前言
RNN:Recurrent Neural Network 是序列数据处理时匹配度最好的模型,现在对当前几个重要的RNN模型做个简单梳理。
RNN
RNN,循环神经网络,RNN具有天然的时间深度,并且对任意的序列数据场景具有适应性,即当样本间具有相关性时非常适合用RNN来解决,循环结构对变长数据的模型化具有天然优势。Forward Network则普遍假设样本将相互独立同分布且对输入size有限制,当样本间有相关性时和序列数据时就会难以搞定。
RNN相比于Forward 直连网络,引入了时序的概念,改进了跨时序相邻的边缘,以网络自身循环表示无限制时序过程。最简单的RNN结构和前向网络对比如下:
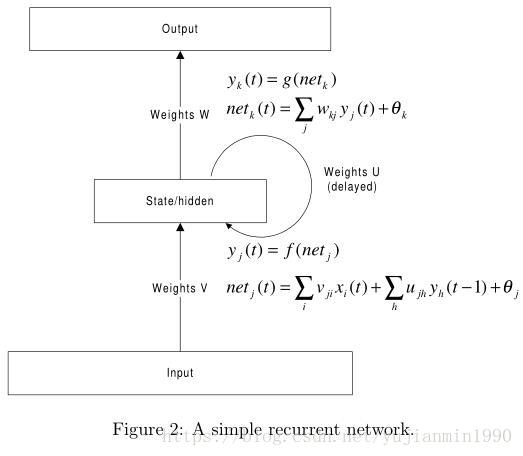
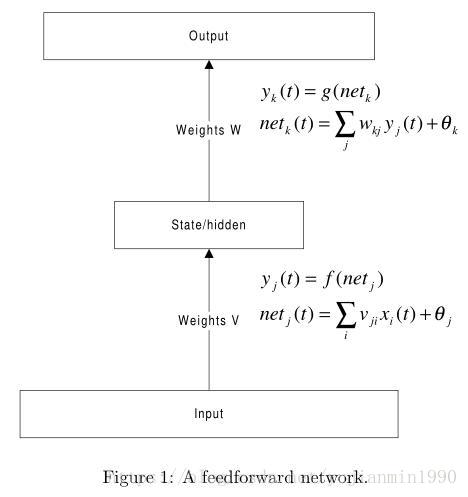
LSTM
LSTM:Long Short Term Memory 长短期记忆模型,最经典的RNN结构,从97年初创,几经变迁,结构也逐渐趋于现在所用的样式。
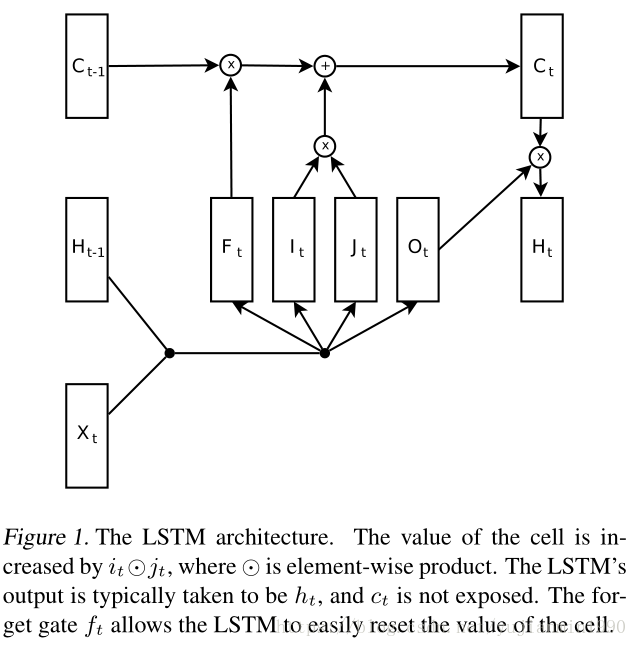
1997年,Hochreiter 和 Schmidhuber构造了最基本的LSTM结构。为克服RNN梯度消失的现象,引入了Memory cell,使得信息(包括梯度)可以无损跨过多时域。2000年,Gers为LSTM引入了Forget Gate,它是种重置机制,来克服内部状态无限增加导致网络崩溃的问题。另外Gers在另一篇论文里提出了Peephole Connection的结构。2002年的时候,LSTM就变成如下所示的结构【也是我们最常用的LSTM结构】,input node的激活函数也从原本的sigmoid变成了tanh函数。
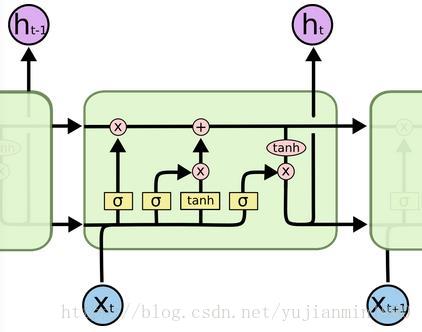
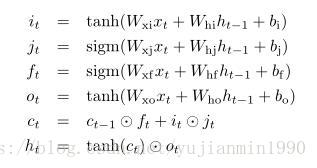
notice: 为解决梯度消失问题,非常经典的两个辅助结构。
1) Forward Networks:增加Skip-Connect【Identity-Connect】,最成功的是深度残差网络,详见这个 博客。
