文章目录
摘要
本文建立了一个“无锚点特征选择模型”(feature selective anchor-free,FSAF),是一个简单有效的针对单目标检测的模块。
可以探入具有特征金字塔结构的单目检测器
FSAF模型打破了一般的基于anchor的目标检测的缺陷:
- 启发式引导特征选择
- overlap-based锚点采样
FSAF模型的一般机制:将在线特征选择应用于多级无锚点分支的训练
无锚点分支和特征金字塔的每一级都进行连接,允许在任意一级以无锚点的方式进行box的编码和解码。
训练过程中,动态的将每个实例分配到最合适的特征层
推理过程中,FSAF模型可以通过并行输出预测结果,而和基于anchor的分支协同工作。
本文使用无锚点分支的简单实现和在线特征选择机制来说明该过程
在COCO数据集上的实验结果展示出本文的FSAF模型比基于锚点的方法更快更好。
当和anchor-based分支协同工作时,FSAF模型在各种不同的设置下显著提高了基准RetinaNet的性能,同时引入了几乎免费的推理开销。
最优模型可以实现SOTA——44.6%的mAP,比其他单目检测器在COCO上的效果都好。
1. 引言
目标检测是计算机视觉领域的一项重要任务,是许多视觉任务的基础,如实例分割[12],面部分析[1,39],自动驾驶[6,20]等。目标检测的效果的提升很大程度上得益于深度卷积神经网络的发展[16.29,13,34]和优质的带标记数据集[7,23]。
目标检测的一个难点在于目标不可避免的尺度缩放,为了获得尺度不变性,SOTA检测器将特征金字塔或多尺度特征进行结合[24,8,21,22,19,38]。
多尺度特征图可以同时被生成。
为了将连续空间离散化而设计的anchor box可以将所有可能的实例框到一系列有限数量的盒子中,这些box有特定的尺度和纵横比。
实例框和锚点框的匹配基于IoU重叠率
当与特征金字塔进行集成的时候,大尺度的anchor box通常会和上层特征图相关联,小的anchor box通常会和底层特征图相关联(Fig.2)。
这是基于启发式的,上层特征图有更多的语义信息,适合于检测较大的实例,底层的特征图有更多精细的细节信息,适合于检测小的实例[11]。
将特征金字塔和anchor box结合起来的设计在目标检测方面获得了很好的效果[7,23,9]
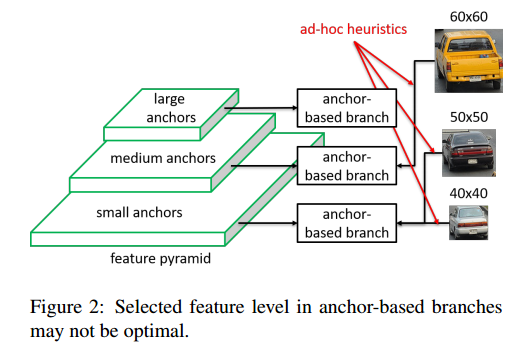
然而这样的设计有两个限制:
- 启发式指导特征的选择
- overlap-based 锚点采样
训练过程中,每个实例都要和最近的anchor box求取IoU,且anchor box是通过人为定义的规则来和特定的特征图层进行关联的(如框大小等)。所以每个实例的选择的特征层纯粹是基于启发式引导的。
假设一个像素大小为50x50的车,和另外一个像素大小为60x60的相同的车可能被认为成两个不同特征层,然而40x40大小的车就会被认为是和50x50的车是一个特征层。
也就是说,anchor匹配的机制是内在的启发式指导的,这样会导致一个主要的缺陷,即用来训练每个实例的选择的特征层可能并非最优的。
本文提出的简单且高效的方法是FSAF模型,同时解决了这两大缺陷。
动机: 要使得每个实例能够自由的选择最优层级来优化网络,故模型中不应该有anchor box来约束特征的选择。本文以无锚点框的方式对实例进行编码,以学习分类和回归的参数。一般过程如Fig.3。
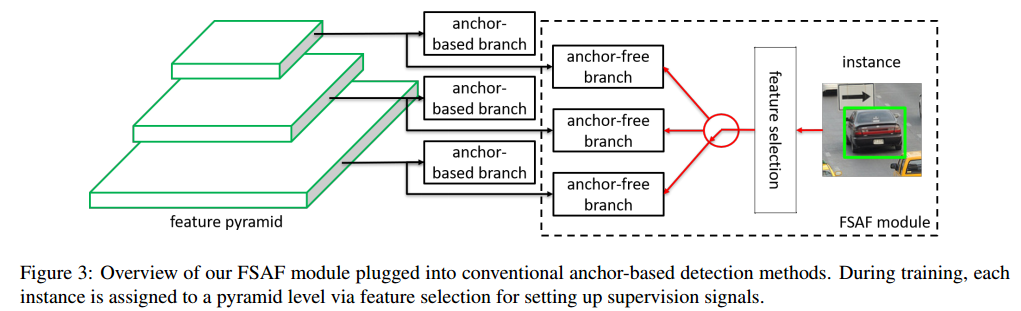
对每个特征金字塔层都会建立一个anchor-free分支,不依赖于anchor-based分支
类似于anchor-based分支,anchor-free分支由分类子网络和回归子网络构成。实例可以被分配到anchor-free分支的任意层中。
训练过程中,动态的基于实例内容对每个实例选择最合适的特征层,而不是只基于实例box的大小。之后,将选择的特征层用来学习检测所分配的实例。
推断阶段,FSAF模型可以独立运行或和anchor-based分支协同运行
FSAF模型对主干网络是未知的,且可以和特征金字塔结构结合起来被用于单目检测。
另外,anchor-free分支的实例化和在线特征的选择是多种多样的。
本工作中,我们保持FSAF模型的简单化,所以其耗费的时间相对于整个网络而言的开销是很小的。
在COCO数据集上的目标检测方法已经有很多,这为本文的方法提供了一定的比较性。
FSAF模型比anchor-based模型更快更好
当和anchor-based分支协同工作时,FSAF模型可以在保证最小计算成本的同时,在不同的主干网直接大幅提高基准。
同时利用ResNeXt-101的FSAF比RetinaNet提升了1.8%的mAP,只有6ms的推理阶段的延迟。
本文最终的检测器在使用多尺度测试时获得了SOTA——44.6%的mAP,比其他单目检测器在COCO上的表现都要好。
2. 相关工作
目前的目标检测器通常是实验特征金字塔或者多尺度特征塔作为通用结构。
SSD[24]结构首先提出了从多级特征中预测类别得分和b-box
FPN[21]和DSSD[8]的提出提高了所有层的底层和高层语义特征图。
RetinaNet[22]解决了具有焦点损失的多级密集检测器类别不均衡的问题
DeNet[19]设计了一种新的主干网络,来保证高空间分辨率在上层金字塔
这些方法使用预定义的anchor-box来编码和解码目标实例
其他工作则以不同的方式来处理尺度的变化
Zhu[41]提升了对小目标物体anchor的设计
He[14]将b-box看成Gaussian 分布来提升定位准确度
anchor-free的方法在目前是很新的
