版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/liangdong2014/article/details/83003866
SSD Single Shot Multibox Detector
Code: https://github.com/balancap/SSD-Tensorflow
- SSD 是ECCV 2016的文章,文章主要提出了一种新的framework来完成object detection任务。主要的特点是速度快,mAP也比较有竞争力。
- 文章的主要贡献
- 提出了SSD,它比当时最快的YOLO更快,而且相比于YOLO,它对accuracy的改进比较大。
- SSD的核心是针对固定规模的default bounding boxes (类似于faster RCNN 中的anchor)预测类别的得分和box的偏移量,通过给feature map后接小kernel的convolution layer来实现
- SSD还实现来不同scale的object的detection, 它通过在不同阶段的feature map后接convolution layer来实现
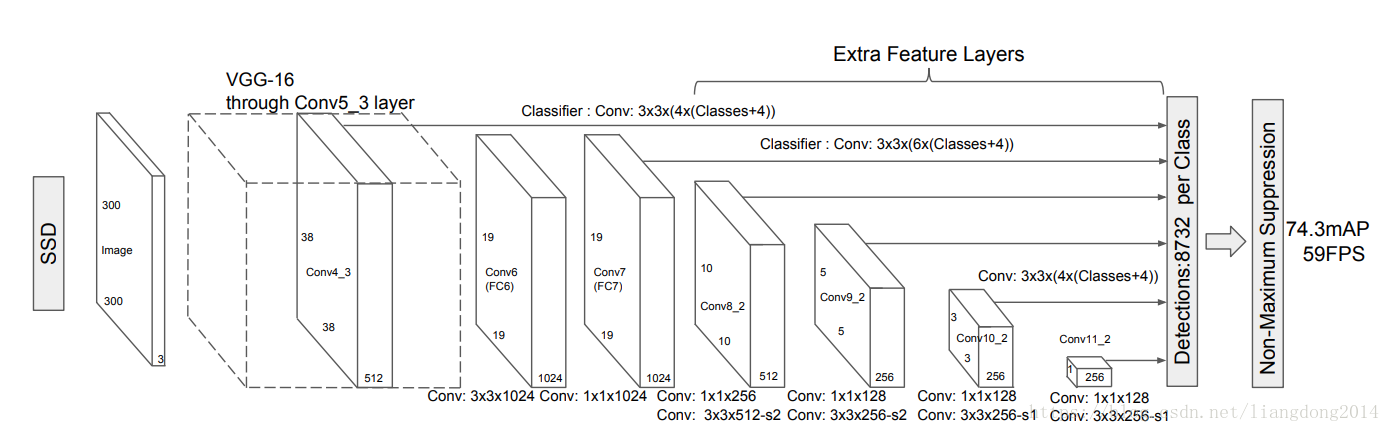
- 网络结构
- 前面的VGG16作为我们的base network,根据需要我们也可以将其更换成其他网络
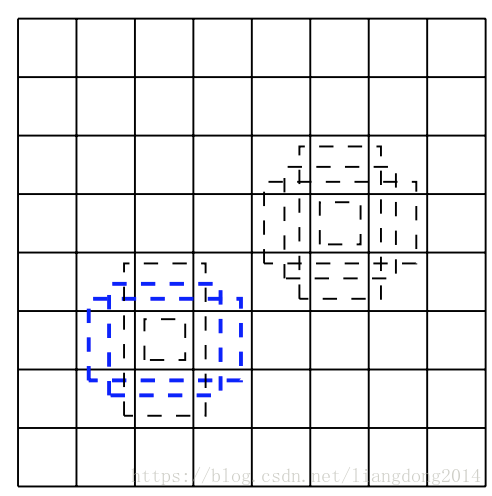
- 我们得到VGG16的feature map后,其为conv5_3 layer。feature map的大小为3838。我们针对每个pixel提取4个bounding box,其具有不同的大小和长宽比。比如下图所示。所以我们的output channel就是4(classes+4), 倍数4是因为有四个bounding box,括号里面的4是cx, cy, w, h.
- 图中所显示的8732个bounding box是如何得到的呢?38*38*4 + 19*19*6 + 10*10*6 + 5*5*6 + 3*3*4 + 1*1*4 = 8732。
- 得到8732个bboxes及其score后,我们再根据NMS算法进行合并排除,得到最后的预测结果。
- How to training
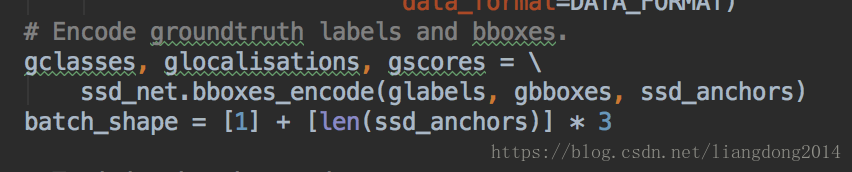
- 在关注如何训练这个问题的时候,我们最主要是关注怎样去计算ground truth。首先我们了解,我们训练的对象有两个:1、每个default bounding box的category;2、每个default bounding box对应的offset。所以,我们计算ground truth的目标也是这两个。
- 实现函数接口见下面的函数,在train_ssd_network.py中有调用。其中glabels就是一幅图片中每个bounding box对应的label, gbboxes是每幅图片中每个bounding box的坐标(x_min, y_min, x_max, y_max)。
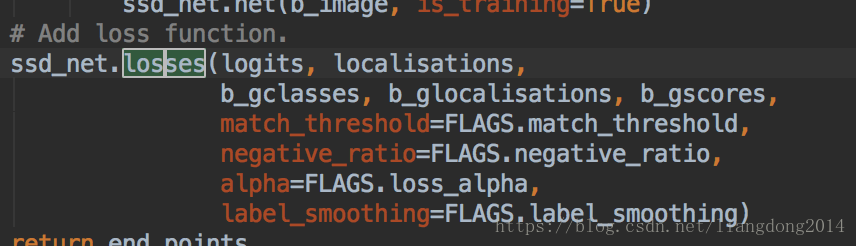
- 最后我们在计算交叉熵和smoothed L1 loss,其接口如下,也在train_ssd_network.py中有调用: