一、本文主要内容
1、(语标代替字母)问题:(1)中文命名实体识别中存在拼写错误、新词、不符合语法的结构;(2)缺乏明确的边界;(3)词切分糟糕;(4)典型的语料库只使用简体或繁体,但是社交媒体是混合的;(5)基于word的embedding,并不能在下游任务中有用;
2、先前技术:(1)CRF with BIOSE encoding,标记单个字符,而不是单词,因为分词错误对NER影响很大;利用地名索引的特征,仅仅只提升了一些任务分数;(2)词汇嵌入表示单词,可以大大提升NLP的相关任务,尤其是在NER中;预训练神经嵌入(pre-trained neural embeddings)作为特征加入NER系统中,也提升了效果;
3、本文首先使用三种类型的中文嵌入:
Word Embeddings 、Character Embeddings 、Character and Position Embeddings
179,809 word embeddings, 10,912 character embeddings, and 24,818 character with position embeddings。
其次,利用NER的训练文本,对embedding进行微调;使用预训练模型初始化embedding参数,然后在根据梯度下降过程中修改参数。
最后,Joint Training Objectives;由于对embedding进行微调会使得embedding偏离原始的含义,于是这里用到了合并目标函数的方法,即将NER任务的目标函数和训练embedding的目标函数结合起来,具体公式如下:
CRF模型的目标函数


标准skip-gram的目标函数
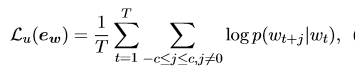
其中
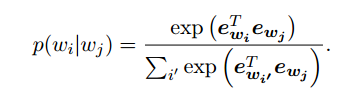
最后的目标函数是两者的加权,训练目标是使得下式最大,这里C是一个平衡参数,本文的实验中将其设为1。
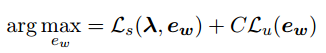
二、相关训练工作
embedding 100维、CRF迭代30次、5个多线程同时通过skip gram目标函数、避免过拟合使用early-stopping、C=1(后期使用这个C优化联合训练的目标函数)、CRF使用SGD和L2正则、现有的word2vec工具训练语言模型、最后用自己的CRF去修改嵌入
person, organization, location and geo-political entity四种实体
三、个人想法
中文的命名实体识别主要是针对比较规范的文本来进行的,对于中文社交媒体如微博这类比较不规范的文本,相关工作并不是很多。对于命名实体识别任务来说,基于统计机器学习的方法有隐马尔可夫模型、最大熵模型、条件随机场等,现在神经网络的方法也被用到序列标注问题中来,从而能够解决命名实体识别的问题。
1、使用word2vec训练语言模型,是否可以使用BERT、ALBERT等现在新进的替换,再看效果?
2、该文主要是解决了社交媒体的命名实体识别,在金融行业上是否一样实用?
3、对消歧有什么值得借鉴的嘛?好像没什么。。。。
4、该文主要是通过联合词嵌入,一起训练CRF,将不规则的微博中的命名实体识别出来,作者已开源相关代码和数据,可以细看(golden-horse)