DenseBox[15]首先提出了一个统一的端到端的全卷积网络来直接预测b-box。
UnitBox提出了一种IoU损失函数来进行更好的box回归
Zhong等人[40]提出了基于区域提议的anchor-free网络来寻找不同尺度、纵横比和方向。
近期的CornerNet提出了将检测目标b-box当做一对corners的方法,获得了最好的单目检测结果
SFace[32]的提出将anchor-free和anchor-based方法融为一体
然而,这些方法仍然采取启发式特征选择的方法
3. Anchor-free特征选择模型
本节对本文的FSAF模型进行了实例化说明,展示了如何与特征金字塔结合起来应用于单目检测,正如SSD、DSSD和RetinaNet
我们将FSAF模型应用于现在最好的RetinaNet模型,并且逐步介绍设计过程:
1)如何在网络中生成anchor-free分支
2)如何对anchor-free分支产生监督信号
3)如何对每个实例进行特征层的动态选择
4)如何同时对anchor-free和anchor-based分支进行训练或者测试
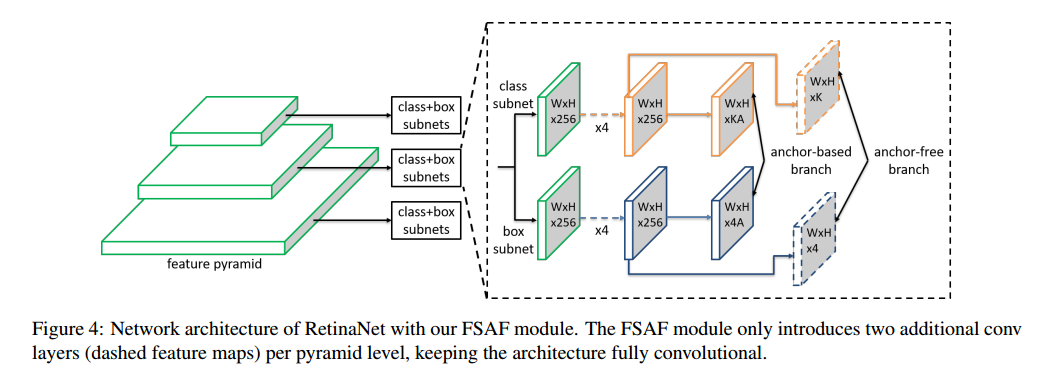
3.1 网络结构
从网络方面来说,本文FSAF模型是非常简洁的。
Fig.4 展示了将RetinaNet和FSAF模型结合起来进的结构
简而言之,RetinaNet是由主干网络和两个“特殊任务”的子网络组成的
特征金字塔是从主干网络的P3—P7中构建的, 是金字塔的层数, 层的特征图分辨率为输入图像的 ,图中只展示了三个不同的层。
金字塔中的每个层都被用来检测不同尺度下的目标,为了实现这个目标,分类分支和回归分支在 层进行了组合。这两个子网络结果都是小的全连接网络。
-
分类分支预测每个空域位置上的目标的概率,包括所有A个anchor和所有K个类别中的所有b-box。
-
回归分支预测4个数字组成的b-box坐标和离它最近的实例anchor的偏移量。
RetinaNet的顶部,FSAF模块为每个金字塔层引入两个额外的卷积层,Fig.4中虚线特征所示。
这两层分别在anchor-free分支负责分类和回归
为了更加有效,在分类子网络的特征图后连接了 个3x3大小的滤波器组成的卷积层,且级联sigmoid激活函数。对所有的K个目标类别的每个空域位置的目标都预测概率。
同样的,在回归子网络的特征图后也连接了四个3x3大小的滤波器组成的卷积层,且级联RELU激活函数[26]。对b-box的偏移做预测。
为此,anchor-free和anchor-based分支以多任务的方式联合工作,共享金字塔每个层的特性。
3.2 Ground-truth 和 loss
给定目标实例,我们已知其类别 和 b-box 坐标 ,其中 为box的中心, 为box的宽和高。
实例可以在训练过程中分配给任意特征层
定义投影的box 作为 在特征金字塔 上的投影, 。
同样将有效box定义为 ,占 的
将可忽略的box区域定义为 占 的
即:
且设定
Fig.5 展示了对于一个车生成 ground truth 的过程
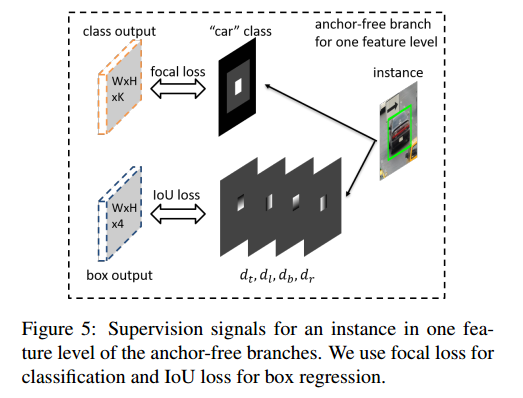
分类的输出:
classification output是一个WxHxK大小的feature map,K表示物体类别数,那么在坐标为(i,j)的点上是一个长度为K的向量,表示属于每个类别的概率。分支对应的gt是图中白色区域内值为1,表示正样本,黑色区域内值为0,表示负样本,灰色区域是忽略区域不回传梯度。分支采用Focal Loss,整个classification loss是非忽略区域的focal loss之和,然后除以有效区域内像素个数之和来正则化一下。
分类输出的真值为 个特征图,每个都对应一个类别
实例会在三个方面影响第 个真实特征图:
-
第一,有效框 区域是由“car”类特征图中白色框所表示的正区域,表示实例的存在
-
第二,被忽略的box将有效框 排除在外,也就是灰色区域,这意味着该区域的梯度不能被回传到网络中。
-
第三,临近特征层 如果存在忽略框,那么也会忽略区域
注意:如果同一层中的两个实例的有效框有重叠,那么更小的实例的框有更高的准确度。
GT中的剩余部分也就是负区域(黑色)将用零值填充,表示没有目标。
Focal loss[22]用来监督训练,超参数设置为
anchor-free分支的完整分类子网络的损失是所有为被忽略的区域的focal loss之和,用所有有效框区域的像素点之和做归一化。
Box 回归输出:
回归输出的真值是4个偏置值
实例仅仅会影响偏移特征图的 区域
对 内的所有位置 ,我们将投影框 表示为一个四维向量 ,其中, 分别表示目前位置 和 的上下左右的距离。
之后,在 位置上的跨越四个偏移映射的四维向量设置为 ,每个映射对应一个维度。 是标准化常数,设置为4。将 作为输出结果。
在有效框之外的位置都被设置为灰色区域,其梯度被忽略
IoU loss[36]被用来优化
anchor-free分支对一幅图像的回归总损失是,所有有效框区域的IoU损失的均值
推理阶段:
直接对分类和回归输出预测的框进行解码
对每个像素位置 ,假设预测的偏移是 ,则预测的距离是 。
预测的投影框的左上角和右下角分别为: 和
进一步,使用 对投影框进行缩放来获得图像的最终框
box的置信分数和分类可以由分类输出映射中的最大分数和对应的类别来决定
3.3 在线特征选择
anchor-free分支的设计允许我们使用人员金字塔层 的特征,为了选择最优特征层,FSAF模型基于实例内容选择最优的 ,而不是例如anchor-based方法中使用的实例框的大小来选择。
给定一个实例 ,定义在 上的分类损失和回归损失为 和 ,通过对有效框区域 的focal loss和IoU loss分别进行平均而获得:
其中, 是 区域内的所有像素点的和, 和 是在 上的 位置上的 focal loss 和 IoU loss。
Fig.6 表示了我们的在线特征选择过程,首先对实例
在金字塔的每个层进行前向传播。
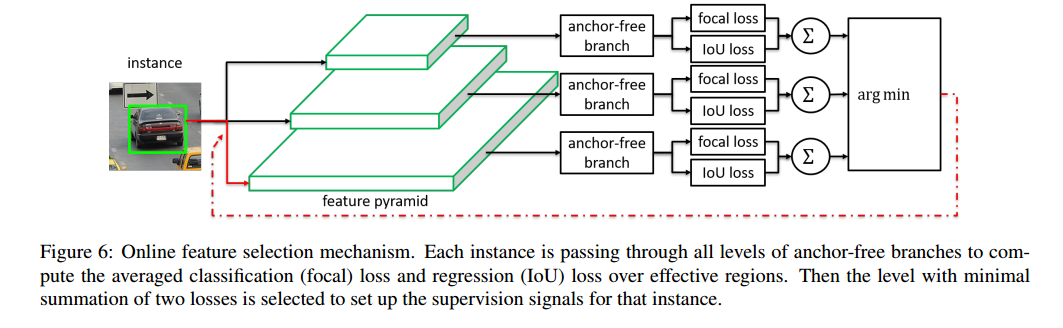
之后对所有anchor-free分支上利用公式(1)计算
和
的和。
最后,产生的损失之和最小的也就是最优的金字塔层 被用来学习实例:
对于整个训练batch,特征根据为其分配的实例而改变。选择的特征是目前最好的用于实例建模的特征。其损失在特征域形成最低的限制。
推理阶段,不需要选择特征,因为特征金字塔中最合适的层将输出最高置信得分。
为了证实在线特征选择的重要性,我们也在消融实验中使用了启发式特征选择的方法用于对比(4.1)。
启发式特征选择更大的依赖于box大小,仿照FPN检测器[21]的思想,实例 是通过如下方法分配给特征金字塔的 :
其中,224是典型ImageNet预训练大小,且 是目标层,该层中输入实例大小为
本文选择 ,因为RestNet[13]从第五个卷积层中使用该特征图,以进行最终的分类。
3.4 Joint 推断和训练
当将FSAF模块作为RetinaNet的一个子模块来工作时,FSAF模型和anchor-based分支共同工作,Fig.4所示。
我们将anchor-based分支当做最初的网络,所有的超参数在训练和推断的时候都没有改变。
推断:
FSAF模型仅仅给全卷积网络RetinaNet添加了少量的卷积层,所有推断层仍然像一幅图像简单的像图像从网络中前向传播一样。
对anchor-free分支,我们只解码每个金字塔层级中得分最高的1k个位置的预测框,然后使用0.05对其进行置信的分的选择。
这些从所有层中获得的得分较高的框和anchor-based分支获得的预测框进行融合,然后使用阈值为0.5的NMS来产生最终的检测结果。
初始化:
主干网络在ImageNet 1k[5]中进行预训练,我们利用[22]中初始化的方法来初始化RetinaNet。
FSAF模块中的卷积层,分类层的偏置为 ,权重是 的高斯分布,其中 定义为:训练之初,在 周围的每个像素位置输出对象的得分。且设置 。
所有的box回归层偏置都初始化为 ,权重是 的高斯分布,
这样的初始化有助于在网络训练前期更加稳定,避免大的loss
优化:
整个网络的损失是将anchor-free和anchor-based分支组合起来的。
令 表示初始RetinaNet的总损失, 和 分别表示anchor-free分支的分类和回归损失。
则总损失为
其中, 是平衡两个分支的权值,我们设置其为0.5。
整个网络使用SGD训练的方法在8个GPU上训练,每个GPU上两个图
除非特别说明,我们训练都是使用90k迭代次数,初始学习率为0.01,分别在60k和80k时将学习率降低10倍。
除非另有说明,否则水平图像翻转是唯一应用的数据增强。
权值下降率为0.0001,动量为0.9
4. 实验
本文在COCO数据集上进行实验,训练集是COCO trainval 135k,包括所有train 80k图像,和从val (40k)中随机选择的35k子集
使用在剩余的5k 的val中的数据构成的 minival 数据集进行消融学习的方法来分析本文的效果。
4.1 消融学习
对所有消融学习,我们在训练和测试中都使用大小为800像素的图像。
我们对anchor-free分支、在线特征选择和主干网络都进行评估,结果在表1和2。
anchor-free分支是必要的:
首先,训练两个检测器,都是仅有anchor-free分支,但分别使用不同的特征选择方式(表1的2和3)。说明了anchor-free分支仅仅能够达到较好的效果。
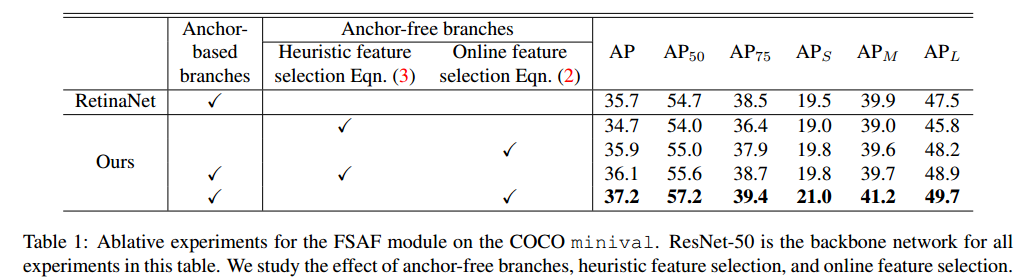
当FSAF和anchor-based分支协同工作时,anchor-free分支能够帮助学习到anchor-based分支难以学习到的实例,获得AP得分的增大。(表1的第5个)
尤其在使用在线特征选择时使 的得分分别提升了2.5%,1.5%和2.2%
为了寻找FSAF模型能够检测出来哪种目标,我们展示了和RetinaNet之间一些定量的对比分析,如Fig.7所示。
显而易见,FSAF模型在寻找有难度的实例上更加优异,如小的人物和目标,这些都很难用基于anchor的方法来找到。

在线特征选择是必须的:
如3.3节中所描述的,我们可以选择anchor-free分支或基于启发式的anchor-based分支,又或者基于实例内容来进行特征选择。
这些表明,选择正确的特征来学习在检测中起到很重要的作用
实验表明,anchor-free分支如果使用启发式特征选择方法(公式3),将不能和anchor-based方法相比较,因为学习的参数太少。
但是使用在线特征选择时(公式2),会可分参数的困难
另外,表1的4和5完全可以证实,在线特征选择对anchor-free和anchor-based方法的结合使用很重要。
最优特征如何选择:
为了理解为实例选择最优金字塔层的过程,我们可视化一些从anchor-free分支上获得的定性的检测结果,Fig.8所示。

类别之前的数字表示检测目标的特征层,这表明在线特征选择实际上遵循一种规则,就是金字塔上层选择大的实例,底层对小的实例进行响应,这和anchor-based方法的原理是一样的,
然而,这也有一定的例外,包括,在线特征选择的方法决定了选择金字塔层的过程不同于anchor-based选择层的过程。
我们将这些不同在Fig8中用红色标记起来,绿色框表示anchor-free和anchor-based相同的地方。
通过捕捉这些例外,可以证明FSAF模型可以使用更好的特征来检测有难度的目标。
FSAF模型是鲁棒且有效的:
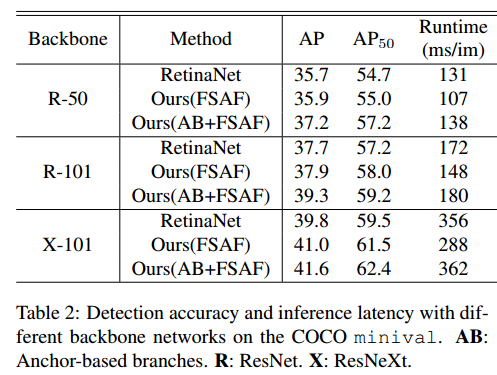
我们同样对FSAF模型所使用的主干网络所能达到的速度和精度进行了实验。
使用了三种不同的主干网络 ResNet-50, ResNet-101 [13] 和 ResNeXt-101 [34]
在Titan X GPU 使用CUDA 9 和CUDNN 7进行训练,batch size为1,结果再表2中。
可以发现,FSAF模型对不同的主干网络是有一定的鲁棒性的。
FSAF模型比 anchor-based 的 RetinaNet 效果更好也更快,
ResNeXt-101上,FSAF模型比anchor-based模型的 AP 高1.2%,快68ms
当和anchor-based网络协同工作时,FSAF模型也对效果提升起到了相当大的作用
这也表明,anchor-based模型并没有使得主干网络的能量完全发挥出来
此外,FSAF模型仅仅为整个网络引入了一点点的计算开销,基本上可以忽略
而且,我们使得使用 ResNeXt-101 的 RetinaNet 的 AP 提升了1.8%,且仅有6ms的延时
4.2 与目前效果最好的网络相比
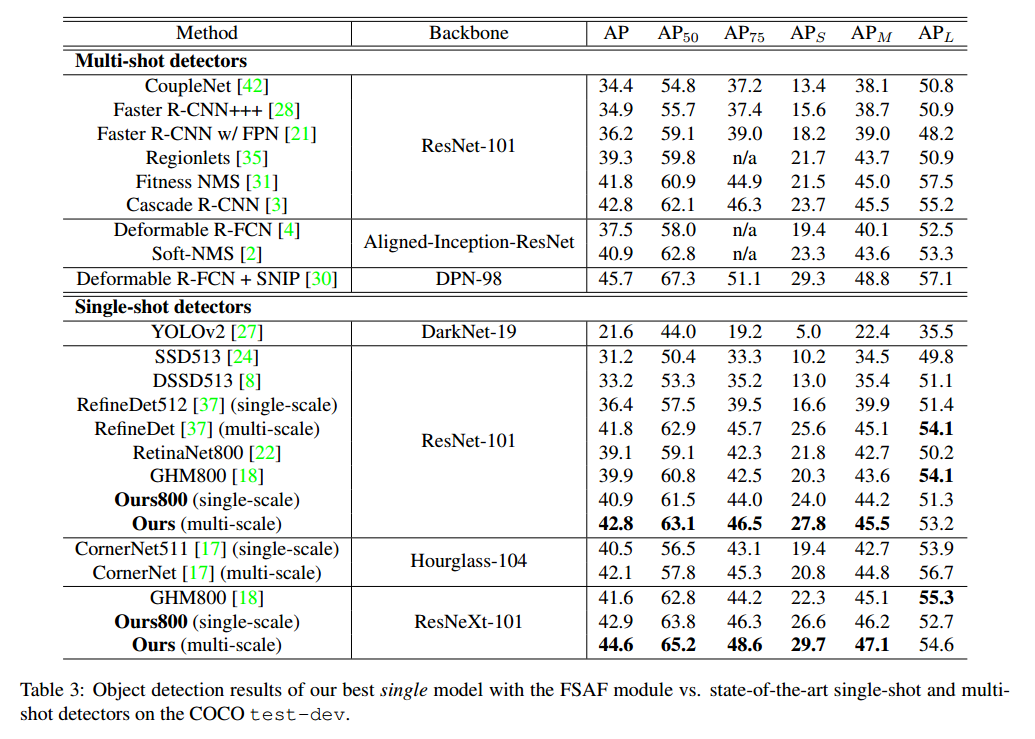
最好,在 COCO 的 test-dev 数据上进行了最终的检测实验,并和目前最好的网络进行了对比。
最终的模型是 RetinaNet + FSAF 的模型, 即 anchor-based分支加上FSAF模块
模型使用不同的尺度 { 640, 672, 704, 736,768, 800 } 进行训练,且是 4.1 节的模型长的 1.5倍。
实验包括单个尺度和多级尺度版本,其中单个尺度的测试使用像素大小为800的输入图像,多级尺度的测试数据增强,尺度分别为 {400, 500, 600, 700, 900, 1000, 1100, 1200},且对每个尺度进行水平翻转,后级联Detctron[10]。所有的结果都源于单个模型,并未融合。
表3展示了对比结果
使用ResNet-101作为主干网络,我们的检测可以在单尺度和多尺度都达到很好的效果。
使用ResNeXt-101-64x4d作为主干网络,使得AP提升了44.6%,比目前最好的单目检测器有了很大的提升。
5. 总结
本文工作证明了启发式的特征选择是 anchor-based 的单目检测方法的基本限制,为了跨越这个限制,我们提出了FSAF模块,使用在线特征选择方法在特征金字塔中训练 anchor-free 分支。
这提升了较小实例检测的基线,并获得了最好的单目检测效果。
