聚类分析与相关算法详解
聚类是一种无监督学习技术(包括 聚类,属性约减的 PCA),可以在事先不知道正确结果(即无类标签,或预测输出值)的情况下,发现数据本身蕴含的结构等信息
聚类的 本质是一种分组方法,分组的标准是 组内的样本之间相似度尽可能高,而 组间样本之间的相似度尽可能低
可将聚类理解为:对对象集合分组的过程
1 距离度量
1.1欧几里得距离定义
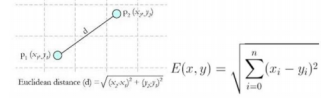
1.2其他距离度量的补充
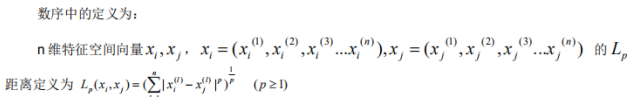
p =1 曼哈顿距离
p=2 欧几里得距离
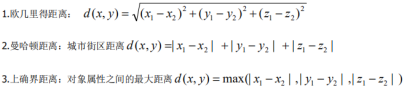
1.3余弦距离
余弦相似度也称为余弦距离
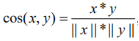
余弦相似度为1,则x,y之间的夹角为0度,此时两个向量完全一样,如果余弦相似度为0,则x,y之间的夹角为90度,说明两个向量不包含相同的词
1.4简单匹配系数
简单匹配系数度量的是最简单的二元属性(属性可以理解为特征)的对象(可以理解为向量)之间的相似性度量
所以要度量二元属性的对象,对象中的二元属性个数应该相同
假设x,y两个数据对象,都由n个二元属性组成,这样的两个对象做相似性度量可以生成四个量:

此时简单匹配数SMC的定义:

度量值不匹配的属性个数:

实例:
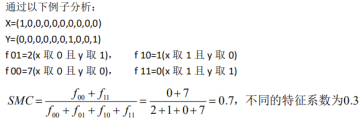
1.5jaccard系数
当分析购买商品数据时,由于未被购买的商品数量远远大于被其购买的商品数量,像上述的SMC计算公式会判断所有的事务都是类似的,所以引出jaccard系数来处理仅包含非对称二元属性的对象.

