SPP-net同时解决了CNN要求输入固定尺寸图片的限制以及R-CNN速度的限制。
Introduction
CNN要求固定尺寸图片,一般的解决办法都是通过crop或者warp,前者会损失图片内容,而后者会导致图片扭曲。那么为什么CNN需要固定输入图片的尺寸呢?主要是因为全连接层,全连接层上参数的数目是固定的,因此要求输入特征维度也是一定的,卷积过程中特征维度是不会改变的,因此我们只能通过固定输入图片的尺寸来确保全连接层的输入特征维度完全一致。
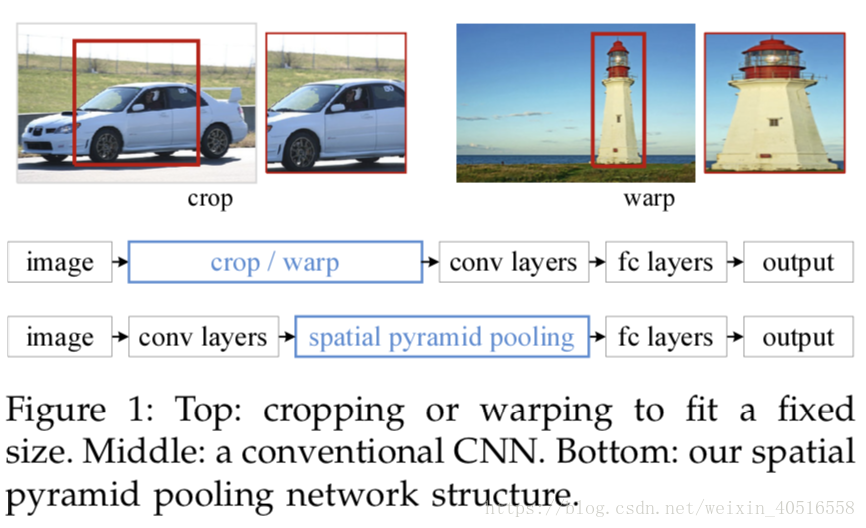
本篇文章通过引入spatial pyramid pooling层来移除CNN对于固定输入图片尺寸的限制。SPP层的位置被放置在最后一个conv layer之后,fc layer之前,SPP可以在任意大小输入的情况下,生成固定长度的输出。
卷积层和特征图
全连接层要求输入的长度是固定的,而卷积层的输出和输入的长宽比是大体一致的,我们称这些输出为特征图,他们不仅包括strength of the responses,还包括对应的空间位置。详情见下图:

空间金字塔池化层
文章中反复提到了Bag-of-Words方法,在cv中Bag-of-Words中的words指的就是一张图片上的特征。一般的步骤包括特征检测、特征描述和codebook生成。SPP方法相较于BoW的优势在于,它可以通过在局部空间的bins上进行池化而保留空间信息。这些空间上bins的大小同图片的大小成比例。因此无论图片多大,bins的多少是固定的。而滑动窗口池化的数量就不是固定的了,他取决于输入的大小。
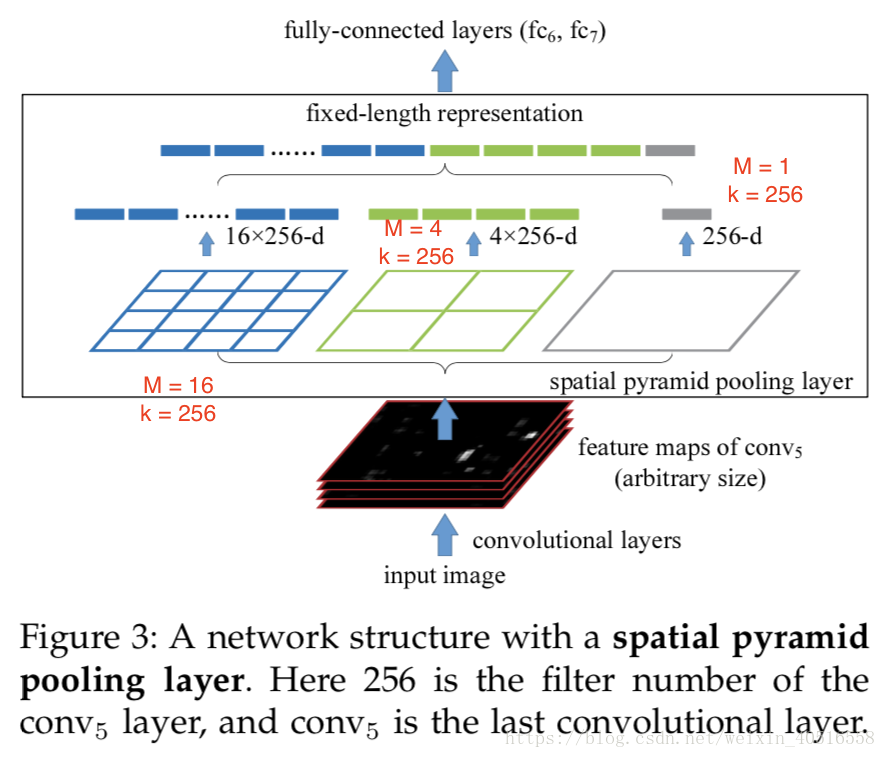
在每一个空间的bin(即图中的小方块)上我们用池化提取出每个滤波的响应(文章中使用的方法是max-pooling)。SPP的输出是kM维的向量,其中k代表上一个卷积层的filter的数量,M代表bin的个数。随后这些向量会被输入到全连接层中。
训练网络
作者提到理论上来说以上提到的网络结构可以用标准的BP进行训练,而无论图片输入大小如何。但是在实际操作GPU的过程中,我们最好在固定大小的输入图片上进行。
Single-size training
作者首先考虑的是从原始图片中切分出224x224的固定大小的图片作为网络的输入,cropping的目的是进行数据增强。对于一张固定大小的图片,可以计算出空间金字塔池化所需要的bin sizes。考虑一个conv5之后输出的特征图,他的大小为axa(比如13x13)。对于一个水平为nxn个bins的金字塔,通过一个滑动窗口池化来实现,窗口大小为 向上取整(a/n),步长为 向下取整(a/n)。水平为l的金字塔拥有l个SPP layer。接下来的全连接层将会将这l个输出连接起来。下图显示了一个3水平的金字塔池化(3x3,2x2,1x1)。

single-size training的主要目的在于实现多水平池化。
Multi-size training
