池化作用
(1) 增大感受野
感受野就是一个像素对应的原来特征图的区域大小,假设最后一层特征图大小不变,在某种卷积setting下,要想看到原来大小为224*224的图像,就需要很多卷积层。而使用pooling也可以达到增大感受野的目的。
(2) 实现不变性
其中不变形性包括,平移不变性、旋转不变性和尺度不变性。由于pooling对特征图进行抽像,获取的是某个区域的特征,而不关心具体位置,这时当原来的特征图发生轻微的变化时,不影响最后的结果。
(3) 容易优化
降维、去除冗余信息、对特征进行压缩、简化网络复杂度,没有参数,容易优化,减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合。
(4)实现非线性
池化分类
(1) 一般池化
-
平均池化 (average pooling):计算图像区域的平均值作为该区域池化后的值。
保留整体数据的特征,能凸出背景的信息,平均池化中激活的贡献相等,可以显著降低整体区域特征强度。GAP指的是全局平均池化 -
最大池化(max pooling):选图像区域的最大值作为该区域池化后的值。
函数的反向传播可以简单理解为将梯度只沿最大的数回传。因此,在向前传播经过池化层的时候,通常会把池中最大元素的索引记录下来(有时这个也叫作道岔(switches)),这样在反向传播的时候梯度的路由就很高效。
保留纹理上的特征,但可能过度失真。
丢弃大部分激活会带来丢失重要信息的风险 -
随机池化:只需对feature map中的元素按照其概率值大小随机选择,即元素值大的被选中的概率也大
这种随机行挑选尽管有概率倾向,但它是人为叠加上的,无法总是保证一定随机的概率选择中能够选择到更好的结果,所以也会出现更糟糕的结果的时候,不过加入概率算法好处是,它为产生更好的结果产生了可能,所以总的来说,还是有可能得到更好的结果的。 -
*SoftPool
用SoftPool替换原来的池化操作可以带来1-2%的一致性精度提升。基于softmax加权方法来保留输入的基本属性,同时放大更大强度的特征激活权重与相应的激活值一起用作非线性变换。较高的激活比较低的激活占更多的主导地位。因为大多数池化操作都是在高维的特征空间中执行的,突出显示具有更大效果的激活比简单地选择最大值是一种更平衡的方法。
步骤:- 计算权重 W i W_i Wi
w i = e a i ∑ j ∈ R e a j w_{i}= \frac{e^{a_{i}}}{\sum _{j \in R}e^{a_{j}}} wi=∑j∈Reajeai - 为所有邻域内激活值加权求和
a ~ = ∑ i ∈ R w i ∗ a i \tilde{a}= \sum _{i \in R}w_{i}*a_{i} a~=i∈R∑wi∗ai
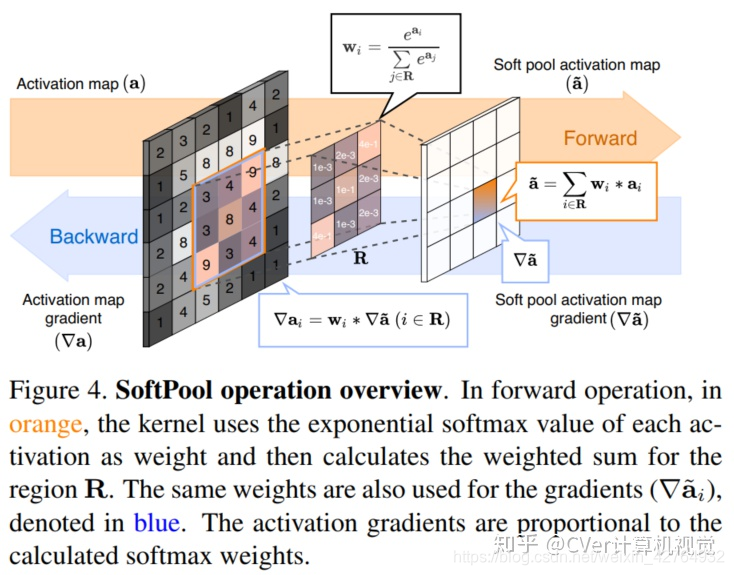
- 计算权重 W i W_i Wi
def soft_pool2d(x, kernel_size=2, stride=None, force_inplace=False):
if x.is_cuda and not force_inplace:
return CUDA_SOFTPOOL2d.apply(x, kernel_size, stride)
kernel_size = _pair(kernel_size)
if stride is None:
stride = kernel_size
else:
stride = _pair(stride)
# Get input sizes
_, c, h, w = x.size()
# Create per-element exponential value sum : Tensor [b x 1 x h x w]
e_x = torch.sum(torch.exp(x),dim=1,keepdim=True)
# Apply mask to input and pool and calculate the exponential sum
# Tensor: [b x c x h x w] -> [b x c x h' x w']
return F.avg_pool2d(x.mul(e_x), kernel_size, stride=stride).mul_(sum(kernel_size)).div_(F.avg_pool2d(e_x, kernel_size, stride=stride).mul_(sum(kernel_size)))