1.6海明距离
在信息编码中,两个合法(长度相同)代码(字符串/int/float类型)对应位上编码不同的位数称为码距,又叫海明距离

它的意义:就是将一个字符串替换成另一个字符串所需要替换的字符个数
它的作用:
用于编码的检错与纠错,为了检测d个1位错误,需要一个海明距离为d+1的方案.因为在这样的编码方案中,d个1位的错误不可能将一个有效码字改编成另一个有效码字.当接收方看到一个无效码字时,他就知道已经发生了传输错误.类似的为了纠正d个1位错误,需要一个距离为2d+1的编码方案,因为在这样的编码方案中,合法码字之间的距离足够远,因而即使发生了d为变化,则还是原来的码字离最近,从而可以唯一确定原来的码字,达到纠错的目的.
2 聚类问题
2.1非监督学习中的Kmeans算法
聚类属于非监督学习,无类别标签,基于原型的算法
原理就是相同类别的通过属性之间的相似性聚集在一起,算法中并未涉及类别标记的问题.
2.2K-means算法 --均值作为聚类中心点
CLustering中的经典算法,数据挖掘十大算法之一
算法接受参数K(在实际生产环境中一般根据业务经验设定),然后将事先输入的n个数据对象划分为k个聚类,得到的聚类满足:同一聚类中对象的相似性高,不同聚类中对象的相似度低
算法思想:
以空间中K个点为中心进行聚类,对最靠近他们的对象归类(这里用到了距离度量,度量之前要先对对象中的特征做特征工程使得特征值满足算法的需求).通过迭代的方法,逐次更新各个聚类中心的值(它是一个点,每一个对象都理解为一个点),直到得到最好的聚类结果(迭代之后K个聚类重心的值不再发生变化/或变化的范围小于设定的阈值)
变化的范围:当前聚类中的对象在经过一次迭代移动到其他组的个数的范围(暂时的理解)
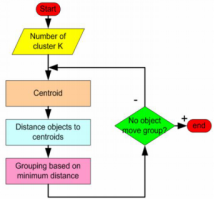
算法描述:
1.随机选取k个聚类重心(值)
2.在第j次迭代中,对任意一个样本,求其到所有k个聚类重心的距离(这里使用了距离度量),将该样本归到距离最短的那个聚类中心点对应的聚类中
3.训练完样本数据后得到k个聚类,利用均值等方法更新每一个聚类的重心(后面留意一下怎么更新的)
均值更新聚类中心点:
假如第n个聚类重心对应的聚类中有c个样本,每个样本中3个特征,把所有c个样本中的特征对应相加,然后除3,得到了更新之后的第n个聚类重心
4.对所有的k个聚类重心,如果利用2,3的迭代法更新后,各个重心保持不变(或变化的范围小于阈值),则迭代结束,否则继续迭代.
总结:
简单来说,K-Means是一种基于属性/特征将对象分类或分组为K的算法组数,K是正整数
K均值算法将会执行以下三个步骤,直到收敛
1.确定初始重心坐标
2.确定每个样本与重心的距离
3.根据最小距离对样本进行归类,更新聚类重心然后进行迭代
Means性能评价指标
一种度量K-Means算法的聚类效果的指标:误差平方和SSE(Sum of Squared Error)
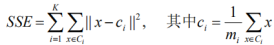
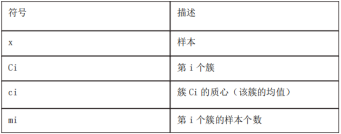
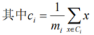 :表明用的是均值更新重心的方式,ci是每个聚类的重心
:表明用的是均值更新重心的方式,ci是每个聚类的重心
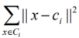 :一个聚类中,每个样本与重心的差的平方
:一个聚类中,每个样本与重心的差的平方
所以SSE求解的是:所有聚类的重心分别与对应聚类中所有样本差的平方和
直观的说SSE越小,表名样本越接近他们的重心,聚类效果越好,因为对误差取了平方,更加重视那些远离重心的点
可证明使簇的SSE最小的重心是均值:

在聚类算法的性能评价中,还有ARI指数(Adjusted Rand Index),值越接近1,性能越好
K-Means算法特点
优点:速度快,简单
缺点:最终结果与初始点的选择有关,容易陷入局部最优
K均值中的K是现实给定的,而这个K值的选取往往是根据业务经验选取的
K均值的聚类算法需要不断的进行样本的分类调整,不断的计算调整后的聚类重心,当数据量大的时候,算法开销很大
K均值是求得局部最优的算法,所以对于初始化时选取的k个聚类重心比较敏感,不同的重心选取策略可能得到不同的结果.
3 聚类的其他算法
3.1K-medoids聚类简介 --中位数作为聚类中心点
K-medoids选择数据集中有代表性的样本(而不是均值)来代表整个簇,即选取靠近中心点(medoids)的那个样本(中位数)代表整个簇
K-medoids的特点:
是对kmeans的改进,由于k均值对噪声,孤立点数据时敏感的,为了修改这种敏感行(距离矩阵的敏感行),将kmeans中的均值作为更新点,修改为聚类中位置最中心的那个对象,即中心点.
与kmeans的区别:
k-medoids中心点的选取限制在当前簇中所包含的数据点集合中.一个是数据样本的均值,一个是样本数据的中位数,两者的区别在于平均值的选取是连续空间中的任意值,后者只能在样本给定的点中选择
这样做的优势之处:
k-medoids不容易受到误差之类的原因产生离群点现象
k均值要求数据只能落在二维的欧式空间中,但并不是所有的数据都可以满足这样的需求,特别是类别型的变量用欧氏距离是无法适用的
存在的问题:
k-medoids:也会陷入局部最优解
K-medoids选取初值点需要枚举每个点,并要求他到所有点的距离之和,复杂度为O(N2),kmeans仅计算一个平均值,复杂度为O(N)
3.2层次聚类 --没有中心但点
上述的两种方式都需要手动的选取类的初始重心,层次聚类是一种树状的聚类算法,反复将数据进行分类和聚合,以形成一个层次序列的聚类问题,层次的基本方法可以分为:凝聚与分裂—这种方式没有重心
凝聚是由下向上构造树的方法,将每一个对象作为一个类,然后合并这些原子聚类为越来越大的聚类,直到所有的对象都在一个聚类中,或者满足某个终结条件(达到聚类数目)
分裂是由上向下的方法,它的策略是将所有的对象都置于一个聚类中,然后逐渐细分为越来越小的聚类,直到每个对象自成一聚类,或者达到某个结束条件
算法原理:
假设有N个待聚类样本,对于层次聚类来说,步骤:
1.(初始化)把每个样本归为一类,计算每两个类之间的距离,也就是各个样本之间的相似度
2.寻找各个类之间相似度最近的两个类,把他们归为一类(这样类的总数就少了一个)
3.重新计算新生成的这个类(均值?不是,后面会介绍)与各个剩下的类(旧类)之间的相似度
4.重复2,3直到所有的样本点都归为一类,结束
如图:
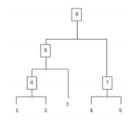
假设有5个待聚类样本,把每个样本归为一类(1,2,3,4,5),计算每两个类之间的距离,得到样本1,2是距离最近所对应的两个样本,将1,2归为一类(均值?不是,看后面的解答)得到类6,然后计算3,4,5,6之间的距离,得到类7,然后迭代下去最后将所有的类归为类9,迭代结束
迭代终止的条件:
1.所有的类都归为一类
2 .在第二步上设置一个阈值,当最近的两个类之间的距离大于这个阈值,则认为迭代可以终止
如何判断两个类之间的相似度(怎么求距离度量)有以下几种方法
1.SingleLinkage:又叫nearest-neighbor,就是取两个类中距离最近的两个样本(分别来自两个聚类)的距离作为这两个聚类的距离
这种方式容易造成一种叫做chaining的效果,两个cluster明明从”大局”上看离得比较远,但是由于其中个别点距离比较近就被合并了,并且这样合并之后的chaining效应会进一步扩大,最后会得到比较松散的cluster
2.CompleteLinkage:与SingleLinkage相反,取两个聚类中相互距离最远的两个点作为聚类之间的距离
这种方式两个cluster之间即使已经很接近了,但是只有有不配合的点存在,就顽固到底,老死不相合并.这两种相似度的定义方法的共同问题就是只考虑额某个特点得数据,而没有考虑类中数据的整体特点
3.Average-linkage:把两个集合中的所有点两两的距离全都算出来,然后求一个平均值作为两个集合的距离
4.average-linkage:取两个集合中所有点两两的距离的中值(中位数),与去平均值相比更加能够解除个别偏离样本对结果的干扰
基于原型的聚类 --层次聚类
优势1:它能够使得我们绘制出树状图(基于二叉层次聚类的可视化)
优势2:不需要事先指定簇数量
3.3基于密度的聚类(DBSCAN)
聚类中除了上述的kmeans的聚类属于基于原型的聚类,kmedoids是基于划分的聚类,另外还有层次聚类和基于密度的聚类.基于原型意味着每个簇都对应一个模型(模型是选取中心点的规则:如均值).
基于密度的聚类是基于距离的聚类的变型.纯粹的基于距离的聚类只能发现球状的分组,而在发现任意形状的簇上遇到了困难.
概念:
核心对象:如果给定对象E领域内的样本点个数大于等于设定的阈值,则称该对象为核心对象
直接密度可达:对于样本集合D,如果样本点2在1的E领域内,并且1为核心对象,那么对象2从对象1(核心)直接密度可达
&emsp==;密度可达==:对于样本集合D,给定一串样本点p1,p2…pn, 假如对象pi从pi-1直接密度可达,那么对象pn从对象p1密度可达(相当于密度直接可达的间接传递,简单的说就是p1虽然从对象pn直接密度不可达,但是密度可达)
密度相连:对于样本集合D中的任意一点2,如果存在对象1到对象2密度可达,并且对象3到对象2密度可达,那么对象1到对象2密度相连(密度可达的间接传递)
算法思路:
1.从数据中抽出一个未处理(还没有归类)的样本
2.统计该样本周围半径E范围内的样本数量,如果小于阈值,则该点为噪声点.回到步骤1继续处理.
3.如果大于阈值,则该点称为一个新簇的核心点,将所有从该点密度可达的点加入到当前新簇中.最后由一个核心对象和其密度可达的所有对象构成一个聚类
4.重复算法过程,直到所有样本都被处理
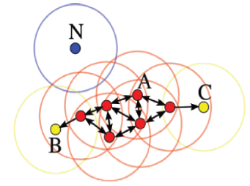