2) Recurrent Networks:增加 Memory-Cell,最成功的是LSTM系列。
两个辅助结构都是一个目的:将信息能够无损地传递到下一步。
GRU
GRU:Gated Recurrent Unit,门循环单元模型,结构更为简单但性能卓越不弱LSTM。2014年的时候,Cho为解决机器翻译问题,首次尝试用Encoder-Decoder结构来学习翻译的短语对,来辅助统计翻译模型提高性能。其中Encoder-Decoder使用的RNN结构就是GRU,你完全想不到,这个简单到令人发指的RNN结构后面会有如此惊人的表现。

Deep RNN Architecture
RNN先天带有时间维上的深度特性,而当我们将其空间上的深度拓展开来后,是否会有同等Forward Network的作深度之后的惊喜呢。问题是怎么加深RNN在空间上的深度?
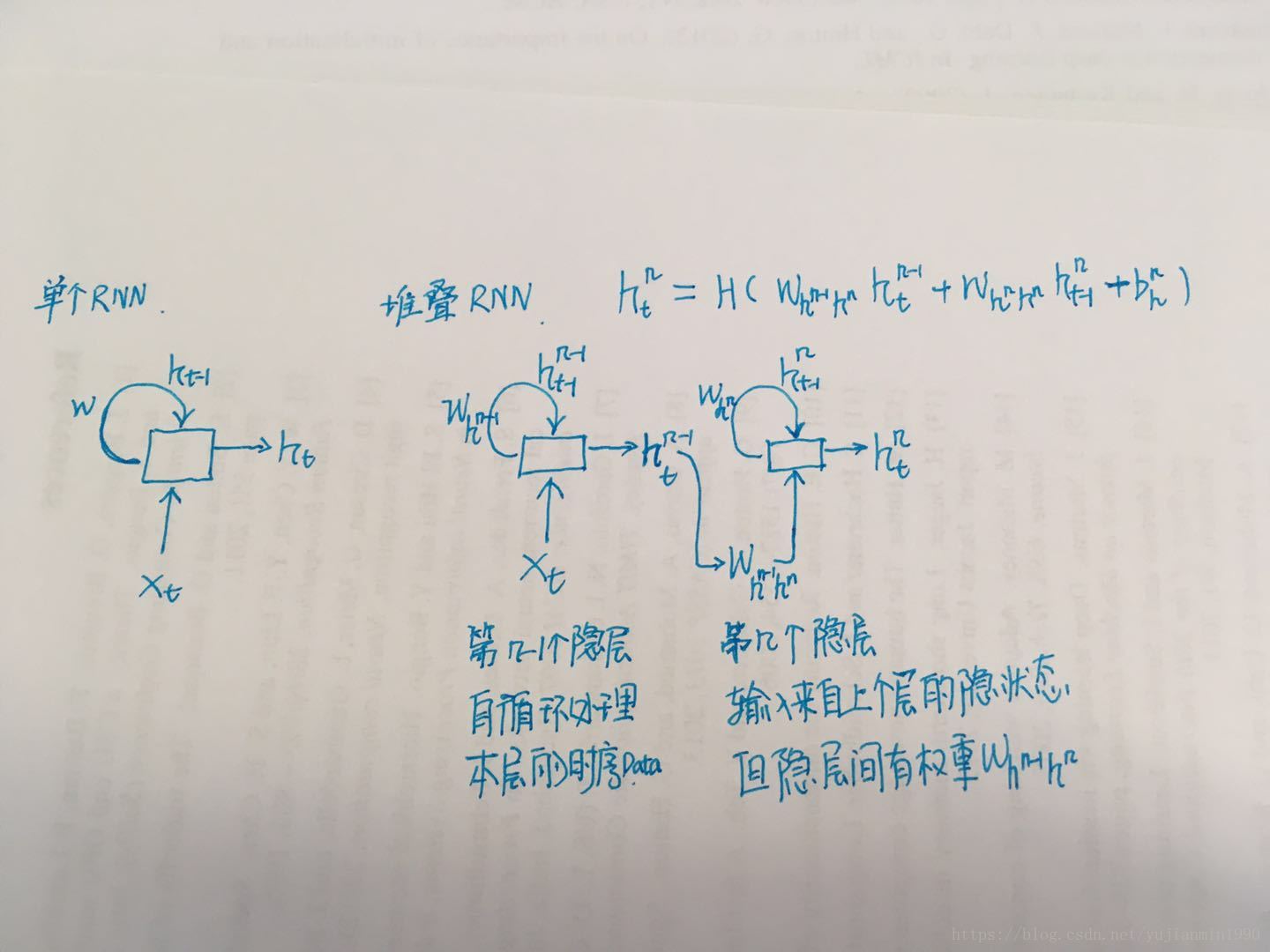
1)最基本的是堆叠RNN,在2013《Speech Recognition with Deep RNN》里解释过一句话:Deep RNNs can be created by stacking multiple RNN hidden layers on top of each other, with the output sequence of one layer forming the input sequence for the next,其中提出的Deep LSTM的模型。
RNN的堆叠构造空间的deep化,在1992-Schmidhuber《Learning Complex Extended Sequences Using the Principle of History Compression》年和1996 - Bengio《Hierarchical RNN for Long-term Depencdencies》年就有提出。堆叠RNN的图示如下:
2)另外RNN中的配件加大深度,是否也有不错的效果呢?
2014 , 《How to Construct Deep Recurrent Neural Networks》,在常见的堆叠RNN以实现空间Deep的角度之外,找到了不少可以将Shallow作Deep化的地方,并且在两个任务下测试性能不错。
