论文阅读笔记:SSD: Single Shot MultiBox Detector
本文主要包含如下内容:
本篇论文针对图像检测提出了一种新的思路,提出的网络结构为 SSD。
主要思想
本篇论文提出了一种新的图像检测网络–SSD。即不生成 proposal 候选框,使用默认的候选框直接预测bounding box 坐标以及类别 object score 打分。
针对不同大小的物体检测,传统的算法均是将图像转换成不同的大小,然后送入网络进行检测,通过不同的感受野进行图像检测。本文提出的网络 SSD 结合了不同分辨率的特征图 feature map,处理多尺度图像,获得了依旧好的效果。
SSD 算法在训练的时候只需要一张输入图像及其每个 object 的 ground truth boxes。实现了端到端的训练。
对于300*300的输入,SSD 可以在 VOC2007 test 上有74.3%的 mAP,速度是59 FPS(Nvidia Titan X),对于512*512的输入, SSD 可以有76.9%的 mAP。相比之下 Faster RCNN 是73.2%的 mAP和7 FPS,YOLO 是63.4%的 mAP和45 FPS。即便对于分辨率较低的输入也能取得较高的准确率。
网络结构
基本的网络结构是基于 VGG16,在 ImageNet 数据集上预训练完以后用两个新的卷积层代替 fc6 和 fc7,另外对 pool5也做了一点小改动,还增加了4个卷积层构成本文的网络。
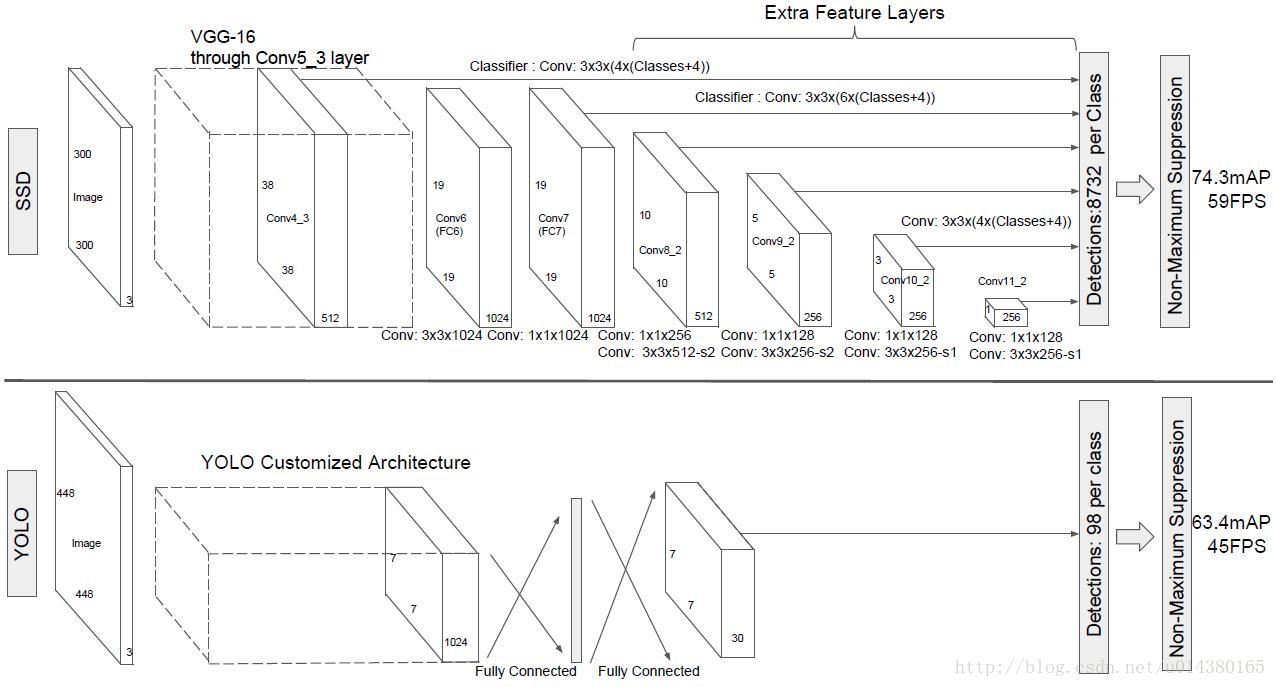
多尺度特征图 feature map
针对不同分辨率的特征图 feature map,SSD 网络分别对不同的特征图进行了检测。
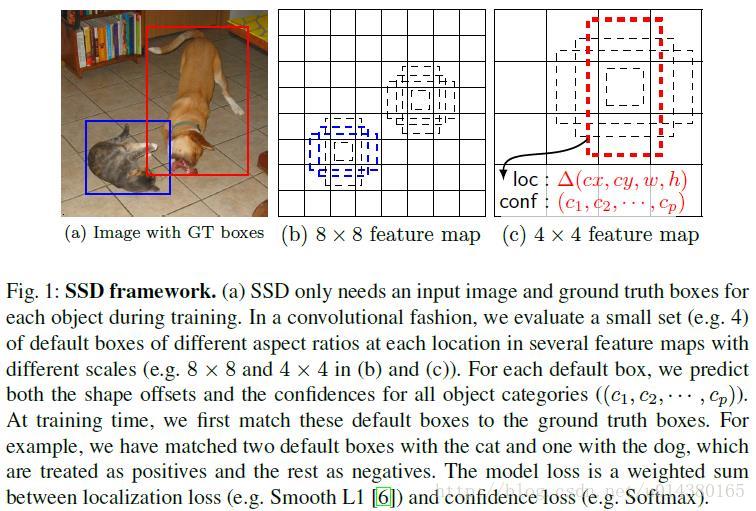
如图所示,对于8*8和4*4两种大小的 feature maps。feature map cell 为其中的每一个小格,feature map 的每个小格(cell)上都有一系列固定大小的 box,default box。
这里,我们假设每个 feature map cell 有k个 default box,那么对于每个 default box 都需要预测 c 个类别打分 score 和4个坐标偏移量 offset,那么如果一个 feature map 的大小是 m*n,也就是有 m*n 个 feature map cell,那么这个 feature map 就一共有(c+4)*k*m*n 个输出。具体而言,每个 default box 生成21个 confidence(这是针对 VOC 数据集包含20个 object 类别而言的)以及4个坐标值(x,y,w,h)。并且,论文实验表明 default box 的 shape 数量越多,效果越好。