A点分别与B,C点密度可达
B,C点之间密度相连
DBSCAN算法的最大特点就是:
抗噪声干扰
可以发现任意形状的聚类
3.4高斯混合聚类
高斯混合聚类就是通过概率模型表示聚类原型,和K均值都是基于原型的聚类(假设聚类结构能够通过一组原型或模型刻画)
这块还没弄懂.
4 总结
在实际的应用中,对于给定的数据集,往往不太确定使用哪种算法是最为合适的,特别是面对难以或者无法进行可视化处理的高维数据集.另外,一个好的聚类算法并不是仅仅依赖与算法及其超参数的调整,相反,选择合适的距离度量标准和专业的领域知识在实验设定的应用可能很有用
5 API补充
5.1kmeans算法
from sklearn.cluster import KMeans
Parameters:
n_clusters:int类型,分类簇的数量 默认值为8
max_iter:int类型,最大迭代次数 默认值为300
n_init:int类型,指定K均值算法运行的次数
init:初始均值向量,取值为:”k-meas++”,”random”,an ndarray
precompute_distances:是否提前计算好样本之间的距离
tol:float类型,算法收敛的阈值 默认值le-4
n_jobs:int类型,指定CPU的数量, 为什么我的只能指定为1
random_state:设置了之后每次切分的数据内容是相同的
Attributes:
cluster_centers:给出分类簇的均值向量(重心)
labels_:给出每个样本所属簇的标记(0,1…)
inertia_:float类型,给出每个样本距离他们各自最近的簇中心的距离,然后求和
mehtods:
==fit(X,y)==训练模型
fit_predict(X,y);训练模型并预测每个样本点所属的簇,等价于先调用fit方法,再调用predict方法
predict(X):预测样本所属的簇
score(X,y):给出样本距离各个簇中心偏移量的相反数 是属性inertia相反数
5.2DBSCAN算法
Parameters:
eps:float类型,半径 用于确定领域大小
min_sample:int类型, MinPts:用于判定核心对象
metric:string or Callable类型,用于计算距离
algorithm:{“auto”,”ball_tree”,”kd_tree”,”brute”} ,用于计算两个点之间的距离找到最近邻的点
leaf_size:int类型,BallTree,KDTree树的参数,叶子节点的个数, 默认为30
random_state:保证每次run时对数据集切分后的内容与前面几次切分的都相同
Attributes:
core_sample_indices:核心样本在原始训练集中的位置
components_:核心样本点的一个副本
labels_:每个样本所属的簇标签
Methods:
fit(X,y):训练模型
fit_predict(X,y):训练模型并预测每个样本点所属的簇,等价于先调用fit方法,再调用predict方法
5.3层次聚类
from sklearn.cluster import AgglomerativeClustering
Parameters:
n_clusters:指定分类簇的数量 默认为2
affinity:string类型,用于计算距离 默认值”euclidean” 欧几里得
memory:用于缓存输出结果,默认不缓存
linkage:{“ward”,”complete”,”average”}, 表示使用哪种方式作为聚类之间的距离,默认值是”ward”
“ward”:SingleLinkage
“complete”:CompleteLinkage
“average”:Average-linkage:
Attributes:
labels_:每个样本的簇的标记
n_leaves:分层树的叶子节点数量 --横着
children_:一个数组,给出了每个非叶子节点的子节点数量 --竖着
Methods:
fit(X,y):训练模型
fit_predict(X,y):训练模型并预测每个样本点所属的簇,等价于先调用fit方法,在调用predict方法.