CNN(Convolutional Neural Network)
卷积神经网络(简称CNN)最早可以追溯到20世纪60年代,Hubel等人通过对猫视觉皮层细胞的研究表明,大脑对外界获取的信息由多层的感受野(Receptive Field)激发完成的。在感受野的基础上,1980年Fukushima提出了一个理论模型Neocognitron是感受野在人工神经网络领域的首次应用。1998年,Lecun等人提出的LeNet-5模型在手写字符识别上取得了成功,引起了学术界对卷积神经网络的关注。2012年,Krizhevsky 等人提出的AlexNet模型在ImageNet图像分类竞赛中取得第一名的成绩,其模型准确度领先第二名11%。在AlexNet之后,VGG(Visual Geometry Group)、GoogLeNet、ResNet也相继被提出。
ANN简化依据
我们也可以用ANN进行图片分类。但是,在将ANN用于图片分类会导致模型参数过多。例如,训练的图片大小为100x100x3,第一层隐层的神经元数目为1000时,参数就达到3x107。因此,需要人们利用先验知识来简化ANN以达到减少模型的参数,而简化后的结构就是CNN。
ANN的简化依据:①对于一个神经元来说,并不需要连接图片的全局区域,只需要连接局部区域的信息来检测局部物体,如图1-1所示。

图1-1 整体区域与局部区域
②同一个物体可能会出现在不同图片的不同区域。如有的鸟嘴位置在左上角,而在另一张图片中间,如图1-2所示

图1-2 鸟嘴在不同的区域
③对图片进行子采样,不会对人对图片内容的理解产生太大影响。可以把图片的奇数行、偶数列的像素去掉,使图片变为原图片的1/4,但不影响我们理解图片内容,如图1-3所示。子采样可以减小图片大小继而减少模型参数量。

图1-3 图片子采样
CNN结构
卷积层(Convolution Layer)
卷积层主要进行卷积操作。我们先定义一个过滤器(也称作卷积核),其实就是一个矩阵(如图1-4所示)
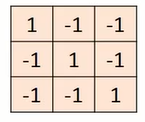
图1-4 过滤器
以图1-4和1-5为例,卷积操作就如图1-6所示。卷积操作就是过滤器跟过滤器覆盖的图片局部区域(如图1-5的红色区域)对应的每个像素先相乘后累加。假设过滤器上的每个像素值为fij,图片上被覆盖区域的像素为amn,那么卷积操作就是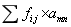
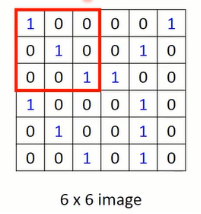
图1-5 image

图1-6 卷积操作
在完成卷积后,会挪动过滤器再进行卷积操作,挪动的距离称作步长(stride)。假定步长为1,则向右移动,如图1-7所示。单个过滤器在图片上完成卷积的动态过程如图1-8所示

