背景
实体识别是信息抽取中一个老生常谈的任务。实体识别主要包含三种类型:flat,overlapped(nested), discontinuous NER, 也就是我们常说的常规NER,嵌套NER以及不连续的NER。下面看一篇将这三种类型的NER全部融合到一个模型中的parer:Unified Named Entity Recognition as Word-Word Relation Classification.
当前效果比较好模型主要包括基于span的以及使用sequence2sequence的模型,基于span的模型主要是关注span的边界信息,后者会有很大的暴露偏差(exposure bias)。这篇文章提出的统一(一个模型同时解决三种类型的任务)的NER识别模型,名称为word-word relation classioncation W 2 N E R W^2NER W2NER),模型通过构建一种实体词之间的schema去解决现有的瓶颈。schema 中包含Next-Neighboring-Word(NHW),Tail-Head-Word-* (THW- *) relation。模型将一个语句构建成一个二维的word pairs网格,使用多粒度的二维卷积更好对这个网格进行表示, 最后,利用协同预测器对词与词之间的关系进行了充分的推理。这个模型在14个广泛使用的flat、重叠和不连续NER基准数据集(8个英文数据集和6个中文数据集)上进行了大量实验,在这些数据集上,该模型击败了所有当前性能最好的基线,达到sota水平。
下面我们具体来看一下这篇论文。
模型简介
该模型核心就是创造性地提出将实体抽取转换成word(中文就是字与字之间的关系)之间的关系抽取类别抽取。通过构建word与word之间关系的抽取可以解决flat、nested、discontinuous 这三种类型的NER识别任务,也就是标题所受的统一的实体抽取模型了。
对于一个语句 X X X,其由 N N N个token(中文可以看成字,英文可以看成单词)组成,那么一个语句就是 X = { x 1 , x 2 , ⋯ , x N } X=\{x_1,x_2,\cdots, x_N\} X={ x1,x2,⋯,xN},一个token pair就是 ( x i , x j ) (x_i, x_j) (xi,xj),token pair的关系 R ∈ { N o n e , N N W , T H W − ∗ } R\in \{None, NNW, THW-*\} R∈{ None,NNW,THW−∗},其中:
- None:就是表示token pair之间没有关系,也就是说不属于任何实体
- NNW:即Next Neighboring Word,表示两个token同属于一个实体,即存在相邻关系
- THW-*:即Tail Head Word,表示这两个word实在同一实体中,分别是实体的结尾和开头,*表示实体的类型,同时THW-*也用来表示一个实体的边界。
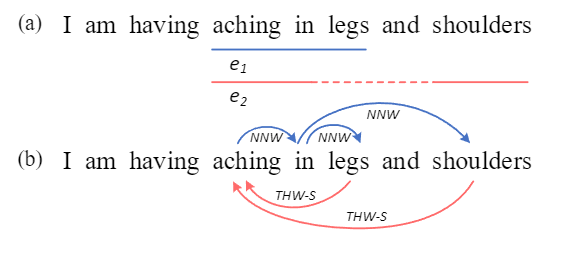
上图(a)中的句子中,有两个症状symptom实体"aching in legs"和"aching in shoulders",分别记作e1和e2,实体类型都是s;这两个实体,可以得到word-word之间的关系如图(b).
下面根据这个语句构建一个二维token pari网格如下:
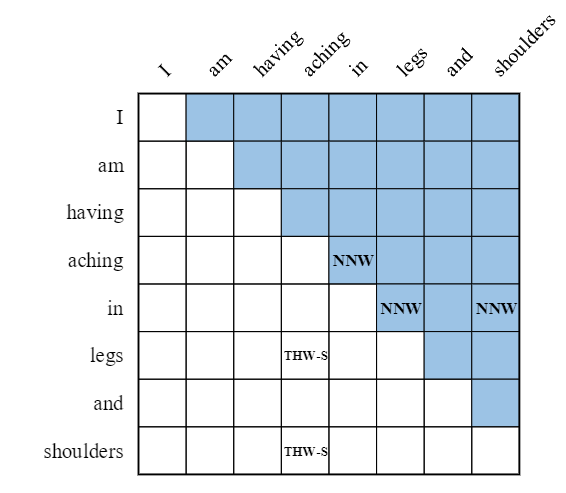
模型预测出对应的token pair关系类型后,就可以使用特定的解码器解码出最后的结果了。
模型结构
模型整体结构如下:
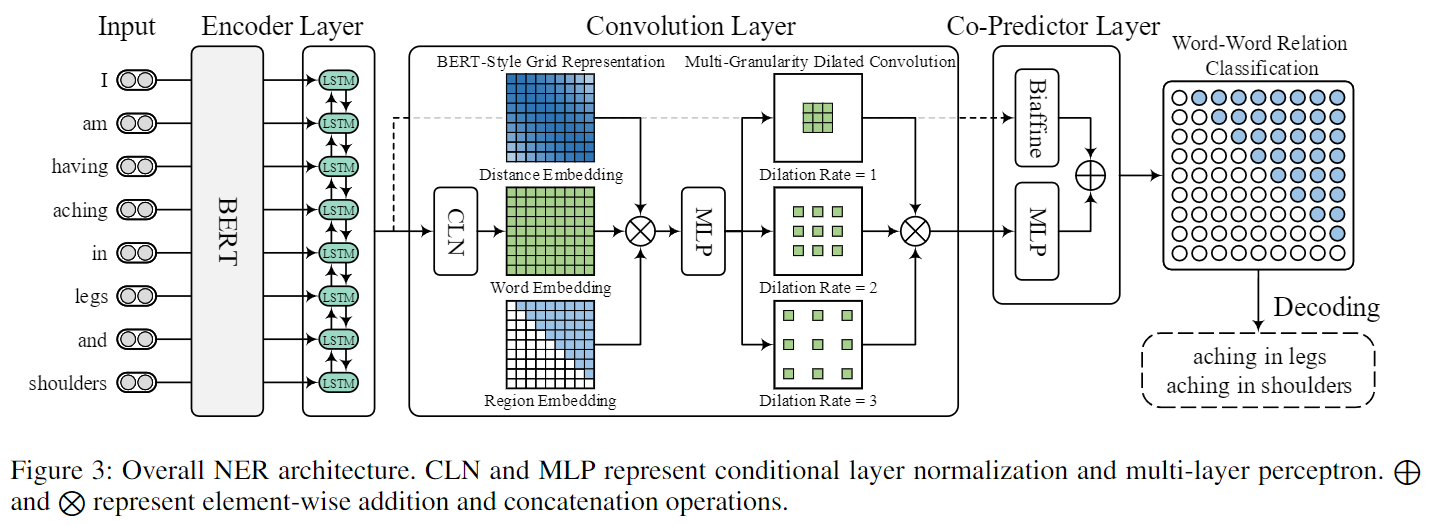
模型中的各个模块说明如下:
-
Input,输入语句sentence可以使用可以是word类型的也可以是字符类型的;
-
Encoder Layer,论文中使用的BERT+BiLSTM,将输入的sentence中的token做特征表示(representation),得到token representation,得到数据维度:[batch_size, batch_max_sentence_length, lstm_hidden_size];
-
Convolution Layer,该模块涉及多个部分:
- 将token representation使用Condition Normalization Layer(CLN)做标准化,得到一个cln结果,数据维度:[batch_size, batch_max_sentence_length, batch_max_sentence_length, lstm_hidden_size],用该结果表示token pair的Embedding