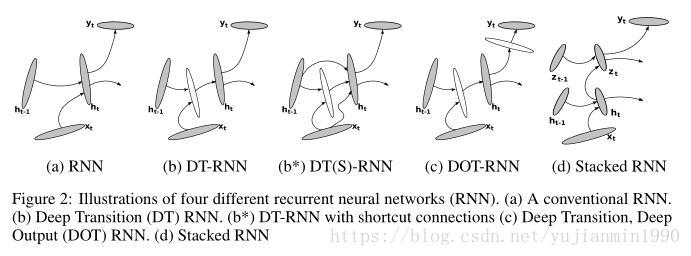
简单说明下上图:a ) 常规的RNN;b ) 是对隐状态流向下一个time-step时,替换线性映射为DeepNon-Linear映射;b* ) 是增加b的部分;c ) 又增加了输出时的深度;d ) 常规的堆叠RNN。
思考:多Memory-Cell和deep LSTM是一回事么?多MC指的是堆叠RNN。
notice: 在How to 这篇文章里有个明显地引用论文错误,“learning word embeddings (see, e.g., Mikolov et al., 2013a)”,这里引用对应的Distributed Representations of Words那篇文章,很明显不是用RNN来搞的Word Embedding,可能作者是想引用Mikolov的《RNN based LM》这篇文章。
Exploration Best RNN
google和Facebook的这帮好人们,已经帮大家测试了N种RNN的结构,来对比哪些更好使。号称是测试了10万种RNN结构,实际上是因为他们加入了好多随机结构变化,才有的这么个数量,不要被吓住了,实际上已有论文中发表过有效的RNN结构怎么可能会有这么多。
其中最重要的证明结果:
1) LSTM和GRU是最好的适用于大部分任务的RNN结构。
2) 同时发现在LSTM的遗忘门上添加个初始化值为1的bias,则能弥补与GRU的gap。【有使用LSTM,一定要加上这个技巧】。
3) 各组件的重要度:遗忘门对除了LanguageModel之外的其他任务上,是非常重要的;input-gate是非常重要的;output-gate是不怎么重要的。
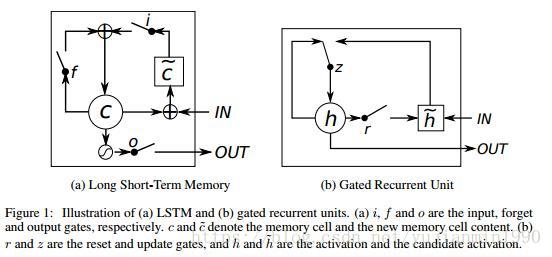
这篇paper里给出的LSTM和GRU结构图更容易匹配对应公式。
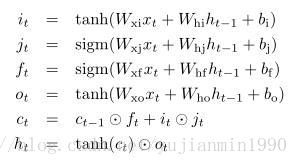
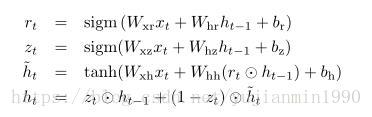