在训练阶段,算法在一开始会先将这些 default box 和 ground truth box 进行匹配。所以一个 ground truth 可能对应多个 default box。在预测阶段,直接预测每个 default box 的偏移以及对每个类别相应的得分,最后通过 NMS 得到最终的结果。
匹配策略
首先,我们需要设定 default box 的 scale(大小)和 aspect ratio(横纵比),对于 m 个 feature map,对应的 scale 计算公式如下:
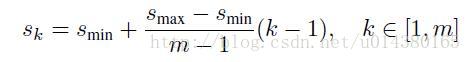
这里 smin 为0.2,smax 为0.9。同样的,论文设定 aspect ratio 为 {1,2,3,1/2,1/3},对于每一个特征图 feature map 而言,一共有6种 default box(注意,论文还额外增加了一种默认框)。可以看出 default box 在不同的 feature 层有不同的 scale,在同一个 feature 层又有不同的 aspect ratio,因此基本上可以覆盖输入图像中的各种形状和大小的 object!
在将 default box 和 ground truth box 进行匹配的时候,我们设定 default box 和 ground truth box 之间的 IOU 大于0.5,即认定该 box 为正样本,并根据硬样本 Hard negative,我们对所有 box 的置信度 confidence 进行排序,额定正负样本的比例为1:3,从而有效训练网络。

损失函数
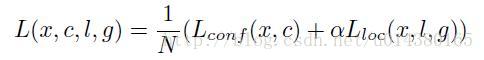
实验结果
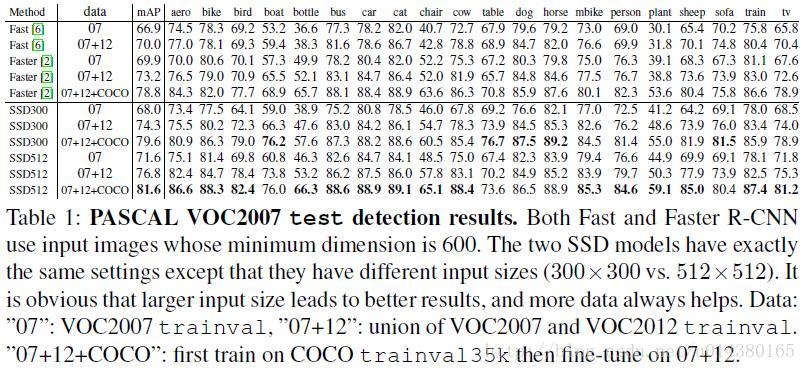
实验表明,数据集增加对于 mAP 的提升确实相当明显!同样的,对比检测网络 Fast 和 Faster,检测网络 SSD 均获得更好的结果。
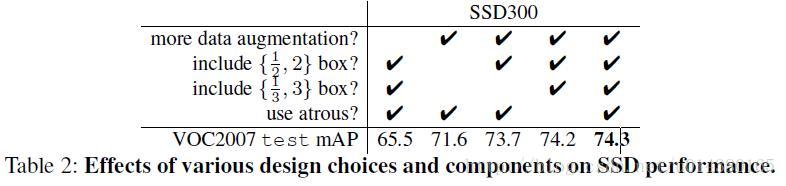
实验表明,通过对比各种设计方法说明所有方法均可以增加 mAP。

实验表明,融合不同层的特征是一种重要的方法,在这里主要解决了大小不同的 object 的检测问题。
实验表明,对比 YOLO 和 Faster RCNN,说明 SSD 速度快且准确率更高。
文中作者提到该算法对于小的 object 的 detection 比大的 object 要差。作者认为原因在于这些小的 object 在网络的顶层所占的信息量太少,所以增加输入图像的尺寸对于小的 object 的检测有帮助。另外增加数据集对于小的 object 的检测也有帮助,原因在于随机裁剪后的图像相当于“放大”原图像,所以这样的裁剪操作不仅增加了图像数量,也放大了图像。