- BERT-Style Grid Representation, 下面就是为了丰富token pair的表示构建类似于bert (token embedding, position embedding, segment embedding三部分)网格表示,将token pair的distance embedding,region embedding 和token embedding按照最后一个维度进行拼接,然后再经过一个多层感知机(MLP),得到的数据维度:[batch_size, batch_max_sentence_length, batch_max_sentence_length, dist_emb_size + type_emb_size + lstm_hidden_size]
- Multi-Granularity Dilated Convolution,使用不同粒度的空洞卷积进行卷积计算,最后将卷积计算的结果进行拼接,得到的conv_outptus数据维度:[batch_size, output_height = batch_max_sentence_length, output_width = batch_max_sentence_length, conv_hidden_size * 3],3表示三个不同的空间卷积参数
-
Co-Predictor Layer,主要包含Biaffine和MLP,该层将cov_outputs的结果进行处理得到output,output的数据维度:[batch_size, batch_max_sentence_length, batch_max_sentence_length, label_num],label_num 表示token pair 关系类别个数。
关系解码
一个实体结果就是一个闭合的有向图,例如一个句子由"A B C D E"五个token组成,有如下预测结果:

情况(a)扁平实体:(A, B)的关系是NNW, (B, A)的关系是THW,组成了一个闭合的有向图,那么AB就是THW对应类别实体,同理DE也是如此;
情况(b)重叠实体:ABC,BC各自构成了闭合的有向图,其中ABC和BC重合;
情况©重叠实体+非连续实体:ABC, ABD各自构成了闭合的有向图,其中ABC和ABD存在部分重叠,并且ABD还是一个不连续的实体,
情况(d)两个不连续的冲突实体,ACD,BCE各自构成了闭合的有向图,其中ACD和BCE重叠了C。
数学理论
其中的Conditional Layer Normalization比较有意思。文中使用该层构建token pair的Embedding表示。使用 V i j V_{ij} Vij表示token: ( x i , x j ) (x_i, x_j) (xi,xj),具体计算如下:
V i j = C L N ( h i , h j ) = h j − μ σ ⊙ γ i j + β i j V_{ij} = CLN(h_i,h_j) = \frac{h_j - \mu}{\sigma}\odot \gamma _{i_j} + \beta_{ij} Vij=CLN(hi,hj)=σhj−μ⊙γij+βij
其中 h i h_i hi、 h j h_j hj都是token embedding,其中 h i h_i hi作为condition, σ \sigma σ是 h j h_j hj的均值, μ \mu μ是 h j h_j hj的方差。 h i h_i hi的均值和方差计算如下:
σ = 1 d h ∑ k = 1 d h h j k μ = 1 d h ∑ k = 1 d h ( h j − σ ) 2 + ϵ \begin{aligned} &\sigma=\frac{1}{d_h} \sum_{k=1}^{d_h} h_{j k}\\ &\mu=\sqrt{\frac{1}{d_h} \sum_{k=1}^{d_h}\left(h_j-\sigma\right)^2+\epsilon} \end{aligned} σ=dh1k=1∑dhhjkμ=dh1k=1∑dh(hj−σ)2+ϵ
其中 d h d_h dh为lstm_hidden_size.
通过 h i h_i hi这个condition计算参数 γ i j \gamma_{ij} γij和 β i j \beta_{ij} βij:
γ i j = W γ h i + b γ β i j = W β h i + b β \gamma_{ij} = W_{\gamma}h_i + b_\gamma \\ \beta_{ij} = W_{\beta}h_i + b_{\beta} γij=Wγhi+bγβij=Wβhi+bβ
总结
模型整体就是这么多内容,设计也是比较巧妙,效果也达到了当前的sota。当然想将该模型使用到具体工程中还需要做进一步的测试。论文作者也开源了代码:https://github.com/ljynlp/W2NER,有兴趣的可以查看。
后面会结合源码进行相关的实验,敬请期待。