论文 https://arxiv.org/abs/2101.00440
项目地址 https://github.com/alexandrosstergiou/SoftPool
(2) 重叠池化
相对于传统的no-overlapping pooling,采用Overlapping Pooling不仅可以提升预测精度,同时一定程度上可以减缓过拟合。
相比于正常池化(步长s=2,窗口z=2) 重叠池化(步长s=2,窗口z=3) 可以减少top-1, top-5分别为0.4% 和0.3%;重叠池化可以在一定程度避免过拟合。
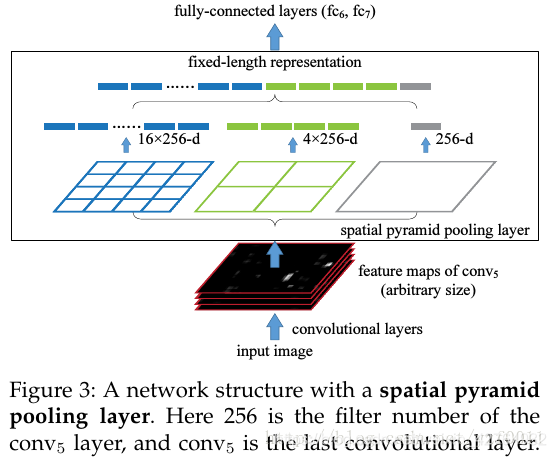
(3)*金字塔池化Spatial Pyramid Pooling
在一般的CNN结构中,在卷积层后面通常连接着全连接。而全连接层的特征数是固定的,所以在网络输入的时候,会固定输入的大小(fixed-size)。但在现实中,我们的输入的图像尺寸总是不能满足输入时要求的大小。然而通常的手法就是裁剪(crop)和拉伸(warp)。图像的纵横比(ratio aspect) 和 输入图像的尺寸是被改变的。这样就会扭曲原始的图像。
而SPP利用多尺度pooling然后reshape并拼接,得到固定大小的特征向量
证明
公理: 任何一个数都可以写成若干个数的平方和。
a = a 1 2 + a 2 2 ⋯ a=a_{1}^{2}+a_{2}^{2}\cdots a=a12+a22⋯
先假定固定输入图像的尺寸 s = 224 s=224 s=224, 而此网络卷积层最后输出256层feature-maps, 且每个feature-map大小为 13 × 13 ( a = 13 ) 13×13(a=13) 13×13(a=13),全连接层总共 256 × ( 9 + 4 + 1 ) 256×(9+4+1) 256×(9+4+1)个神经元, 即输全连接层输入大小为 256 × ( 9 + 4 + 1 ) 256×(9+4+1) 256×(9+4+1)。(公理)
即我们需要在每个feature-map的到一个数目为 f = 9 + 4 + 1 f=9+4+1 f=9+4+1的特征。
这里用了3个pooling窗口 w × w w×w w×w, 而对应的pooling stride 为 t t t, 经多这3个窗口pooling池化得到3个 n × n , n = 3 , 2 , 1 n×n,n=3,2,1 n×n,n=3,2,1的结果。
此时,只需要根据feature map 的尺寸与全连接层维数分解得到的3个n,计算pooling的窗口大小 w w w以及stride t t t即可。
w = ⌈ a / n ⌉ t = ⌊ a / n ⌋ \begin{matrix}w=⌈a/n⌉\\\\ t=⌊a/n⌋\\ \end{matrix} w=⌈a/n⌉t=⌊a/n⌋

SPP 显著特点
-
不管输入尺寸是怎样,SPP 可以产生固定大小的输出
-
使用多个窗口(pooling window)
-
SPP 可以使用同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征。
-
由于对输入图像的不同纵横比和不同尺寸,SPP同样可以处理,所以提高了图像的尺度不变(scale-invariance)和降低了过拟合(over-fitting)
-
实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛(convergence)
-
SPP 对于特定的CNN网络设计和结构是独立的。(也就是说,只要把SPP放在最后一层卷积层后面,对网络的结构是没有影响的, 它只是替换了原来的pooling层)
-
不仅可以用于图像分类而且可以用来目标检测
-
多窗口的pooling会提高实验的准确率
-
输入同一图像的不同尺寸,会提高实验准确率(从尺度空间来看,提高了尺度不变性(scale invariance))
-
用了多View(multi-view)来测试,也提高了测试结果
-
图像输入的尺寸对实验的结果是有影响的(因为目标特征区域有大有有小)
-
因为我们替代的是网络的Poooling层,对整个网络结构没有影响,所以可以使得整个网络可以正常训练。
from math import floor, ceil
import torch
import torch.nn as nn
import torch.nn.functional as F
