&论文概述

获取地址:https://arxiv.org/abs/1903.00621
&总结与个人观点
本文的工作将启发式的特征选取作为带有特征金字塔的anchor-based single-shot检测器的主要限制。提出应用了online特征选择来在特征金字塔上训练anchor-free分支的FASF模型。通过使用较小的推理开销实现对baseline极大的提升,同时在表现超过当前最优的single-shot检测器。
本文从一个新的方向出发来对网络的表现性能作出改进:通过寻找对应anchor的最优表现的特征层来做分类与回归,在使用FASF模块对一般的anchor选择模块进行替换时,mAP有着显著的改进,同时也对anchor-free以及anchor-based方法进行了融合。想法很新颖。
&贡献
1、提出使用anchor-free计算对应anchor能够获得最优表现的特征层。
&拟解决的问题
问题:使用特征金字塔时,用到启发式的anchor,在做回归与分类之前,会根据anchor的尺度将其分配到固定的特征层上进行,为了区分开相同位置不同尺度的目标。然而,这种启发式的方法,可能并不能将anchor分配到最优的特征层上。
分析:
当前使用的anchor近乎均为启发式的定义,固定的尺寸、固定的纵横比(在我看过的论文中除了Guided Anchor以及Meta Anchor方法,anchor-based方法几乎都是如此),之后应用到feature pyramid的时候,考虑到尽可能将不同尺度的anchor分开处理(提及使用到这种方法的数据集中区域重叠的目标的尺度基本上差距很大,因此可以通过这种方法,处理相同位置不同尺度的目标),简单地使用anchor的尺度将其分为对应的特征层上。
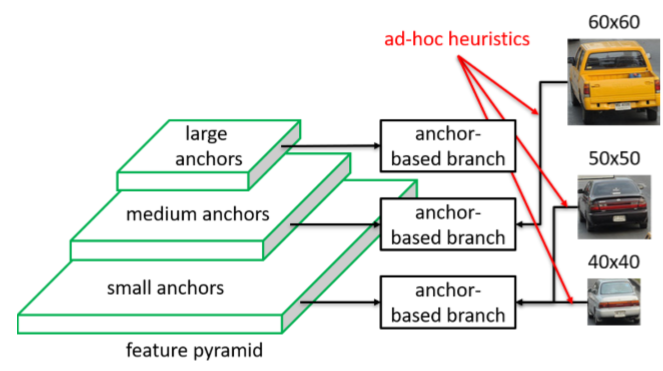
然而,这种将anchor直接划归的方法,可能并不会将anchor划归到最适合其分类及回归的层级。
因此提出的方法主要针对这个问题,考虑首先通过anchor-free的方法,根据某个评估标准,确定当前anchor可作辨别的最优特征层,然后将对应的anchor在该层级中使用anchor-based方法继续进行。
&框架及主要方法
1、Main Structure
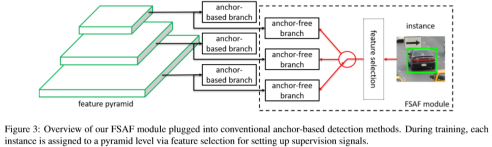
本文提出的主要框架,即是先将对饮给的object通过anchor-free分支计算出能够表现出其性能最佳的特征层,然后通过anchor-based分支继续进行分类及回归。
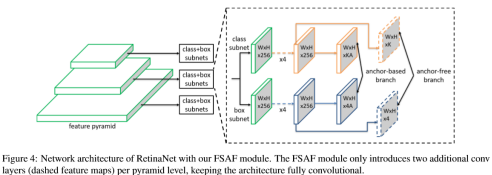
该图为在RetinaNet上使用FSAF模型的网络结构。对应的,通过anchor-based分支得到的分类结果的维度为W×H×KA,回归结果为W×H×4A,其中A为anchor的数量,K为总类别数;而通过anchor-free分支的分类结果为W×H×K,回归结果为W×H×4,因为在anchor-free分支上,是对每个点进行的预测,而每个点并没有固定的anchor数量,只需要分类与回归一次即可。
2、Symbol Define & Focal Loss
定义b = [x, y, w, h]表示一个ground truth bbox。使用feature pyramid后,对应的bbox转化为bpl = [xpl, ypl, wpl, hpl],其中l为对应的特征层级,P表示特征金字塔(eg: bpl = b/2l)。而其中采用一般的方法,根据w、h的比例来定义有效区域,忽略区域以及负样本区域,如:
bel = [xel, yel, wel, hel], bil = [xil, yil, wil, hil],其中wel=ϵewpl, hel=ϵehpl, wil=ϵiwil, hil=ϵihil.
分别表示有效框、忽略框的边界。在本论文中两个比例参数的设置分别为0.2与0.5。此外,每个实例对于忽略区域的处理也会扩展到相邻的特征层中,对应的(bil-1, bil+1)若存在也为忽略区域,且如果两个实例的有效区域在一个层级中出现重叠,则较小的实例有着较大的优先级。类别标签使用对应的GT的类别,如下图所示:
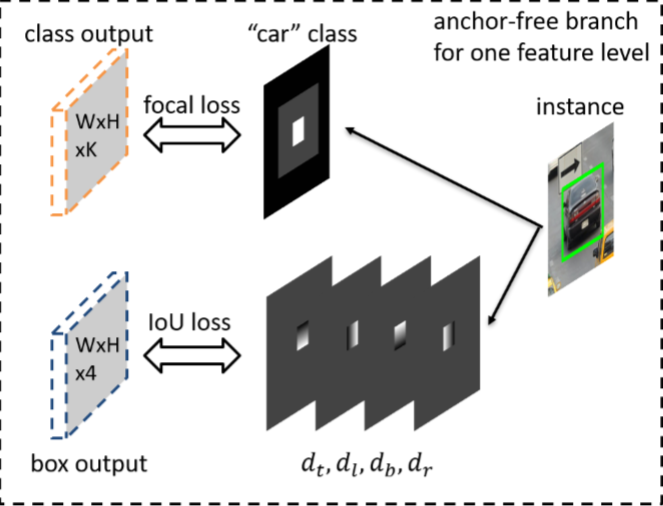
通过Focal loss计算分类损失,使用超参数为α=0.25,γ=2.0,总的分类损失为所有非忽略区域的focal loss之和,使用所有有效区域的像素点总数进行正则化。
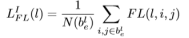
3、Regression & IoU loss
Groud truth的回归输出是4个类别不可知的偏移映射图。每个实例只影响偏移映射图中的bel区域,对于bel中的每个像素点(i, j),将bpl表示为4维的向量di,jl=[dti,jl, dli,jl, dbi,jl, dri,jl],分别表示bpl到上、左、下、右四条边的距离。然后在(i, j)位置的4维向量通过4个偏移映射设置到di,jl/S,S=4.0是一个正则化常量。

使用IoU loss计算回归损失,总的回归损失是有效box区域的IoU loss的均值。
4、Online Feature Selection
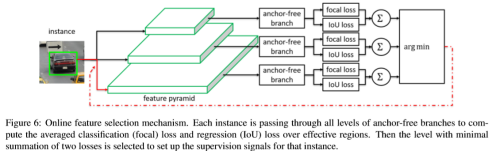
如上图所示,通过对每个层级中对应位置的loss计算,得到其中最小的作为对应anchor使用的最优的特征层。

5、Inference Setting
在inference阶段,对于anchor-free分支,在每个特征层上只考虑得分最高的最多1000个位置,且设置threshold为0.05。然后将结果与anchor-based分支的box预测合并,使用threshold为0.5的NMS得到最终结果。
6、Experiments
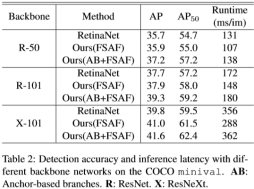
1) 消融实验,分别进行只有anchor-free分支、anchor-free及anchor-based结合、对于anchor-free分别使用启发式特征选择以及online特征选择的结果对比。在同等基础上,仅使用anchor-free效果会比最初仅使用anchor-based的结果略差,而使用了online特征选取,结果更优,对比后,使用anchor-free以及anchor-based两种方法结合性能更佳,同时,online特征选取比启发式特征选取的性能更优。

在不同的backbone上进行三者的性能对比,同样得到上述结果,此外,使用了两者结合的方法反而并不会对运行时间增加太多,相比于提升的精度可忽略。
2) 显示结果说明




在这里,截取了一些能够对于针对的问题进行相关反应的图片展示,每个识别结果前面的数字标号为对应在哪一个特征图中计算的。从第2张以及第4张图中,表现出来的差距更加明显,如果仅通过启发式地对anchor进行分配,那么在2中的skis更可能被分配到3th中,而4中,相同尺度的目标也是通过不同特征层中进行操作的。其中红色框为原先方法未识别。
&遇到的问题
1、为什么直接计算每个目标的Focal loss以及IoU loss之和的最小值可作为其最优的特征层?
&思考与启发
本文从一个新的角度来考虑anchor-free与anchor-based之间的关系,通过对anchor对应使用的特征层的选取以提升性能,也就是又找到了一个anchor-based方法的fault,在关注这个方向的问题时,不能只从一种方法的角度思考。