图1-7 步长
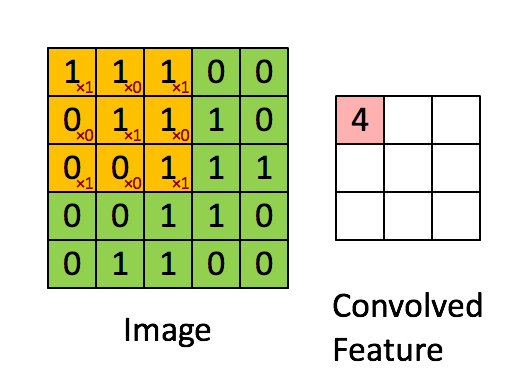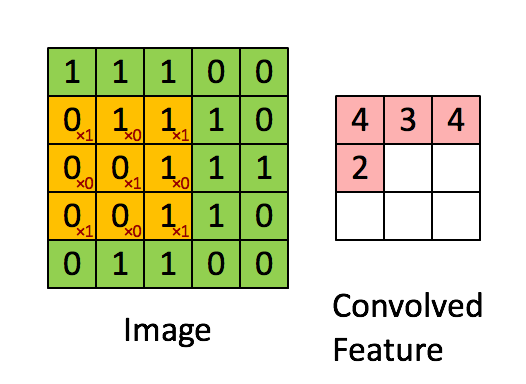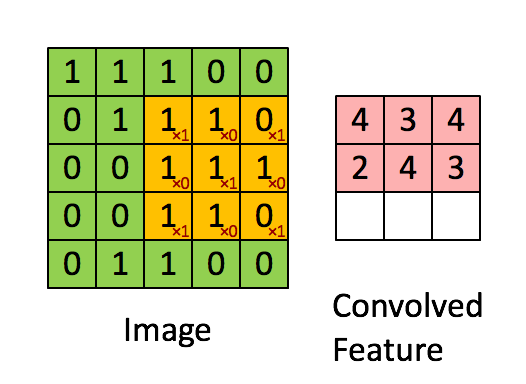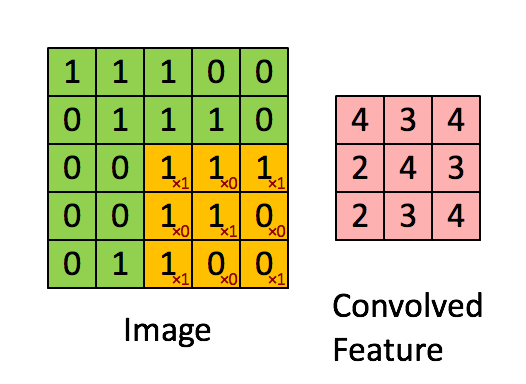
图1-8 完整的卷积操作
过滤器的卷积计算的作用在于如果有图片的局部区域跟过滤器比较相似,在进行卷积后的输出值会比较大,卷积后的值越大,就表明检测到对应物体。过滤器的大小只覆盖图片的局部区域,就对应“ANN简化依据①”;而在挪动过程中,过滤器是不变的,则可以检测不同区域上相同的物体,对应的就是“ANN简化依据②”。过滤器在挪动过程中对应的参数也就是不变的,因此也被称作权值共享。
多过滤器卷积操作
对于一个输入图片,我们可以设置多个过滤器来进行卷积。例如,我们使用5个过滤器来进行卷积,就得到5个相同大小的特征图。这些特征图会从新组合成为高度为5的图片,作为下一层卷积的输入。所以,卷积之后只会得到一个图片,图片的深度就是过滤器的数量。
池化层(Pooling Layer)
卷积层在完成卷积操作后会得到一个矩阵,这个矩阵被称作特征图(Feature Map)。池化就是将特征图分为若干区域,每个区域用一个值来进行表示。如图1-9,将特征图分为4个2x2区域,每个区域用最大值来进行表示(当然也可以采用均值,最小值等其他操作)。
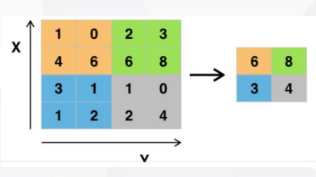
图1-9 最大池化操作
池化层的作用就是缩小特征图,得到一个更小的子图来表征原图。因此池化操作对应了“ANN简化依据③”。
参数训练过程
CNN的整个训练过程跟ANN并没有太大区别,都是利用BP来完成参数更新。但是,由于CNN中有增加权值共享这一特性,因此在更新的时候需要特别处理。如图1-10所示,在进行前向传播时,不同颜色的权重的值是一样的。但是在进行BP更新参数时,由于输入值不一样,因此计算出来的梯度也是不一样的。为了使所有不同颜色的权重值一样,可以分别计算出相同颜色的每一个权重的梯度,再取平均值。最后,让每一个权重更新同样的值就可以。

