AR-CNN(Artifact reduction)
:只适用于JPEG压缩
四层全卷积层,没有pooling和全连接层,输入和输出是相同size。网络结构如下:
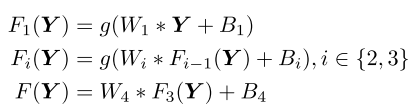
g()是非线性mapping函数,在AR-CNN中是ReLU函数,即
。AR-CNN的配置如下图所示:
4层卷积分别实现:特征提取(feature extraction)、特征加强(feature enhancement)、mapping和重构(reconstruction)的功能。
SRCNN(Super-resolution CNN)
:被设计用来取代HEVC中的deblocking和SAO。
一 、A Convolutional Neural Network Approach for Post-Processing in HEVC Intra Coding

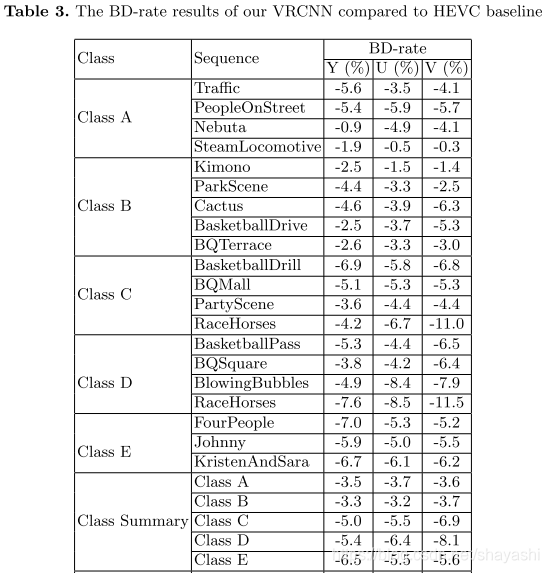
提出VRCNN(Variable-filter-size Residue-learning CNN)作为HEVC的后处理,替代去方块滤波和SAO,减少压缩出现的失真并且不需要额外的bit。网络结构和配置如下图所示:
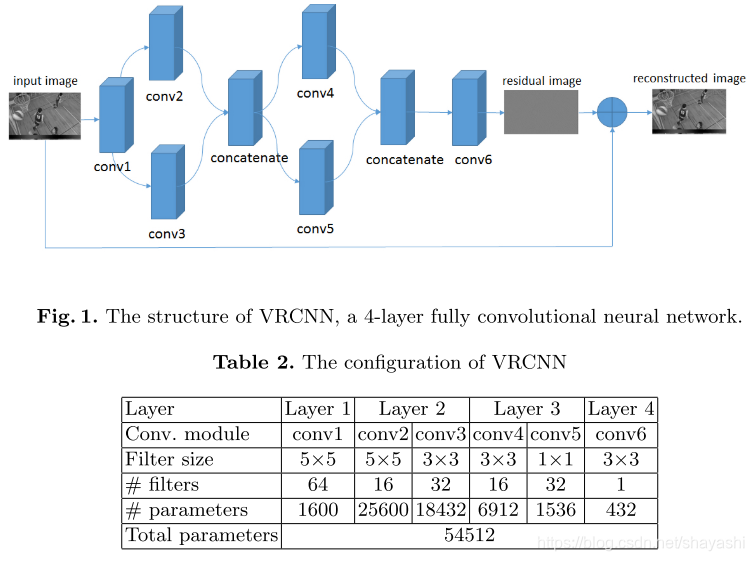
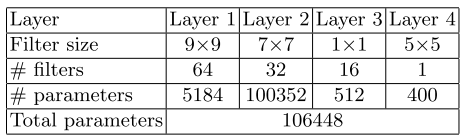
相比AR-CNN,因为JPEG变换和量化的单位block是固定大小的,所以每一层的卷积核是固定的。而HEVC实现多个block size的转换和量化,所以VRCNN在第二层采用可变的卷积核大小。同样,第三层实现两种卷积核大小是5x5和3x3的。第一层和第四层使用固定卷积核是因为这两层分别实现特征提取和最终重构的功能。
VRCNN采用残差学习技术(residue learning technique),最后一层的输出加上了输入,所以最终输出为:
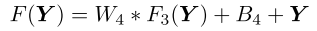
VRCNN的训练
:
损失函数为:
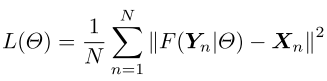
使用批量梯度下降算法。为了加快训练,采用了自适应梯度裁剪技术(adjustable gradient clipping technique),即如果学习率(learning rate)
很大时,将其投射到
范围内,预防梯度爆炸问题。
整合VRCNN到HEVC intra编码中,取代deblocking和SAO,可以提高视频质量并且不产生额外的bit。在卷积操作中,padding 0以使输入和输出size相同。
实现:
使用Caffe实现VRCNN,每个原始图像使用HEVC intra编码压缩,采用了4个QP值:22,27,32,37。只使用亮度分量测试,图像被裁剪成35x35的不重叠的子图像。一共有46784个训练样例。批量大小是64,动量参数(momentum)设为0.9,weight decay 0.0001。基本学习率设置为0.1到0.0001指数型衰减,每40周期变换一次。bias 学习率设置为0.01,0.01和0.1分别对应QP27,32和37。QP22使用27的网络参数微调,基本学习率为0.001,bias学习率为0.0001,40周期后结束。
实验结果: