感知器和聚合上下文信息构建了自己的监督模型。
最后,目前人们对使用基于字母的表示的NER模型很感兴趣。Gillick等人(2015)将测序任务建模为一个从序列到序列的学习问题,并将基于字符的表示纳入他们的编码器模型。 Chiu and Nichols (2015)使用一个架构类似于我们的,而是运用cnn学习字符级特性,在某种程度上类似于 Santos and Guimar˜aes (2015)。
七、Conclusion
本文提出了两种用于序列标记的神经结构,即使与使用外部资源(如地名词典)的模型相比,它们也能提供在标准评估环境中所报告的最佳NER结果。
我们的模型的一个关键方面是,它们对输出标签依赖关系建模,要么通过简单的CRF架构,要么使用基于转换的算法显式地构造和标记输入块。单词表示对于成功也至关重要:我们既使用预先训练的单词表示,也使用“基于字符的”表示,以捕获形态和正字法信息。为了防止学习者过于依赖一个表示类,使用了dropout。