图1-10 权值共享
CNN各层的学习对象
CNN在图像处理上确实取得了成功,但是由于CNN的内部过于复杂,人们往往将CNN看做一个黑盒子。因此,我们还是需要去探究,CNN到底学习到了什么。
过滤器的检测对象
如何知道各层的过滤器在检测的对象?对于一个正常的流程,应该是我们输入一张图片,进行卷积后的输出值越大,说明过滤器就是在检测这个对象。因此,我们需要反推正常的流程。即在确定使输出值越大的前提下,去生成输入的图片。
过滤器经过卷积后的矩阵(如图1-10所示)的各个元素记作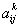 ,k表示第k个过滤器。评估函数为
,k表示第k个过滤器。评估函数为 ,求解的目标是
,求解的目标是 ,利用梯度上升就可以完成的求解。
,利用梯度上升就可以完成的求解。
图1-10 特征图
过滤器学习到的检测对象,如图1-11所示。每一个过滤器都会检测不同的对象,有些是竖线,有些是横线等。

图1-11 过滤器的检测对象
全连接层神经元的检测对象
我们可以利用跟过滤器检测对象同样的方法,生成出全连接层神经元的检测对象。如图1-12所示。跟过滤器的检测对象不一样的是,全连接层的神经元输出更像是全局对象,而不是检测局部对象。

图1-12 全连接层神经元的检测对象
输出层神经元的检测对象
当我们考虑输出层神经的检测对象时,采用跟过滤器检测对象相同的做法,得到的结果如图1-13所示,显然得到的结果非常糟糕,因为根本不知道生成的图片是什么。

图1-13 输出层神经元的检测对象
但是,你把1-13中的8作为CNN的输入,输出的结果会表示该图片是8。因此,深度神经网络似乎也不是那么智能,很容易被欺骗。为了让输出层神经元的检测对象看过去更像是一个数字,需要对评估函数做一些修改。对于数字而言,数字线条占总图片大小的区域并不是很多。因此,我们需要让生成的x*尽可能小。最终的评估函数为

跟原先的评估函数相比,其实就是多了L1正则化这一项。为么是评估函数值越大,L1就需要越小越好。新的评估函数会得到稍微更好的结果,如图1-14所示

图1-14 L1后的输出层神经元的检测对象
CNN的实际应用
Deep Dream
Deep Dream就是你给一张图片,然后机器会根据图片内容,增加机器看到的物体(效果图如图1-15所示)。Deep Dream的大致思想跟检测对象的做法是相似。

图1-15 Deep Dream效果图
Deep Dream的做法流程如图1-16所示,给定一张图片,获得图片的输出向量。对于输出向量,其中令正值越大,负值越小。这个做法就是要夸张化CNN所检测的对象。最后利用修改后的向量作为目标,来反向重新调整图片。
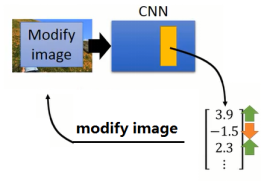
图1-16 Deep Dream大致流程
Deep Style
Deep Style是给定两张图片,一张是偏内容,一张是偏风格。然后,将两种图片进行“融合”,效果如图1-17所示

图1-17 Deep Style效果图
Deep Style的大致思想如图1-18所示,一个CNN提取图片的内容;一个CNN提取图片的风格,图片的风格主要体现在过滤器与过滤器输出值之间的关联性。则最终要构造的图片应该能使输出跟左边的内容很相似,且过滤器输出值之间的关联性跟右边的很相似。
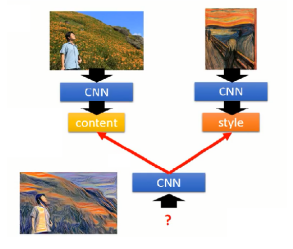
图1-18 Deep Style思想
Play Go
将CNN用在下围棋的话,则输入是当前棋盘就是,输出就是下一子的位置。对于整个棋盘,我们可以用(1,-1,0)代表(黑子,白子,无子)。而CNN之后以可以用来下围棋,原因在于将围棋的一些特性跟“ANN简化依据”相似。在围棋上,有时候并不需要全局的信息,而且这种局部信息可能会在棋盘的不同位置。但是,围棋不像图片,不能进行子采样。因此,将CNN应用于围棋时,应该去掉池化层。
图1-19 围棋
参考资料