一. 方法简述
这篇2022NAACL的论文提出ITA将图像特征多层次对齐到文本空间中(更好利用transformer model,多层次分别是局部-目标检测器,全局-图像描述,字符级-OCR),再concatenate T input 得到CrossModal input加入到Feed forward和ATT中达到Cross-View Alignment,使得两个模态输入View的输出分布的KL散度最小化。
PS:这点和另一篇NAACL的命名实体识别+关系抽取的论文( Good Visual Guidance Makes A Better Extractor Hierarchical Visual Prefix for Multimodal Entity and Relation Extraction)不同,本文注重的是多粒度对齐,而HVPNet这篇则是分层的视觉信息作为提示(Prefix-tuning),图片信息是Object images 和 Global images
[论文核心:专注于整合视觉信息,通过有效地对齐视觉和文本信息来改进输入Tokens的表示。]

PS:其实就是将视觉信息转为文本形式(多层次转化),与文本token拼接后就得到跨模态输入表示,然后将这个加到bert或者bart中来得到stronger token表示,再经过一层CRF得到序列标注,最后就是cross-view alignment预测输出分布,前面的方法类似于prompt-tuning,后面就是多粒度对齐。
二.方法详情
2.1 NER Model Architecture
transformer-based pretrained textual embeddings model的输出fed into a linear-chain CRF
layer(广泛用于序列标注问题)

2.2 Image-text Alignments
比起简单利用来自目标检测器的图像特征,通过图片信息生成文本,以此转化到文本空间的方式更可以很好地利用transformer-based model的自注意力机制。
Object Tags as Local Alignment(LA):
图像信息可以被分解为局部区域的一组对象标签文本对其局部信息进行描述。
首先用object detector OD 来识别和定位图像中的object,以抽取objects。
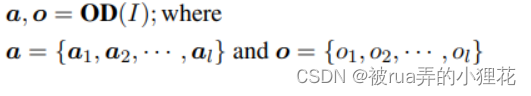
来自对象检测器的属性预测包含每个对象 oi 的多个属性标签 ai。
论文根据检测模型的置信度对对象进行线性化和降序排序。,而对于每个对象,启发式地保留 0 到 3 个置信度分数高于阈值 m 的属性。由于属性是描述object tag的形容词,因此将 attributes线性化,并将属性放在相应的对象之前。
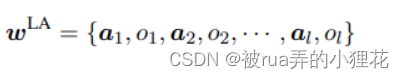
因此,我们将来自对象检测器的预测 l 个对象标签 o 及其属性标签 a 作为局部对齐的视觉上下文 wLA:
Image Captions as Global Alignment(GA):
尽管LA可以定位object,但不能完全描述整个图像。因此采用图像描述模型IC生成k个图像描述来对齐图像,再采用[X]分割开,bert中可以用[X]来seperate。

Optical Character Alignment(OCA):
图像中可能会有一些富含语义信息的文字,可采用光学符号识别模型OCR来抽取图像中的文本
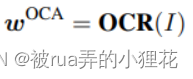
然而,wOCA这很可能为空,wˆ = [w; w‘ ]其中 w’ 可以是 wLA、wGA、wOCA 之一或 all 的串联。
以上三个拼接的I+T input view 丢进文本模型中得图文融合token{r’1,r’2,…,r’n},然后fed into CRF layer来得到概率分布pθ(y|wˆ ).I+T 输入view目标函数如下

Cross-View Alignment(CVA):
将图像合并到 NER 预测中有几个限制:test的时候可能没图像只有文本,预处理pipeline比端到端方式更耗时,图像噪音会误导预测结果。
CVA则可以减少 I+T and T input views在输出分布上的gap,更好利用文本信息。具体来说就是
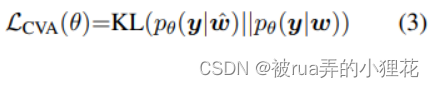
为了保证 I+T and T input views精度相匹配( I+T有额外的I信息),反向传播时就只传递pθ(y|w) ,因此Eq.3等价于计算两个分布的交叉熵损失:

由于所有可能的标签序列集合 Y(x) 的大小是指数的,论文通过 forward-backward algorithm计算每个位置 pθ(yi|w) 和 pθ(yi|w^) 的后验分布来逼近 Eq . 4:

Training 在训练过程中,论文用公式1和2中的训练目标与公式5中的CVA对齐训练目标jointly train T 和 I+T 输入视图,因此,ITA 的最终训练目标是:
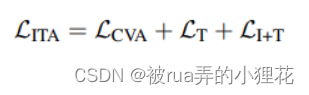
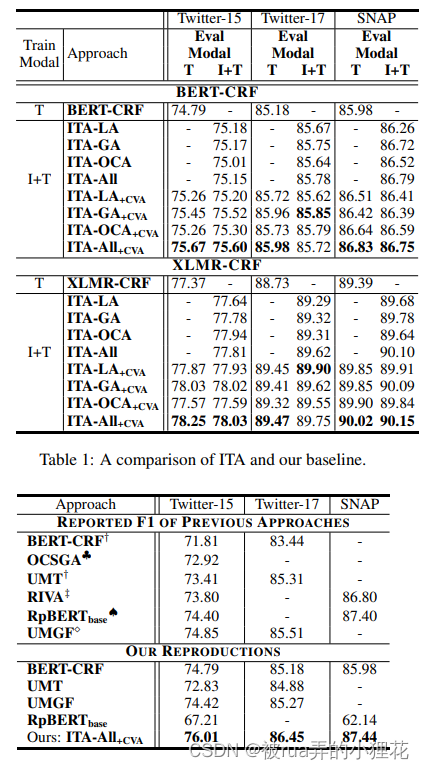
三. 实验效果