作者考虑了两种大小的图片224x224以及180x180。作者选择将224x224的图片resize为180x180,而非crop,这样保证了图片之间只是resolution上的不同,而在内容或者排布上不存在什么差异。为了接受180x180大小图片的输入,作者又训练了180x180的网络。同以上计算过程类似,这次conv5得到的特征图大小为10x10。可以发现180-network和224-network的SPP的输出长度是一样的。所以这两个网络的参数就一模一样。话句话说在训练的时候,作者就实现了不同大小图片输入同时共享参数的效果。
从一个网络跳转到另一个网络这样实在有点麻烦,因此作者选择的方式是,在一个网络上训练一个完整的epoch之后,再跳到另一个网络训练下一个完整的epoch,这样一直迭代。
值得注意的是,以上两种方式只用于训练过程中。而测试时的输入为任意大小的图片。
在ImageNet 2012 分类数据集上的实验
multi-level pooling 提升准确率
对输入图片的处理为首先进行resize,使得短边为256,然后从图片的中心或者四个角进行crop,crop出大小为224x224的块。数据还会进行水平翻转和颜色转换。
multi-level的pooling的gain主要是因为level变多,参数也相应地增加;以及它会对variance(比如物体形变和空间排布)更加的稳健。
multi-size training 提升准确率
full-image representation 提升准确率
在这种情况下,我们只将图片的短边变成256,同时保持图片的长宽比。结果发现准确率得到了提升。这意味着保持完整图片内容是很重要的。
multi-view testing on feature maps
在测试阶段,作者将一张图片的短边resize为s,然后计算整张图片的特征图。为了使用翻转的view,同时还计算了翻转后的图片的特征图。给定任意一张图片上的view(window),作者将这个window对应到特征图上(具体对应方法作者写在了附录中),然后用SPP对这些特征进行池化。一般用10个view,即(4 + 1)*2,4即为上下左右四个角,1为中心位置,2为翻转。作者发现直接在特征图上crop和直接在原图上crop的top-5错误率在0.1%之内。
Appendix A
Mapping a Window to Feature Maps
作者的方法是,将window的corner point映射到特征图上去。这样的话,图片上的corner point就离特征图上的感受野的中心很近。当遇到存在padding的卷积层以及池化层时,mapping变得更为复杂。为了简单起见,如果一个layer的filter数量为p,那么就padding 向下取整(p/2)个像素。那么对于一个在(x', y')处的响应,它在图片上的有效感受野位于(x, y) = (Sx', Sy'),其中S是所有之前步长的乘积。给定一张图片上的window,我们将左(上)边界的映射定义为x' = 向下取整(x/S)+ 1, 将右(下)边界的映射定义为x' = 向上取整(x/S)+ 1。