notice 1: 本文还通过随机组合发现了三种效果非常不错的RNN结构。
notice 2: 对遗忘门添加正Bias,早在2000年的 learning to forget那篇文章里就提出了。详细版3.1节的最后或者简略版的3节开始。
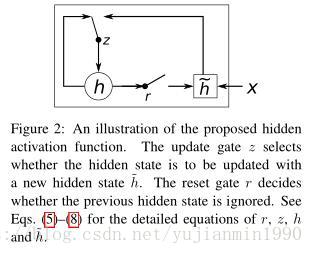
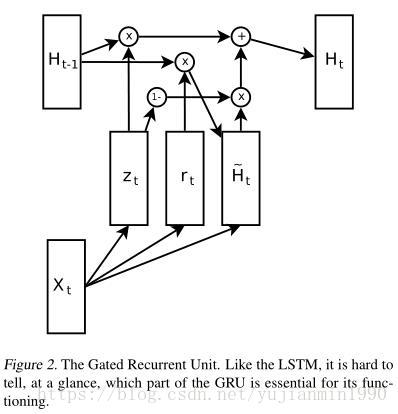
同年,还有篇类似的 探索paper,但仅限于GRU,其中有个图还是挺不错的,如下:
reference
- 《2015 - A Critical Review of Recurrent Neural Networks for Sequence Learning》建议重点阅读,虽然有点厚。
- 《2001 - A Guide to Recurrent Neural Networks and Backpropagation》
- 《1997 - Long short-term memory》超长,读起来很费劲
- 《2000 - Learning to forget: Continual prediction with LSTM》
- 《2000 - Recurrent nets that time and count》
- 《2014 - On the Properties of Neural Machine Translation: Encoder–Decoder Approaches》
- 《2014 - Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》这里是 GRU首次提出
- 《2013 - Speech Recognition with Deep RNN》
- 《2014 - How to Construct Deep Recurrent Neural Networks》
- 《2015 - An Empirical Exploration of Recurrent Network Architectures》建议重点阅读
- 《2014 - Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》