一、本文主要内容
1、作者用character and position embedding,即对每一个在词的不同位置中出现的字训练一个字向量,如“北京”和“京都”,这两个“京”字的embedding是不同的,前者是京2,后者是京1;作者用到的联合训练的方式,即将训练词向量的目标函数与命名实体识别任务的目标函数结合起来,进行联合训练,这样可以防止单独对embedding进行微调时,使其偏离原有的意思,同时可以将在新语料中学到的信息传递给那些在当前语料中未出现的embedding中去。
基于以上的两点,作者提出了结合中文分词模型进行联合训练的方法,因为之前的实验表明,词的边界信息对命名实体识别任务有帮助,同时,联合训练也能帮助embedding更好地保存词的边界信息,整体的联合模型如下所示: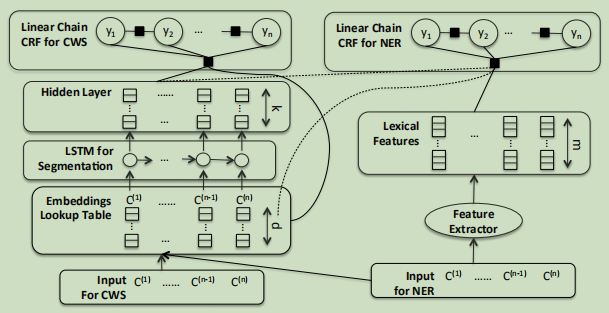
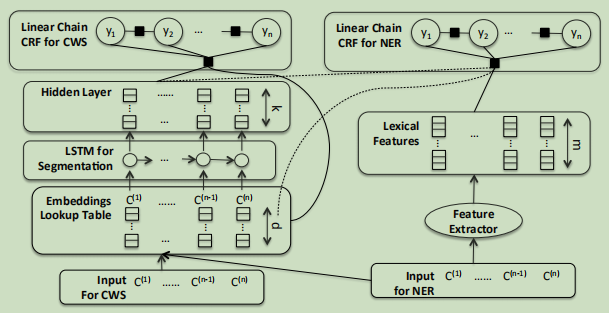
2、模型解析
左边是基于LSTM的中文分词模型,右边是基于CRF的NER模型,可以看到两个模型共享LSTM层,即训练分词模型与命名实体识别的模型都会更新LSTM的参数
(1)使用当前最好的中文分词模型LSTM,来自Chen et al. (2015),本质上是一个循环神经网络,使用一系列的门(输入、遗忘、输出)去控制记忆如何在隐藏状态模型中传播。对于中文分词任务来说,是将单个字初始化为一个d维向量,然后用LSTM在训练中修改它。
传统的神经网络模型
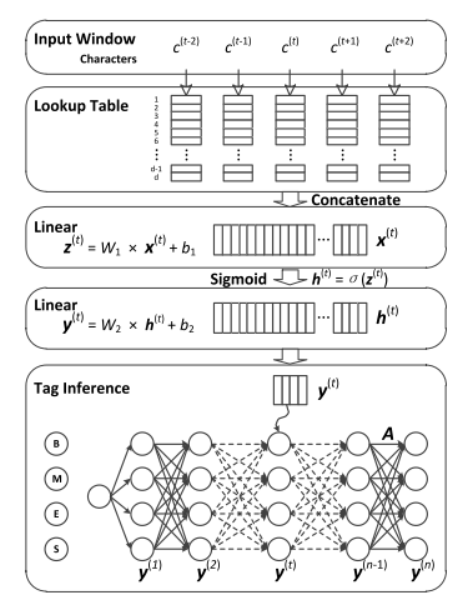
首先:输入字符,LSTM学习到一个隐藏向量 h ,与偏置线性变换去预测输出标签(在这种情况下输出为:Begin,Inside,End, and Singleton.),给出位置 t 的预测为:![]()
经过一个非线性变换得到隐层输出:![]() 再经过一个线性变换得到预测的标签y
再经过一个线性变换得到预测的标签y![]() ,再对标签之间的依赖建模,引入转移矩阵
,再对标签之间的依赖建模,引入转移矩阵,表示标签 i 到 j 的概率,即图中的tag inference部分。模型训练的目标函数:
![]()
其中,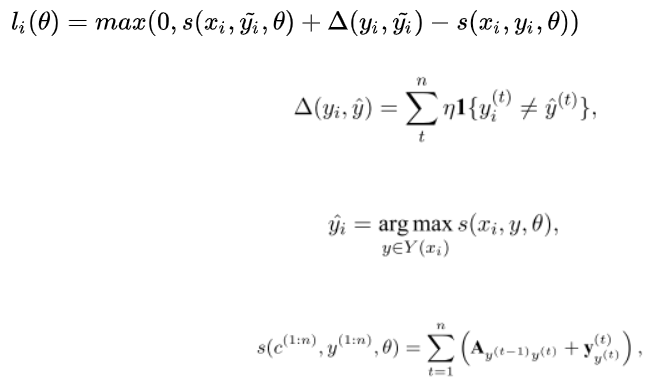
加入LSTM层,就是再隐层的部分用LSTM层进行替换,其余部分不变,具体公式如下:
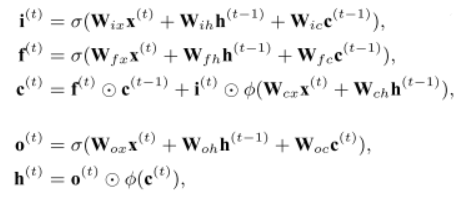
(2)基于Log-bilinear CRF的命名实体识别模型(Named Entity Recognition for Chinese Social Media with Jointly Trained Embeddings)
word embedding:先将文本进行分词,然后训练词向量,这个词中的所有字都用这个词向量来表示。
