NEURAL NETWORK BASED INTER PREDICTION FOR HEVC

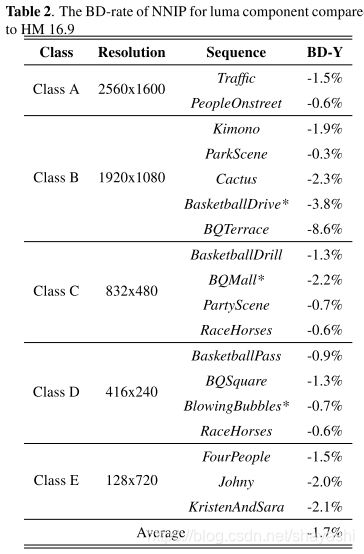
HEVC中的Inter预测只使用了时域信息,没有参考空域信息。作者提出一种网络结构NNIP(neural network based inter prediction)使用时域和空域进行提高Inter的质量,包含两个网络,一个全连接网络(FCN),一个卷积网络(CNN)。时域信息和空域信息作为FCN的输入,FCN的输出和经过Inter预测后的块作为CNN的输入,输出加强后的预测块。实验结果显示集成到HM16.。9,在low delay P配置下,能达到平均1.7%(最高为8.6%)的码率减少。
网络结构:
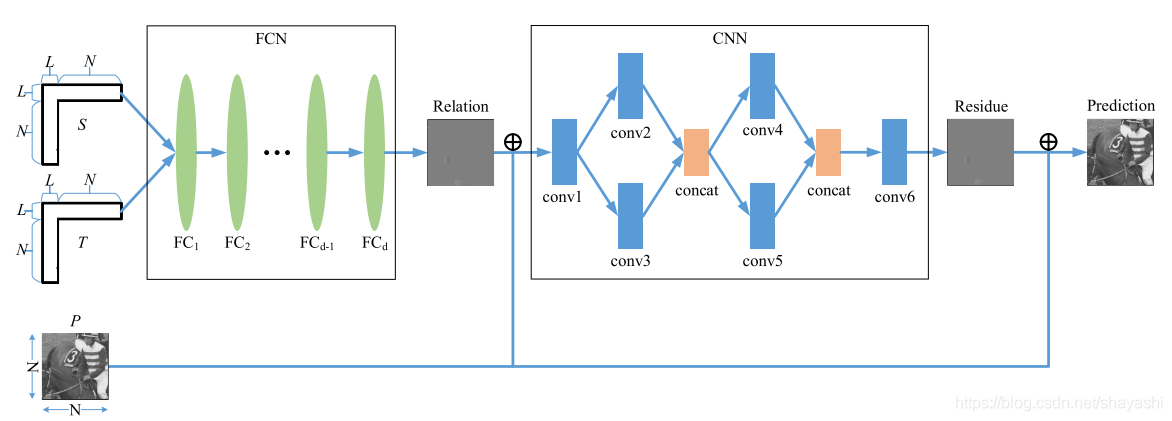
FCN
FCN的输入是时域临近像素T和空域临近像素S。如下图所示:
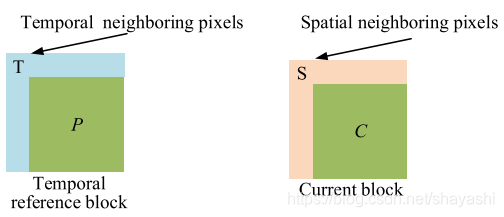
用Y表示FCN的输入,则网络表示如下图所示:
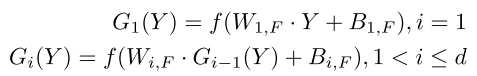
W是权重,B是bias,f是PReLU函数。第一层是
维,最后一层是
维,隐藏层K维,N是当前块的大小。
CNN
CNN的输入是FCN的输出加上预测块P。CNN使用VRCNN网络(可以参考我另一篇博文https://blog.csdn.net/shayashi/article/details/86606106)结构。网络表示如下图所示:
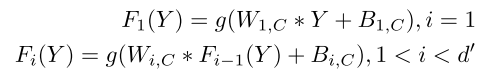
W和B分别是权重和bias。VRCNN使用残差学习技术,所以,最后一层表示如下:
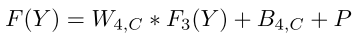
参数配置和VRCNN相同,如下表所示:
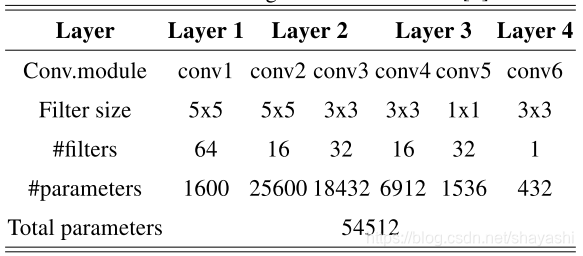
为了保证输入和输出相同,padding 0。
训练
训练数据生成
用
表示训练样例,
表示网络输入,包括S,T和P,
表示P的label,即当前块的原始图像。为了生成数据,首先使用HM16.9在low delay P的配置下,压缩BasketballDrive, BQMall, and BlowingBubbles三个视频序列,分别使用QP22,27,32,37。然后从压缩序列中提取
,从原始视频序列中提取
。
损失函数
均方误差MSE
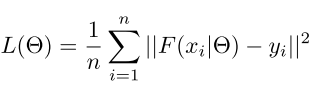
实现
使用Caffe,NVIDIA GeForce GTX 1080 GPU实现。使用Adam优化算法一阶梯度减少损失函数。批量大小是64。Adam的momentum设置为0.9,momentum2设置为0.99。FCN的d设置为4,K设置为输入的两倍。L设置为4。基本学习率设置为从0.1到0.001指数型衰减,没40周期改变一次,所以整个训练执行160周期。使用上述基本学习率训练QP=37的网络,其他QP值对应的网络使用37的微调,基本学习率为0.001。不同CU大小训练不同的模型,HEVC中CU大小为8x8到64x64,所以一共训练16个网络模型。
集成到HEVC中
NNIP用来提高inter预测质量,是在inter预测之后,结构如下图所示:
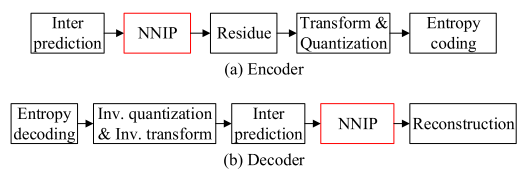
只有亮度分量经过NNIP的处理。NNIP算法是适用inter/merge/skip 2Nx2N模式。但是如果Inter预测已经足够精确,则再经过NNIP优化会出现质量降低的现象。所以设置一个CU级别的flag,用来标志是否使用NNIP。
实验结果
编码性能
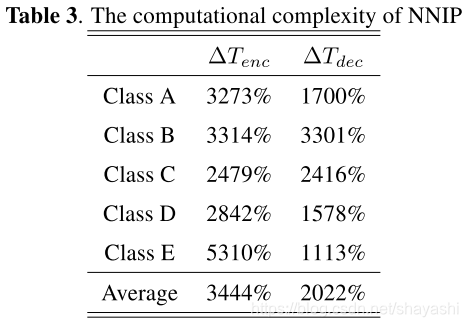
时间复杂度