class SpatialPyramidPooling2d(nn.Module):
r"""apply spatial pyramid pooling over a 4d input(a mini-batch of 2d inputs
with additional channel dimension) as described in the paper
'Spatial Pyramid Pooling in deep convolutional Networks for visual recognition'
Args:
num_level:
pool_type: max_pool, avg_pool, Default:max_pool
By the way, the target output size is num_grid:
num_grid = 0
for i in range num_level:
num_grid += (i + 1) * (i + 1)
num_grid = num_grid * channels # channels is the channel dimension of input data
examples:
>>> input = torch.randn((1,3,32,32), dtype=torch.float32)
>>> net = torch.nn.Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=3,stride=1),\
nn.ReLU(),\
SpatialPyramidPooling2d(num_level=2,pool_type='avg_pool'),\
nn.Linear(32 * (1*1 + 2*2), 10))
>>> output = net(input)
"""
def __init__(self, num_level, pool_type='max_pool'):
super(SpatialPyramidPooling2d, self).__init__()
self.num_level = num_level
self.pool_type = pool_type
def forward(self, x):
N, C, H, W = x.size()
for i in range(self.num_level):
level = i + 1
kernel_size = (ceil(H / level), ceil(W / level))
stride = (ceil(H / level), ceil(W / level))
padding = (floor((kernel_size[0] * level - H + 1) / 2), floor((kernel_size[1] * level - W + 1) / 2))
if self.pool_type == 'max_pool':
tensor = (F.max_pool2d(x, kernel_size=kernel_size, stride=stride, padding=padding)).view(N, -1)
else:
tensor = (F.avg_pool2d(x, kernel_size=kernel_size, stride=stride, padding=padding)).view(N, -1)
if i == 0:
res = tensor
else:
res = torch.cat((res, tensor), 1)
return res
def __repr__(self):
return self.__class__.__name__ + '(' \
+ 'num_level = ' + str(self.num_level) \
+ ', pool_type = ' + str(self.pool_type) + ')'
https://www.cnblogs.com/qinduanyinghua/p/9016235.html
https://blog.csdn.net/yzf0011/article/details/75212513
https://zhuanlan.zhihu.com/p/343481363?utm_source=wechat_session&utm_medium=social&utm_oi=1054735681825386496&utm_campaign=shareopn