character embedding:训练每一个字的字向量
character and position embedding:先对文本进行分词,按照每个字在词中的出现位置分别训练带位置信息的字向量
Fine Tuning----利用NER的训练文本,对embedding进行微调
Joint Training Objectives:由于对embedding进行微调会使得embedding偏离原始的含义,于是这里用到了合并目标函数的方法,即将NER任务的目标函数和训练embedding的目标函数结合起来,具体公式如下:
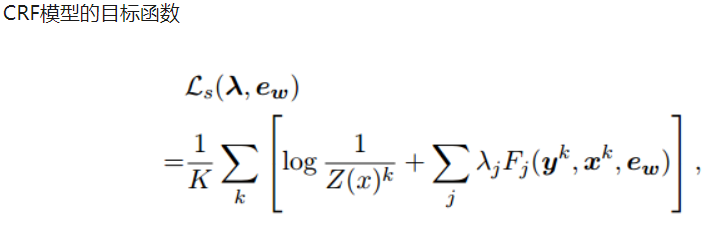
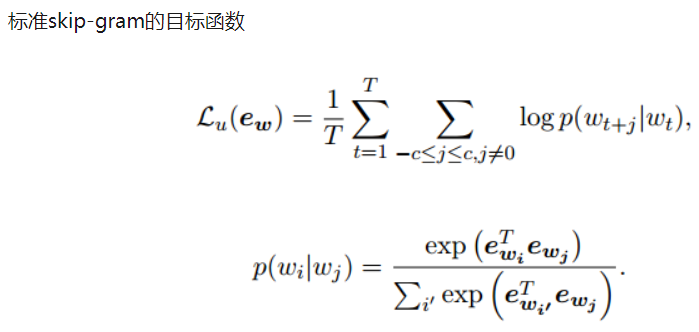
最后的目标函数是两者的加权,训练目标是使得下式最大,这里C是一个平衡参数,本文的实验中将其设为1。
![]()
(3)两者的联合模型
传统的神经网络模型,最后一个部分是tag inference,即对标签之间的依赖关系进行建模,最后的目标函数也与之有关。当讲两者联合在一起的时候,讲tag inference 改为一个CRF模型,去计算最大似然函数,目标函数如下: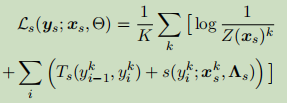
由于log-bilinear CRF已经支持词汇嵌入的联合训练,我们还可以使用联合目标函数将LS TM输出隐藏向量合并为动态特征,首先,用LSTM参数去增加CRF目标函数:
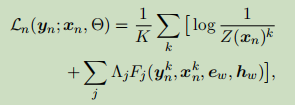
其中k索引实例、j位置和 表示特征函数为:

联合训练,目标函数为:
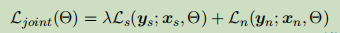
这里为调整两个目标函数权重的参数,因为联合模型的重点是命名实体识别,因而让
二、本文的相关效果
在基于已经提出的用RNN加CRF去处理序列标注任务,可以应用于词性标注、chunk、ner等任务,本文作者,通过添加字符级别的建模方法以及利用不同类型的RNN模型,在NER上去的了成效,但是对于需要分词或者不规则的社交媒体文本,效果一般。
于是作者基于以上的工作,联合训练了分词模型喝命名实体识别模型,通过引入分词的信息使得命名实体识别的效果有了很大的提升,而且不仅仅是以特征的方式引入分词信息,而是利用联合训练来获取,通过实验结果,可以看到作者关注的词语的边界信息,以及提到联合训练的方式是十分有效的。
三、个人相关想法
1、使用LSTM与LOG-bilinear CRF想结合,训练一个新的模型,这个模型能够在NER发挥很好,那现在的双向LSTM与CRF模型做NER,是否也是一个LOG-bilinear CRF?如果是,那么提升点在哪,如果不是,是否可以考虑这个做新模型。
2、该文章的分词采用的是word2vec,若采用更加高效的分词方法,是否能提升模型性能?
3、该代码是开源的,仔细阅读代码!!!!